Introducing 'DeepSeek-V3.1,' a hybrid model that combines inference and non-inference modes and is faster than DeepSeek-R1

by
DeepSeek, a Chinese AI company, released the open-source model ' DeepSeek-V3.1 ' on August 21, 2025. This model is positioned as the first step towards the era of agents, and is a hybrid model that combines inference and non-inference modes to achieve high speeds.
DeepSeek-V3.1 Release | DeepSeek API Docs
https://api-docs.deepseek.com/news/news250821
Introducing DeepSeek-V3.1: our first step toward the agent era! ????
— DeepSeek (@deepseek_ai) August 21, 2025
???? Hybrid inference: Think & Non-Think — one model, two modes
⚡️ Faster thinking: DeepSeek-V3.1-Think reaches answers in less time vs. DeepSeek-R1-0528
????️ Stronger agent skills: Post-training boosts tool use and…
The main feature of DeepSeek-V3.1 is its hybrid reasoning style, which combines two modes within a single model: a 'Think' mode that performs thinking and a 'Non-Think' mode that does not. Think mode boasts improved thinking speed, generating answers in less time than the previous model, DeepSeek-R1-0528 . Additionally, pre-training has been reported to have strengthened agent skills in using tools and multi-step tasks. This new feature can be tried out by toggling the 'DeepThink' button in chat on the official website.
DeepSeek - Into the Unknown
https://chat.deepseek.com/
The API has also been updated, with 'deepseek-reasoner' now available in Think mode and 'deepseek-chat' in Non-Think mode. Both models support a 128K context length, and also support the Anthropic API format and strict function calling in the beta API. API resources have also been enhanced, providing a smoother user experience.
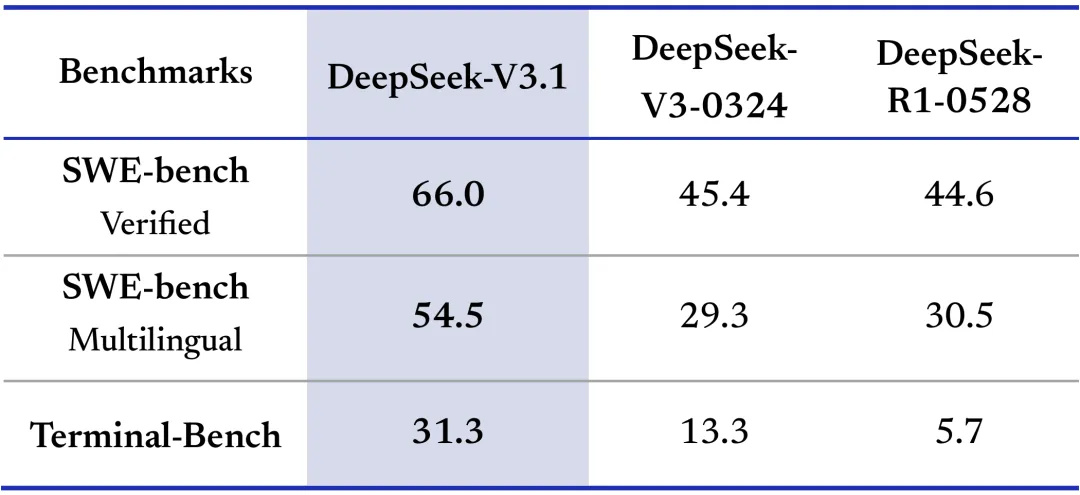
The tools and agents have also been upgraded, achieving better results in benchmarks such as SWE-bench and Terminal-Bench , and the ability to perform multi-step reasoning in complex search tasks has been enhanced, significantly improving thinking efficiency.
In terms of benchmark scores, it achieved a score of 66.0 in SWE-bench Verified , beating DeepSeek-V3-0324's 45.4 and DeepSeek-R1-0528's 44.6. It also achieved a score of 54.5 in SWE-bench Multilingual and 31.3 in Terminal-Bench.
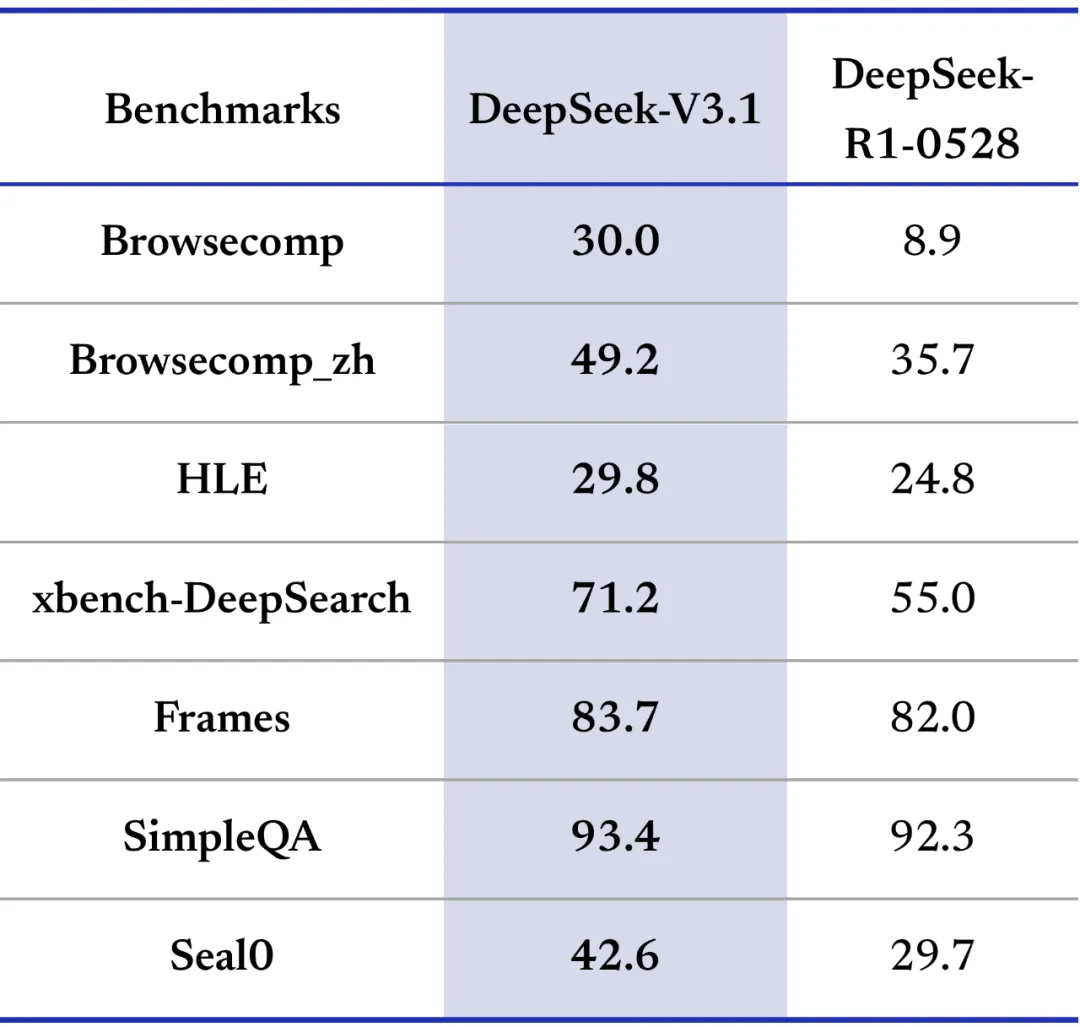
In other benchmarks, it also showed results that exceeded the scores of DeepSeek-R1-0528 in many categories, including 30.0 in
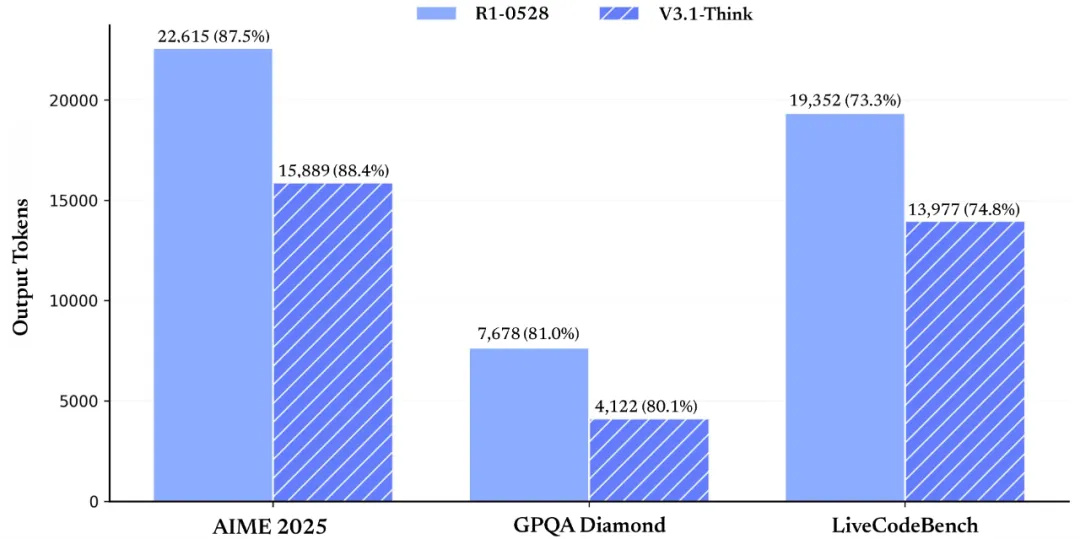
The improvement in thinking efficiency is also reflected in the number of output tokens. Compared to DeepSeek-R1-0528, DeepSeek-V3.1's Think mode reduces the number of output tokens from 22,615 to 15,889 in
The DeepSeek-V3.1 model data, tokenizer, and chat templates have been made publicly available on Hugging Face. The underlying DeepSeek-V3.1-Base model has also been made public. This DeepSeek-V3.1-Base model is based on V3 and has undergone continuous pre-training on 840 billion tokens to expand the context of long sentences.
deepseek-ai/DeepSeek-V3.1-Base · Hugging Face
deepseek-ai/DeepSeek-V3.1 · Hugging Face
https://huggingface.co/deepseek-ai/DeepSeek-V3.1
The DeepSeek-V3.1 API fees are set at $0.07 (approximately 11 yen) to $0.56 (approximately 80 yen) per million tokens for input and $1.68 (approximately 250 yen) per million tokens for output.

Related Posts: