What is 'grocking'? The secret to dramatically improving generative AI performance.

OpenAI, an AI research group developing excellent AI models such as ChatGPT, has discovered one of the most fascinating mysteries in deep learning, '
[2301.05217] Progress measures for grokking via mechanical interpretability
https://arxiv.org/abs/2301.05217
A Mechanistic Interpretability Analysis of Grokking - AI Alignment Forum
https://www.alignmentforum.org/posts/N6WM6hs7RQMKDhYjB/a-mechanistic-interpretability-analysis-of-grokking
Neural networks often exhibit new behaviors when scaling up parameters, training data, training steps, etc. One approach to understanding this is to find a measure of continuous progress that underlies seemingly discontinuous qualitative changes.
Neil Nanda and his colleagues at Google DeepMind , a Google-affiliated AI research company, believe that this 'measure of progress' can be found by reverse engineering learned behaviors into their individual components. They are investigating a phenomenon called 'grocking' discovered by the AI research group OpenAI.
I've spent the past few months exploring @OpenAI 's grokking result through the lens of mechanical interpretability. I fully reverse engineered the modular addition model, and looked at what it does when training. So what's up with grokking? A 🧵... (1/17) https://t.co/AutzPTjz6g
— Neel Nanda (@NeelNanda5) August 15, 2022
Regarding the phenomenon of 'grocking' discovered by OpenAI, the research team explained, 'Small AI models trained to perform simple tasks like modular addition initially record the training data, but over time, they suddenly begin to generalize to unseen data.' Generalization refers to the state of 'applying the information gained from training to answer new questions.'
The researchers pointed out that groking is closely related to phase shifts, which are sudden changes in a model's performance on a certain skill during training, a common phenomenon that occurs when training models.
The graph below shows the number of training iterations (horizontal axis) and the number of errors (vertical axis) of the model's output when repeated training was continued on a 'small AI model trained to perform modular addition.' You can see that the number of errors dropped sharply before the number of training iterations reached 1,000, indicating a significant change.
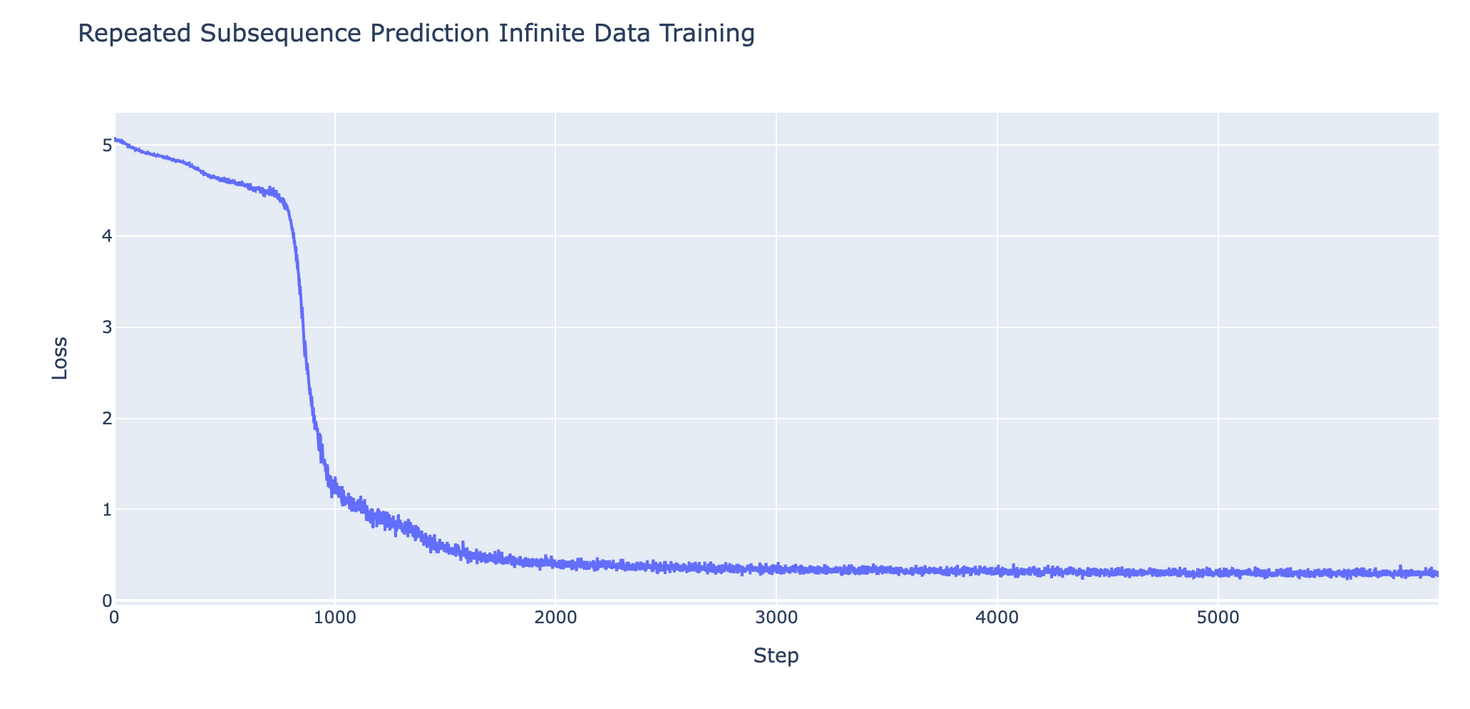
Furthermore, the researchers point out that if enough regularized data is added to enable generalization, this change will manifest as grogginess.
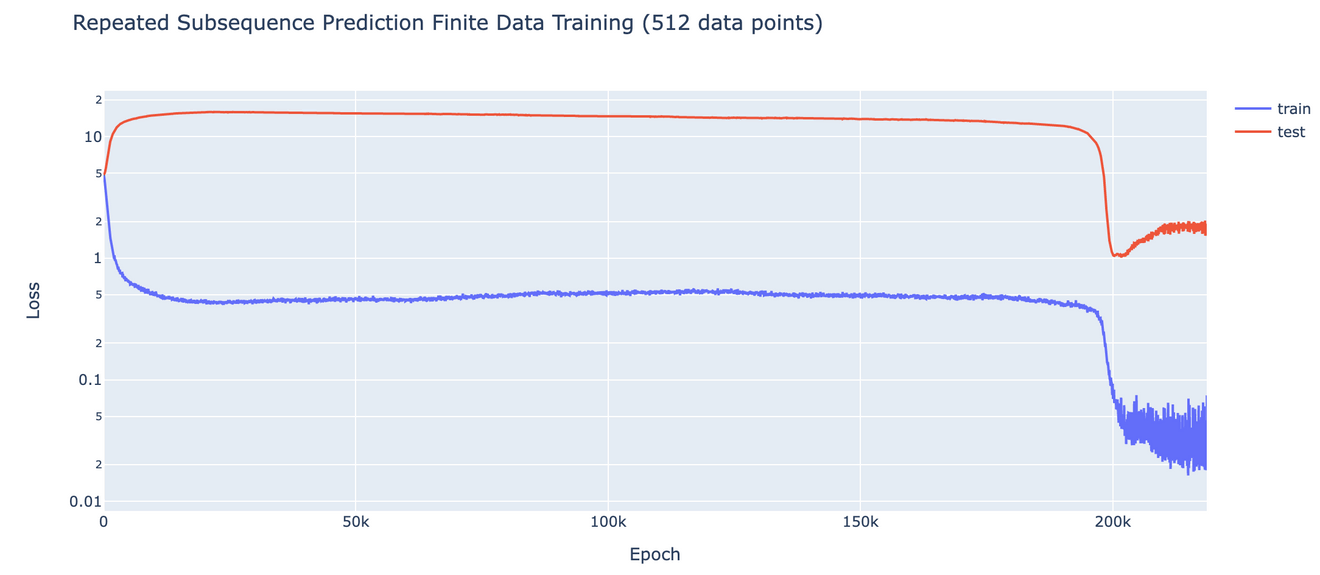
The phase shift occurs because it's 'difficult' for the model to come up with a general solution, Nanda said.
The researchers believe that the reason it takes the model so long to reach the phase change is because of some training error, but because it's so easy to just record an event, the model records the training content first.
The model processes the data slowly interpolating from record to generalization until a phase shift occurs, reducing errors. Once the interpolation from record to generalization is complete, the output changes dramatically, resulting in a phase shift.
Based on this, Nanda said, 'Although we don't fully understand phase change, I would argue that we can replace confusion about groking with confusion about phase change!'
I don't claim to fully understand phase changes, but I DO claim to have reduced my confusion about grokking to my confusion about phase changes! (6/17)
— Neel Nanda (@NeelNanda5) August 15, 2022
The research team went on to explain more specifically that 'grooking is observed when regularization is performed to select the amount of data that gives a slight advantage to the 'generalized solution' over the 'recorded solution',' and that there is a deep relationship between grooking and phase changes.
The research team used a small AI model to analyze the groking, but explained that a larger model would not be able to detect this phase change, but a small AI model could notice this strange change.
The research team stated, 'One of the core claims of mechanistic interpretability is that neural networks are understandable, that they are not mysterious black boxes, but that they learn interpretable algorithms that can be reverse-engineered and understood.' They explained that this study was intended to prove the concept.
The research team has summarized the technical details and discussions of this analysis on the following page.
A Mechanistic Interpretability Analysis of Grokking (Stable) - Colaboratory
https://colab.research.google.com/drive/1F6_1_cWXE5M7WocUcpQWp3v8z4b1jL20
Related Posts: