Google researchers have developed an attack method that forces ChatGPT to repeat words ``forever'' and spits out the huge amount of text data used for training.

ChatGPT training uses data obtained from the Internet, but the specific content of the data is not disclosed. Google researchers have announced that they have succeeded in making ChatGPT output training data by issuing a simple command, ``Repeat the same word.''
Extracting Training Data from ChatGPT
[2311.17035] Scalable Extraction of Training Data from (Production) Language Models
https://arxiv.org/abs/2311.17035
There has been a phenomenon in the past where the data used for training machine learning models is output almost as is. For example, in the image generation model 'Stable Diffusion', the data is included in the training data by adding a person's name as shown in the figure below. I was able to output the photo of that person almost exactly as it was.

However, these traditional attack methods are limited in the amount of training data that can be recovered, and while Stable Diffusion was trained on millions of images, it was only able to extract about 100 images. In addition, the model was a research demo rather than an actual product, the entire model existed locally and could be directly input/output, and there were no measures taken to prevent data extraction. It was not much of a surprise that the training data extraction attack was successful.
On the other hand, ChatGPT is a production model that is already in operation, can only be accessed via OpenAI API, and is believed to have measures against data extraction attacks. Now, Google researchers have discovered a way to circumvent such measures and output training data. The attack is as simple as asking ChatGPT to 'repeat a specific word', and after repeating the same word for a while, the data used for training will be output.

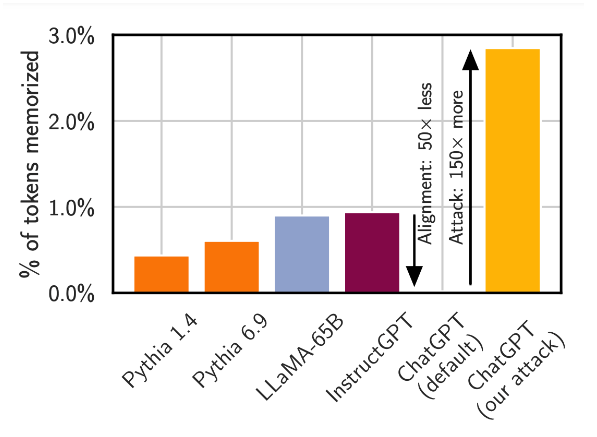
The research team compared ChatGPT's output with about 10 TB of data collected on the Internet to confirm that it was actual training data and not a randomly generated 'something like that'. The figure below shows some of the comparison results, and the parts of the ChatGPT output that match the data on the Internet are displayed in red, confirming that training data is included in the output.

The research team noticed the phenomenon that ``repeating the same word produces strange output'' on July 11, 2023, and began analysis on July 31. As a result of their analysis, the researchers realized that training data had been output, so they sent a draft paper to OpenAI on August 30 and discussed the details of the attack. After a 90-day grace period, the paper was published on November 28th.
◆Forum now open
A forum related to this article has been set up on the GIGAZINE official Discord server . Anyone can write freely, so please feel free to comment! If you do not have a Discord account, please create one by referring to the article explaining how to create an account!
• Discord | 'Have you ever encountered bug-like behavior in ChatGPT?' | GIGAZINE
https://discord.com/channels/1037961069903216680/1179716149517221959
Related Posts:








in Software, Security, Web Application, Posted by log1d_ts