How to perform 'web scraping' to automatically acquire website information with JavaScript

Web
Web scraping with JS | Analog Forest
https://qoob.cc/web-scraping/
As a group of web scraping tools, Python 3 is often used as a programming language, the Requests library is often used to acquire HTML, and Beautiful Soup is often used to analyze HTML. However, Prokudin points out that the scraping method using this group of tools has not changed since several years ago, and that it is expensive to use for JavaScript engineers. Prokudin says he wants to put in place documentation for anyone who wants to do web scraping with JavaScript.
◆ Check the data in advance
Prokudin advises that you should first check 'whether web scraping is necessary' before doing web scraping. Since modern web applications often dynamically generate structured data instead of writing the data directly in HTML, it is often possible to retrieve the data without web scraping in the first place. That is.
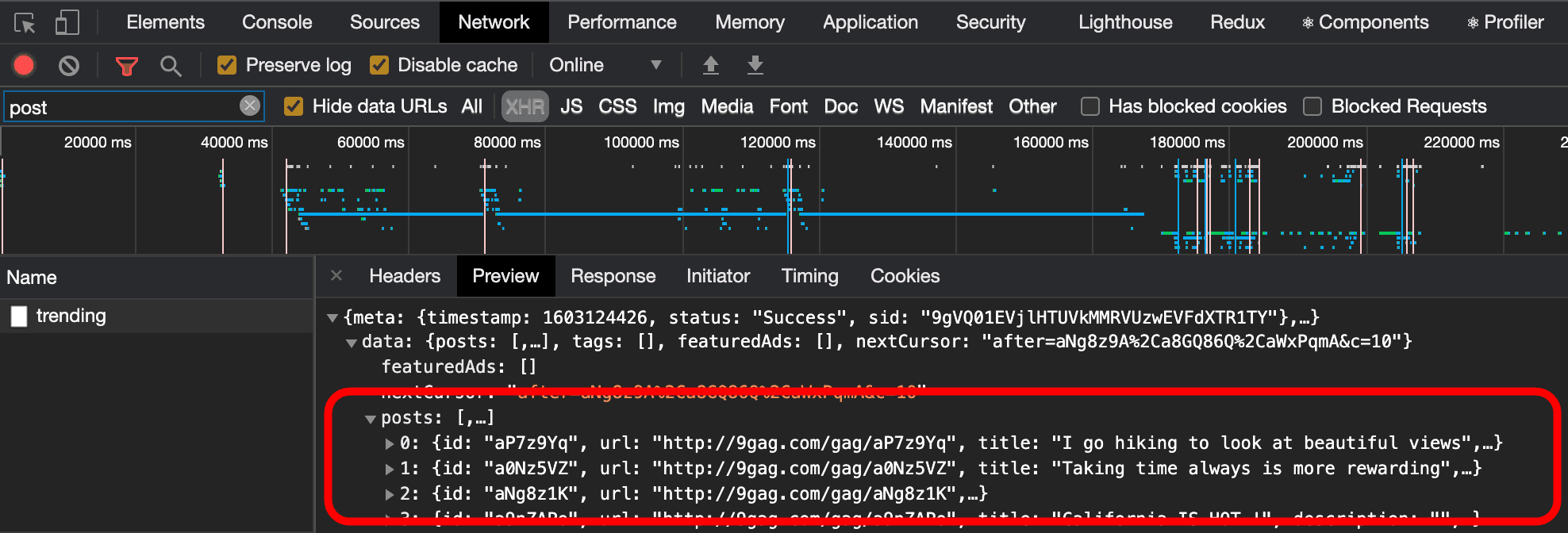
◆ Get data
If you need web scraping, first get the HTML data itself from your website. It is possible to use the
I 'm getting the HTML of the page about Lionel Messi from ' Transfermarkt '.
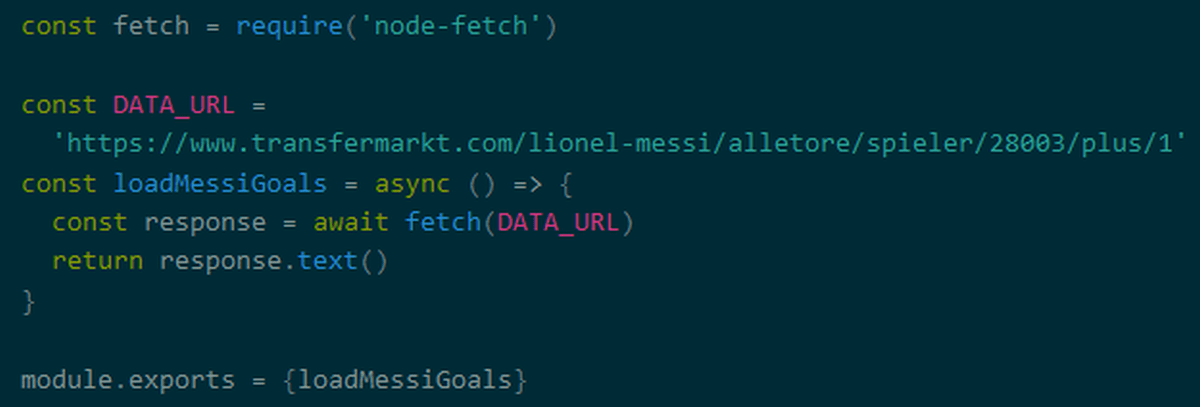
◆ Analyze the data
Tools that analyze the acquired HTML include

Create a

◆ Process data
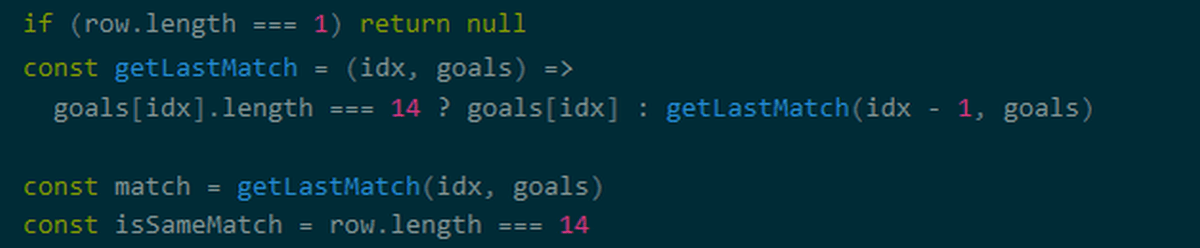
Since the acquired array contains unnecessary information, it is said that processing will be performed so that only the necessary information remains. Prokudin's sample code gets the line lengths in an array and examines the shape of the data. The array obtained by this sample code has four rows with lengths of 1, 5, 14, and 15.
Processing is added according to the line length. Lines with a length of 15 are separated into the 5th value from the beginning and the 6th and subsequent values.

In addition, Prokudin's code excludes lines with a length of 1.
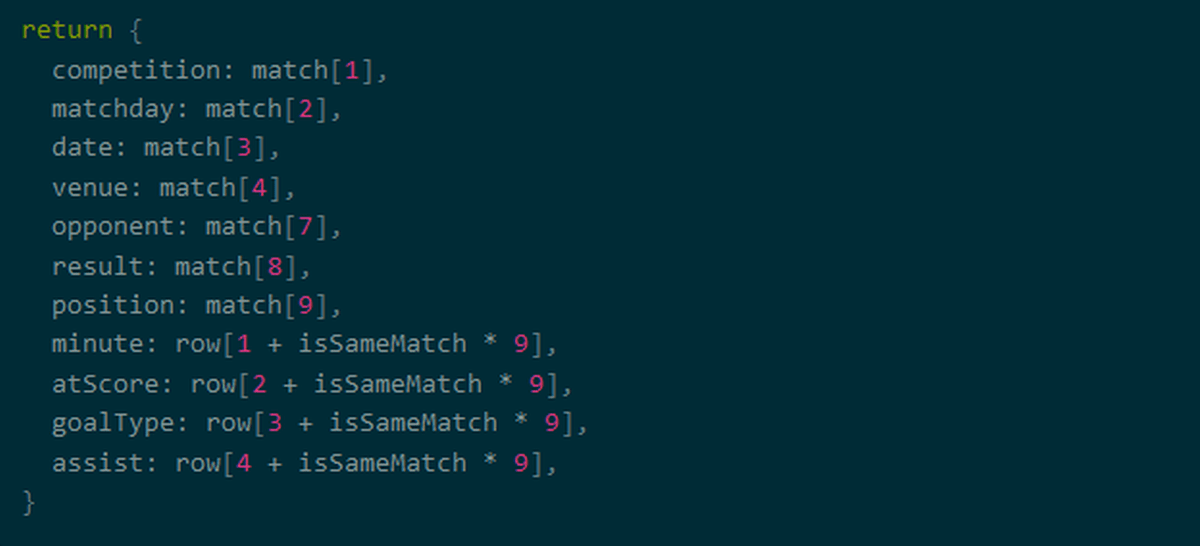
Finally, if you map the values in the array, the data processing is complete.
◆ Save data
All you have to do is save the processed data. Now you can web scrape without using Python.

All the sample code Prokudin used for the tutorial is available on CodeSandbox .
Related Posts:





in Software, Posted by darkhorse_log