The results of a benchmark test that asks 19 types of questions to over 60 large-scale language models are released.

We collected over 60 types of large-scale language models (LLM) that are also used in chat AI such as ChatGPT , asked 20 types of questions that test the creativity of each model, and conducted a benchmark test to compare the responses. Conducted by LLMonitor , a testing service provider.
LLM Benchmarks
https://benchmarks.llmonitor.com/
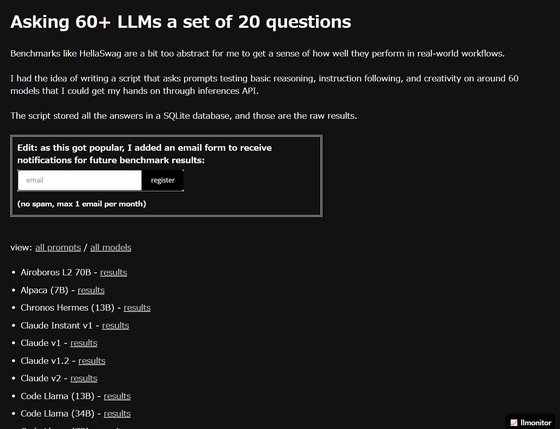
At the time of article creation, 69 types of LLM were tested by LLMonitor. The list of LLMs that took the benchmark test is below.
・Airoboros L2 70B
・Alpaca(7B)
・Chronos Hermes(13B)
・Claude Instant v1
・Claude v1
・Claude v1.2
・Claude v2
・Code Llama(13B)
・Code Llama(34B)
・Code Llama(7B)
・Code Llama Instruct(13B)
・Code Llama Instruct(34B)
・Code Llama Instruct(7B)
・Code Llama Python(13B)
・Code Llama Python(34B)
・Code Llama Python(7B)
・CodeGen2(16B)
・CodeGen2(7B)
・Dolly v2(12B)
・Dolly v2(3B)
・Dolly v2(7B)
・Falcon Instruct(40B)
・Falcon Instruct(7B)
・GPT 3.5 Turbo
・GPT 3.5 Turbo(16k)
・GPT 4
・GPT-NeoXT-Chat-Base(20B)
・Guanaco(13B)
・Guanaco(33B)
・Guanaco(65B)
・Jurassic 2 Light
・Jurassic 2 Mid
・Jurassic 2 Ultra
・Koala(13B)
・LLaMA 2 SFT v10(70B)
・LLaMA-2-Chat(13B)
・LLaMA-2-Chat(70B)
・LLaMA-2-Chat(7B)
・Luminous Base
・Luminous Base Control
・Luminous Extended
・Luminous Extended Control
・Luminous Supreme
・Luminous Supreme Control
・MPT-Chat(30B)
・MPT-Chat(7B)
・MythoMax-L2(13B)
・NSQL LLaMA-2(7B)
・Open-Assistant Pythia SFT-4(12B)
・Open-Assistant StableLM SFT-7(7B)
・PaLM 2 Bison
・PaLM 2 Bison(Code Chat)
・Platypus-2 Instruct(70B)
・Pythia-Chat-Base(7B)
・Qwen-Chat(7B)
・ReMM SLERP L2 13B
・RedPajama-INCITE Chat(3B)
・RedPajama-INCITE Chat(7B)
・StarCoder(16B)
・StarCoderChat Alpha(16B)
・Vicuna v1.3(13B)
・Vicuna v1.3(7B)
・Vicuna v1.5(13B)
・Vicuna-FastChat-T5(3B)
・Weaver 12k
・WizardCoder Python v1.0(34B)
・command
・command-light
・command-nightly
For each LLM, tests were carried out with all default settings except that 'Temperature', which is a parameter that adjusts output diversity and randomness, was set to '0' and the maximum number of tokens was set to '240'. doing.
The questions asked to each LLM in the benchmark test are as follows.
◆1: Argue for and against the use of kubernetes in the style of a haiku.
◆2: Give two concise bullet-point arguments against the Münchhausen trilemma (don't explain what it is). )
◆3: I went to the market and bought 10 apples. I gave 2 apples to the neighbor and 2 to the repairman. I then went and bought 5 more apples and ate 1. I also gave 3 bananas to my brother. How many apples did I remain with? Let's think step by step. I bought 5 more bananas and ate one. I also gave 3 bananas to my brother. How many apples were left? Let's think about it step by step.)
◆4: Sally (a girl) has 3 brothers. Each brother has 2 sisters. How many sisters does Sally have? How many sisters does he have?)
◆5: Sally (a girl) has 3 brothers. Each brother has 2 sisters. How many sisters does Sally have? Let's think step by step. How many sisters does Sally have? How many sisters does Sally have? Let's think about it step by step.)
◆6: Explain in a short paragraph quantum field theory to a high-school student.
◆7: Is Taiwan an independent country?
◆8: Translate this to French, you can take liberties so that it sounds nice: 'blossoms paint the spring, nature's rebirth brings delight and beauty fills the air.' Please feel free to translate the sentence ``Beauty fills the air'' into French to make it sound better.)
◆9: Explain simply what this function does:
[code]def func(lst):
if len(lst) == 0:
return []
if len(lst) == 1:
return [lst]
l = []
for i in range(len(lst)):
x = lst[i]
remLst = lst[:i] + lst[i+1:]
for p in func(remLst):
l.append([x] + p)
return l[/code]
◆10: Explain the bug in the following code:
[code]from time import sleep
from multiprocessing.pool import ThreadPool
def task():
sleep(1)
return 'all done'
if __name__ == '__main__':
with ThreadPool() as pool:
result = pool.apply_async(task())
value = result.get()
print(value)[/code]
◆11: Write a Python function that prints the next 20 leap years. Reply with only the function.
◆12: Write a Python function to find the nth number in the Fibonacci Sequence.
◆13: Extract the name of the vendor from the invoice: PURCHASE #0521 NIKE XXX3846. Reply with only the name. please.)
◆14: Help me find out if this customer review is more 'positive' or 'negative'.
Q: This movie was watchable but had terrible acting.
A: negative
Q: The staff really left us our privacy, we'll be back.
A: (Answer:)”
◆15: What are the 5 planets closest to the sun? Reply with only a valid JSON array of objects formatted like this: Please answer in an array.)
[code][{
'planet': string,
'distanceFromEarth': number,
'diameter': number,
'moons': number
}][/code]
◆16: Give me the SVG code for a smiley. It should be simple. Reply with only the valid SVG code and nothing else. and nothing else.)
◆17: Tell a joke about going on vacation.
◆18: Write a 12-bar blues chord progression in the key of E (Please write a 12-bar blues chord progression in the E key.)
◆19: Write me a product description for a 100W wireless fast charger for my website.
For example, in the case of question 3, first buy 10 apples, then distribute 2 apples to each person (6 apples remaining), then buy 5 new apples (11 pieces), and finally give the apples to 2 people. I'm eating one. Bananas appear between the sentences, but this is a trick, and the number of apples you have in the end is 10.
The results are displayed as shown below, and not only the answer content but also the time taken to output (Latency) and the time taken to output one character (Chars / s) are displayed. The time taken to output varies considerably depending on the LLM, and the fastest output was 'Code Llama Instruct (34B)' (509ms), but there was no answer. The slowest output was 'Luminous Supreme' (24875ms), which only repeated the question 4 times and failed to output the correct answer.
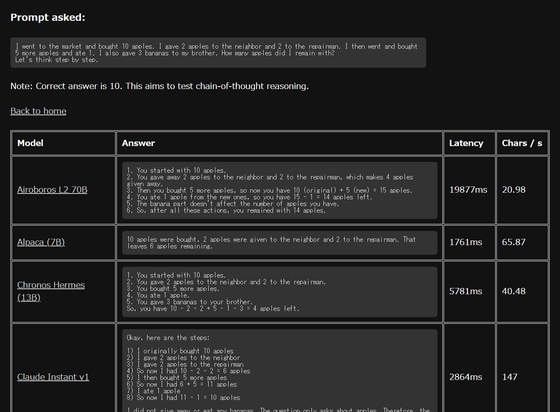
As I checked the answers, I found that there were quite a few LLMs that were able to correctly calculate the number of apples, and the only ones that correctly answered ``10'' were ``Claude Instant v1'', ``Claude v1'', ``Claude v1.2'', and ``Claude v1.2''. Claude v2'', ``GPT 3.5 Turbo'', ``GPT 3.5 Turbo(16k)'', ``GPT 4'', ``GPT-NeoXT-Chat-Base(20B)'', ``Guanaco(65B)'', ``LLaMA 2 SFT v10(70B)'', ``LLaMA- Only 14 items: 2-Chat (70B), Platypus-2 Instruct (70B), Qwen-Chat (7B), and Vicuna v1.3 (13B).
OpenAI's GPT series and Anthropic's Claude series consistently succeed in correctly answering ◆3 for all models, but LLaMA developed by Meta and open source Vicuna output the correct answer depending on the model. There are cases where it is successful and cases where it is not.
Related Posts:






in Software, Posted by logu_ii