What is the content of 'SRE' that responds to Google's thorough system failure?

For companies that provide services over the Internet, it is important to deal with system failures. Google, which provides various services such as search engine, cloud, email, advertising, etc., shows actual examples of how it responds to system failures based on its own system management methodology ``
SRE keeps digging to prevent problems | Google Cloud Blog
https://cloud.google.com/blog/products/management-tools/sre-keeps-digging-to-prevent-problems
SRE is site-Reliant ability Engineering stands for, you may also be translated as 'site reliability engineering'. In large companies such as Google, things that rarely occur in other companies can always occur, and complex obstacles that can not occur elsewhere can occur. To address these obstacles, Google's SRE is said to be excellent at building systems to track failures across the many layers of its infrastructure.
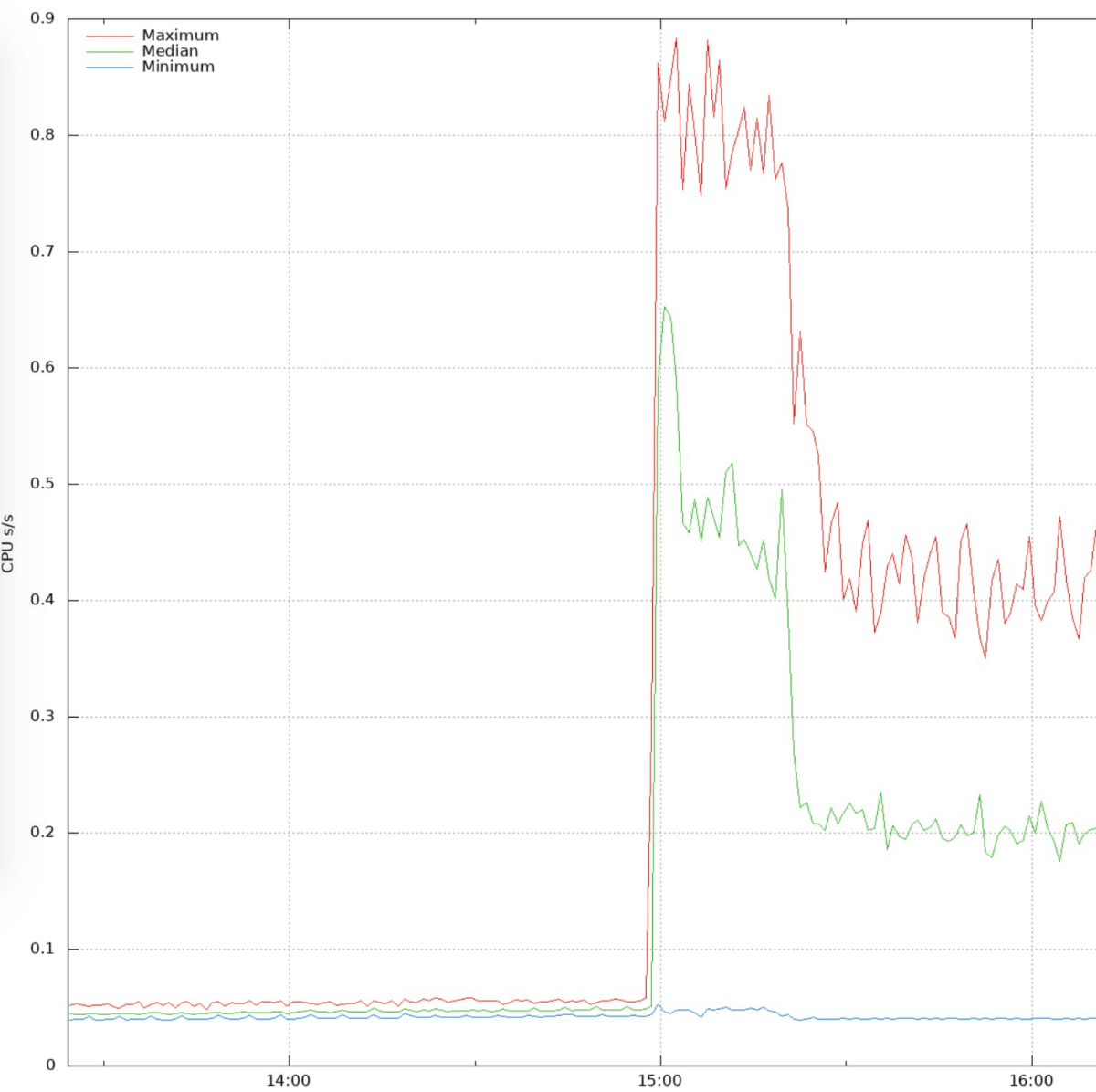
In the Google Cloud Blog, you can see how Google SRE works. If the SRE team responsible for Google traffic and load balancing detected an unusual number of errors in the edge network , the team first removed the errored machines from the service to reduce the impact of the failure. Separation. This separation can be done quickly because Google has sufficient processing power and redundancy in the entire system, which seems to be one of the important elements of SRE.
The team had the know-how that these errors were due to transient network anomalies, and when investigating the network, they found that a server rack was experiencing packet loss. Further investigation revealed that routers were experiencing BGP route flapping . Having determined that route flapping was more indicative of a machine failure than the router itself, the team decided to look at the server machine's system log.

As a result of referring to the log, it turned out that the CPU temperature of the machine announcing the IP address by BGP was high and the CPU usage rate was abnormally high. Other adjacent machines were also checked, but no abnormalities were detected.
When no thermal runaway was detected on the adjacent machine, the SRE team reported a problem to the team managing and operating the company's hardware, and requested that the server machine be repaired. The hardware team investigated and found that one of the casters supporting the rack was damaged.

The flow of the coolant for cooling the CPU was stagnant because the entire rack was tilted due to the damage of the casters. As a result, the CPU could not cool down properly, causing the CPU to run out of heat.

The hardware team fixed the casters immediately, but the problem doesn't end here. You need to consider why it happened and how to prevent it. The hardware team has repair kits available everywhere the server machine is located, rethinks the process of moving the racks without damaging the casters, and improves how the racks move when new racks are delivered to the data center. Was.
After taking thorough measures to prevent failures, he reportedly traced the problem from the external front-end system to the hardware. Such troubleshooting is created by having clear communication within the team, sharing goals, not only fixing problems, but also awareness of `` preventing future failures '' as a whole team .

SRE teams often use the phrase 'all obstacles should be inexperienced.' This example is a good example of finding the root cause and preventing a reoccurrence after Google has alleviated the initial symptoms of the disability, and that it underlies the SRE for managing the system. Has been stated.
Related Posts:







in Web Service, Posted by darkhorse_log