Anthropic announces Claude Opus 4.8, an upgrade from Opus 4.7 that delivers improved coding performance and integrity.

Anthropic has announced Claude Opus 4.8 , an upgraded version of
Introducing Claude Opus 4.8 \ Anthropic
https://www.anthropic.com/news/claude-opus-4-8
Claude Opus 4.8 System Card
(PDF file) https://cdn.sanity.io/files/4zrzovbb/website/c886650a2e96fc0925c805a1a7ca77314ccbf4a6.pdf
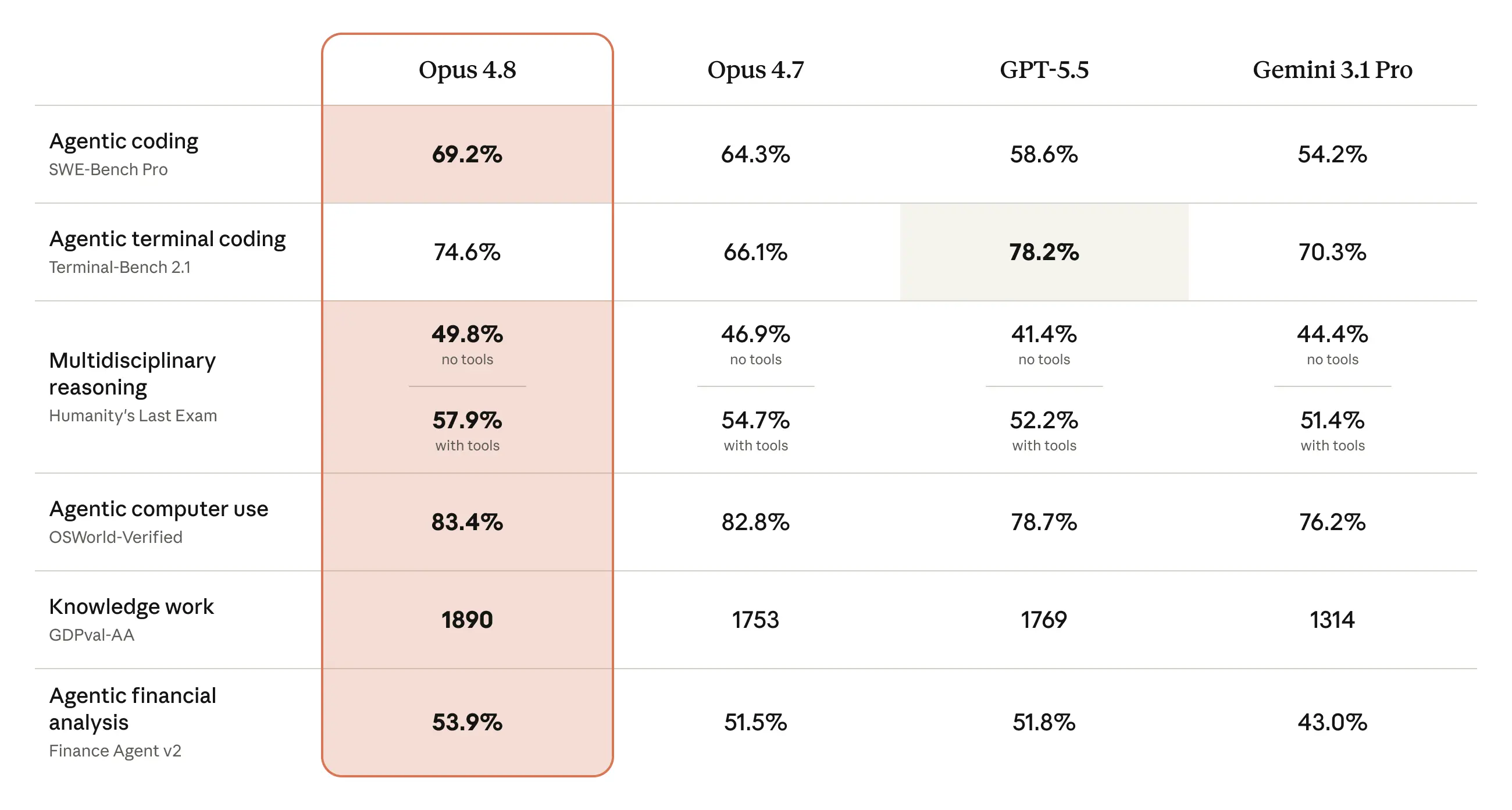
According to Anthropic, Claude Opus 4.8 is a model based on Opus 4.7 with improvements across various benchmarks, designed as a 'more effective collaborator.' In terms of performance, Opus 4.8 recorded 69.2% in SWE-Bench Pro, surpassing Opus 4.7's 64.3%, GPT-5.5's 58.6%, and Gemini 3.1 Pro's 54.2%. On the other hand, in Terminal-Bench 2.1, Opus 4.8 scored 74.6%, while GPT-5.5 scored 78.2%, indicating that GPT-5.5 outperformed in on-device coding tasks.
Furthermore, Opus 4.8 achieved scores of 49.8% in Humanity's Last Exam, 57.9% in DRACO, 83.4% in OSWorld-Verified, 1890 in GPQA-AA, and 53.9% in Finance Agent v2. All of these scores surpass those of Opus 4.7, demonstrating improvements particularly in practical knowledge tasks and agent-based tasks.
Initial testers have rated Opus 4.8 as 'more reliable and with sharper judgment' when performing agent-like tasks. One tester commented that it 'tends to ask the right questions before making complex changes in Claude Code, find its own mistakes, and challenge uncertain plans.'
One of the biggest improvements this time around is 'honesty.' Anthropic explains that 'Opus 4.8 makes it easier to identify uncertainties during development, makes it harder to make unsubstantiated claims, and reduces the tendency to overlook flaws in the code you've written to about a quarter of what it was in the previous generation model.'
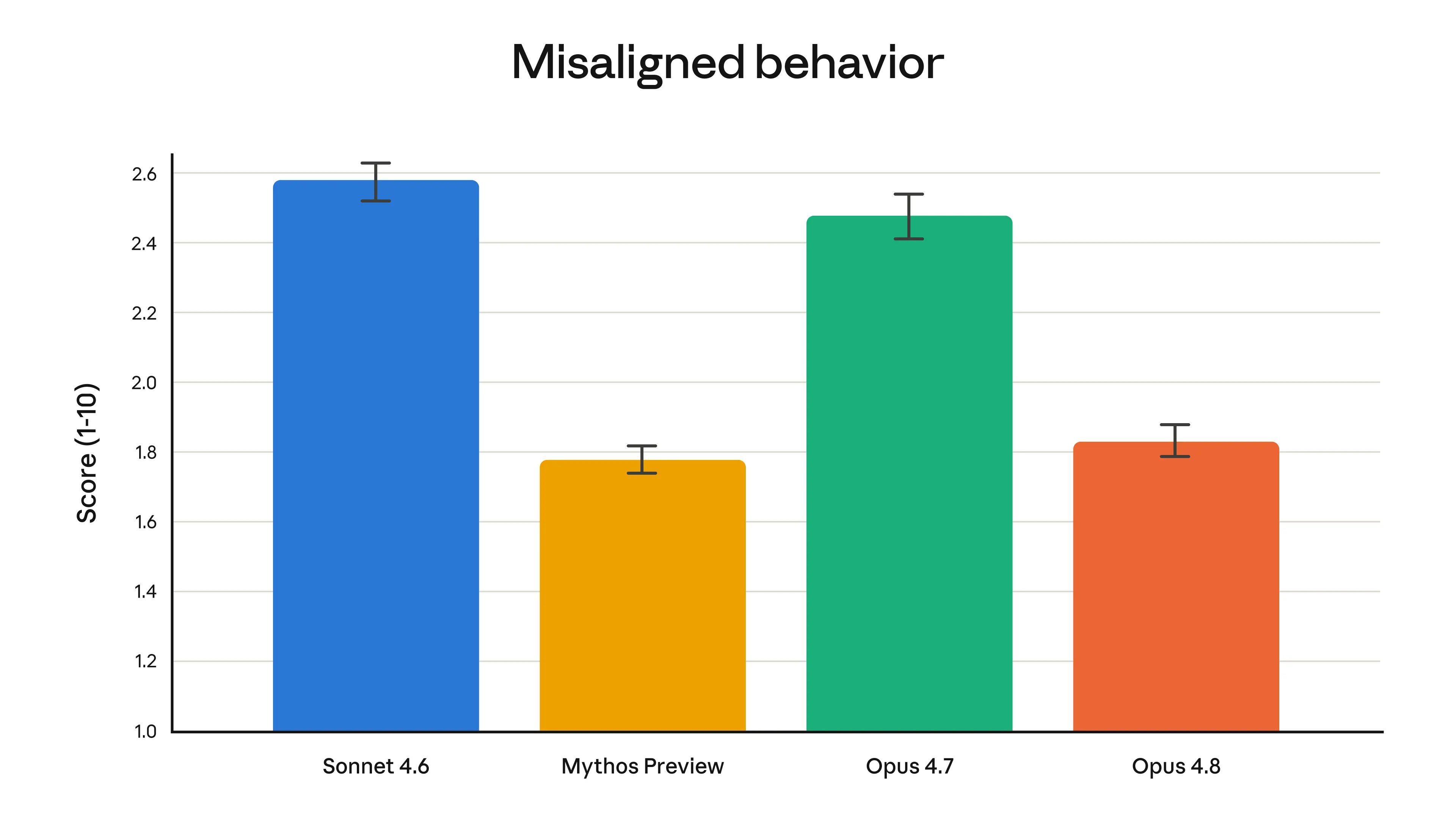
In the safety evaluation, Opus 4.8 received high marks for its 'prosocial' characteristics, such as respecting user autonomy and acting in the user's best interest. Furthermore, it exhibited fewer inconsistent behaviors, such as deception and complicity in abuse, than Opus 4.7, and was at a level close to Claude Mythos Preview , which Anthropic considers to be the most consistent model.
However, while Opus 4.8 outperformed Opus 4.7 in almost all performance evaluations, it fell short of Anthropic's highest-performing model, Claude Mythos Preview, and was reported to be slightly less robust than Opus 4.7 in some agent environments, such as prompt injection.
Along with Claude Opus 4.8, Anthropic is also introducing 'dynamic workflows' for Claude Code as a research preview. These dynamic workflows allow Claude to plan its work, run hundreds of parallel subagents within a single session, perform tasks like large-scale codebase migrations, and then verify the results.
Furthermore, 'effort control' has been added to Claude.ai and Claude Cowork. This feature allows users to adjust how deeply Claude thinks about an answer. Lower settings result in faster response times and less rate limit consumption, while higher settings allow for deeper thinking and improved quality.
The following is a demo video showing how Opus 4.8 and Claude Code handle long-running tasks. Opus 4.8's default setting is 'high effort,' which Anthropic considers to be the setting that best balances quality and user experience. For complex tasks or long-running asynchronous workflows, the 'extra' setting, or 'xhigh' in Claude Code, is recommended, and Claude Code also increases the rate limit to accommodate token consumption due to the high effort setting.
Embrace long-running tasks with Opus 4.8 and Claude Code - YouTube
Additionally, developers can now include system entries in the messages array using the Messages API. This allows for updating permissions, token budgets, execution environment context, and other information while the agent is running, without breaking the prompt cache or going through a user turn.
The standard usage fee for Claude Opus 4.8 is the same as Opus 4.7: $5 (approximately 800 yen) per million input tokens and $25 (approximately 4000 yen) per million output tokens. The high-speed mode costs $10 (approximately 1600 yen) per million input tokens and $50 (approximately 8000 yen) per million output tokens, and developers can use 'claude-opus-4-8' from the Claude API.
Related Posts: