A technology has been introduced that allows you to create high-quality animation from just one image, and you can freely add choreography to it with just one humanoid illustration or photo.

Alibaba's research team has published a paper on a technology that animates the original image according to the motion data by inputting the original image data and 'motion' data. By using this technology, named 'Animate Anyone,' it is possible to generate high-quality animations with less flickering.
Animate Anyone
You can check the quality of the animation generated in the movie below.
Animate Anyone: Consistent and Controllable Image-to-Video Synthesis for Character Animation - YouTube
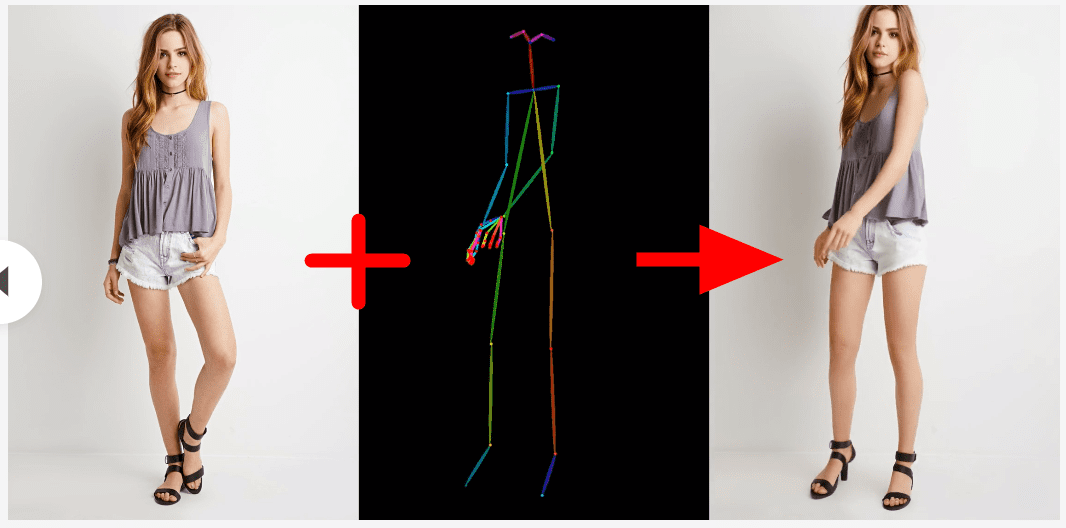
'Animate Anyone', which has appeared this time, is based on a single 'original image' like the one shown on the left end of the figure below, and by inputting the 'action' data in the center, the person in the image moves according to the action data as shown on the right end. It is a technology that can
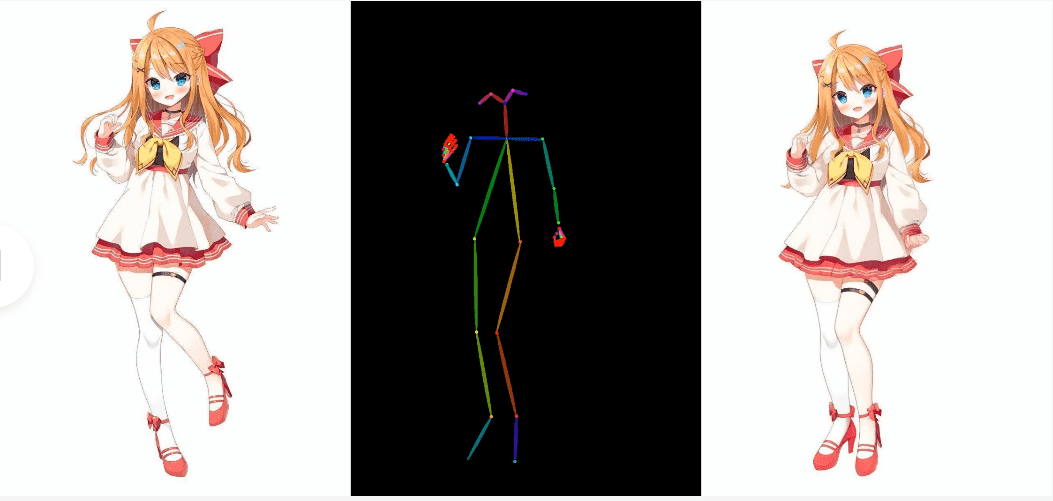
In addition to photos, it is also possible to create animations from illustrations.

The quality of the animation is quite high, with the hair swaying along with the movements.
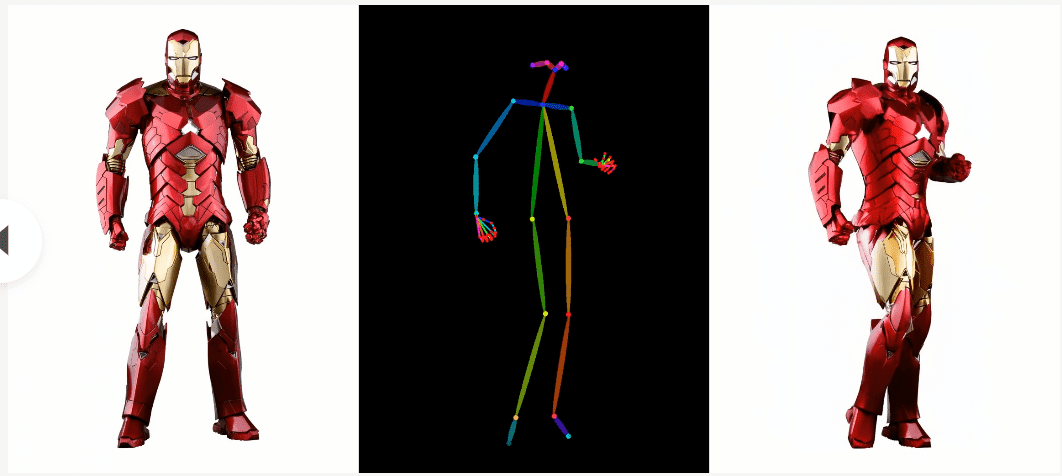
An example of animating a 3DCG-like image is also posted, and the original image seems to be anything as long as it looks human-like.
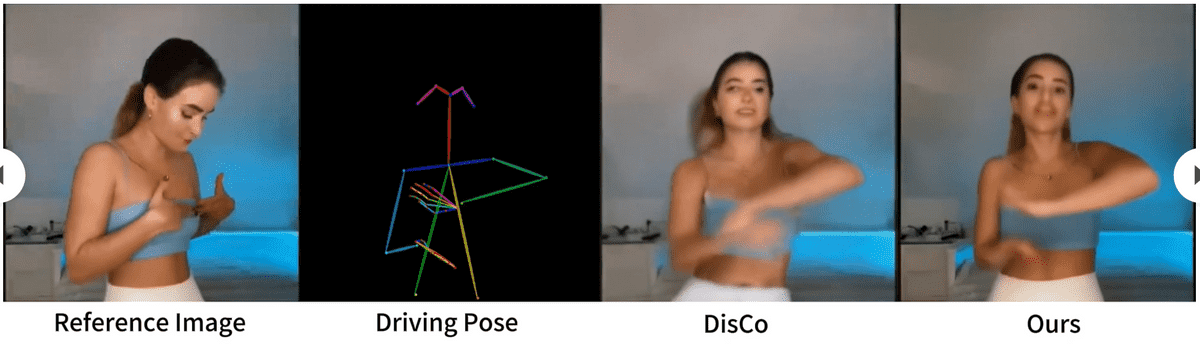
Compared to conventional methods, Animate Anyone is superior in that it can maintain detailed image data such as clothing patterns, and it can significantly reduce flickering.

Even when 'motion' data of intense movements such as dance is input, there is almost no flickering with Animate Anyone, and the animation was likely to be believed even if it was said to be a movie that was actually shot.
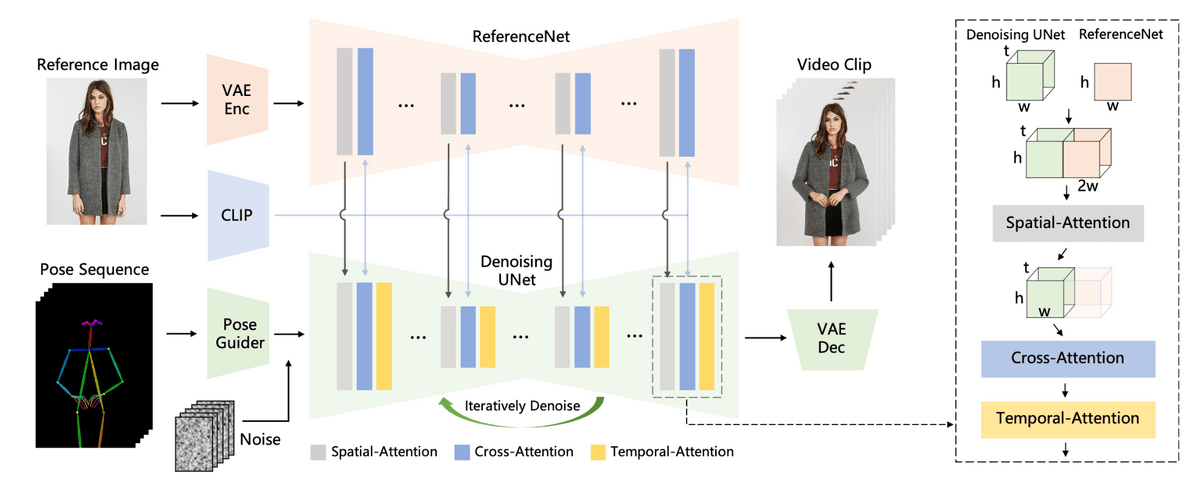
At the time of writing, the code and weights have not yet been published, but you can check the structure of the model in the paper. Detailed features for spatial attention are extracted from the original image through ``ReferenceNet,'' and at the same time,
Related Posts:







