Alibaba has announced a new model for its AI agents, 'Qwen3.7-Max,' which supports 35 hours of autonomous work and over 1,000 tool calls.

Alibaba's Qwen team has announced a new model for AI agents called 'Qwen3.7-Max.' Rather than being a chat AI that answers questions, Qwen3.7-Max is described as a foundational model for writing and debugging code, automating office tasks, and continuously working through tasks that span hundreds or thousands of steps. The Qwen team describes Qwen3.7-Max as 'the latest proprietary model for the age of AI agents.'
Qwen3.7: The Agent Frontier
Qwen3.7: The Agent Frontier - Alibaba Cloud Community
https://www.alibabacloud.com/blog/qwen3-7-the-agent-frontier_603154
An AI agent refers to an AI system that receives human instructions, devises work procedures, and carries out tasks while calling external tools as needed. For example, tasks such as 'investigating a codebase and fixing bugs,' 'reading spreadsheet files and creating documents,' and 'completing a business workflow using multiple tools' require the AI to repeatedly edit files, execute commands, verify, and revise. Qwen3.7-Max is a model that emphasizes its ability to carry out long-term, multi-stage tasks without interruption.
According to the Qwen team, Qwen3.7-Max functions as a 'coding AI agent' capable of handling everything from front-end prototyping to software development spanning multiple files, and also supports the automation of office tasks through MCP integration and collaboration between multiple AI agents. MCP is a mechanism used as a connection method for AI to access external tools and services, and is important when having AI agents perform tasks such as browser operations, file operations, and business tool operations.
The figure below compares Qwen3.7-Max, Qwen3.6-Plus, DeepSeek-V4-Pro Max, GLM-5.1, Kimi K2.6, and Claude Opus-4.6 Max across multiple benchmarks. Qwen3.7-Max shows high scores across a wide range of categories, including coding AI agent, AI agent execution, instruction following, and knowledge testing.
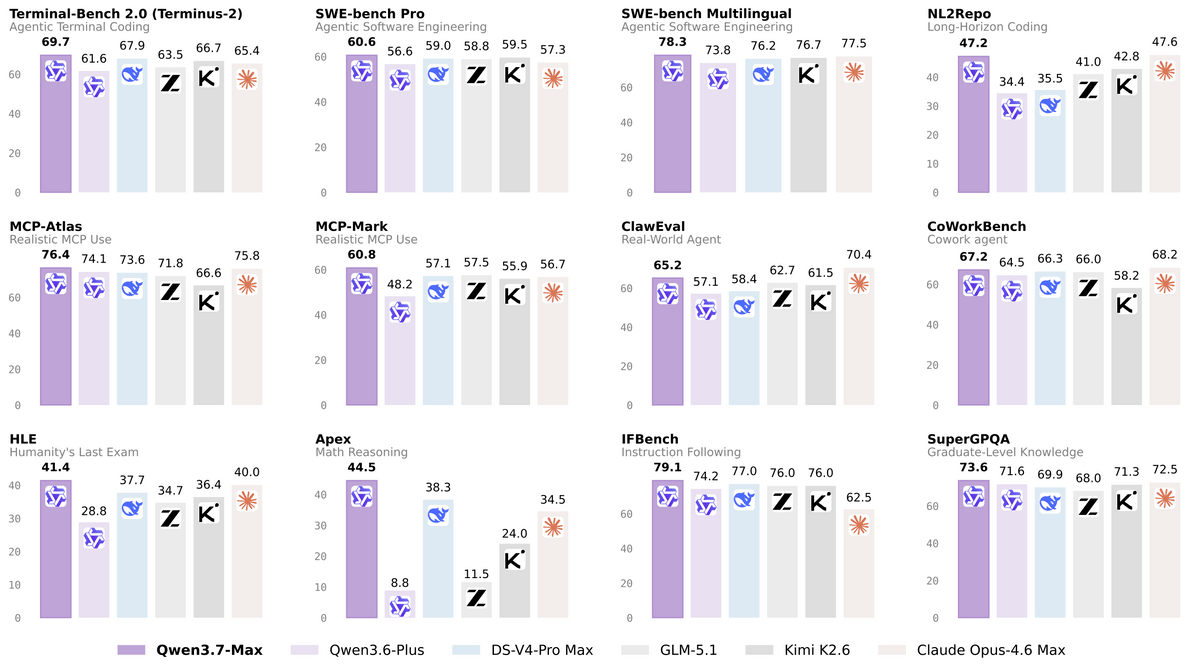
In evaluations related to coding AI agents, Terminal-Bench 2.0 Terminus-2 scored 69.7, surpassing DeepSeek-V4-Pro Max's 67.9. Furthermore, SWE-bench Verified scored 80.4, close to Claude Opus-4.6 Max's 80.8 and DeepSeek-V4-Pro Max's 80.6.
In general AI agent performance tests, it achieved a score of 60.8 in MCP-Mark, surpassing GLM-5.1's 57.5, and a score of 76.4 in MCP-Atlas, surpassing Claude Opus-4.6 Max's 75.8. In Kernel Bench L3, an evaluation of how well the AI can optimize computational programs for GPUs, it achieved a median speedup of 1.98 times compared to the reference implementation of PyTorch, and generated code that was faster than torch.compile in 96% of cases.
One point particularly emphasized about Qwen 3.7-Max is that it's 'not just strong in specific AI agent execution environments.' An AI agent execution environment is the underlying software that allows AI to perform tasks such as tool manipulation, code execution, file editing, and verification. The Qwen team states that it delivers consistent performance across Claude Code, OpenClaw, Qwen Code, and other execution environments.
The figure below compares the scores of Qwen3.7-Max in QwenClawBench and CoWorkBench when running Qwen3.7-Max across multiple AI agent execution environments. Qwen3.7-Max performed well in OpenClaw, Claude Code, and Hermes environments, maintaining a higher score than Qwen3.6-Plus.
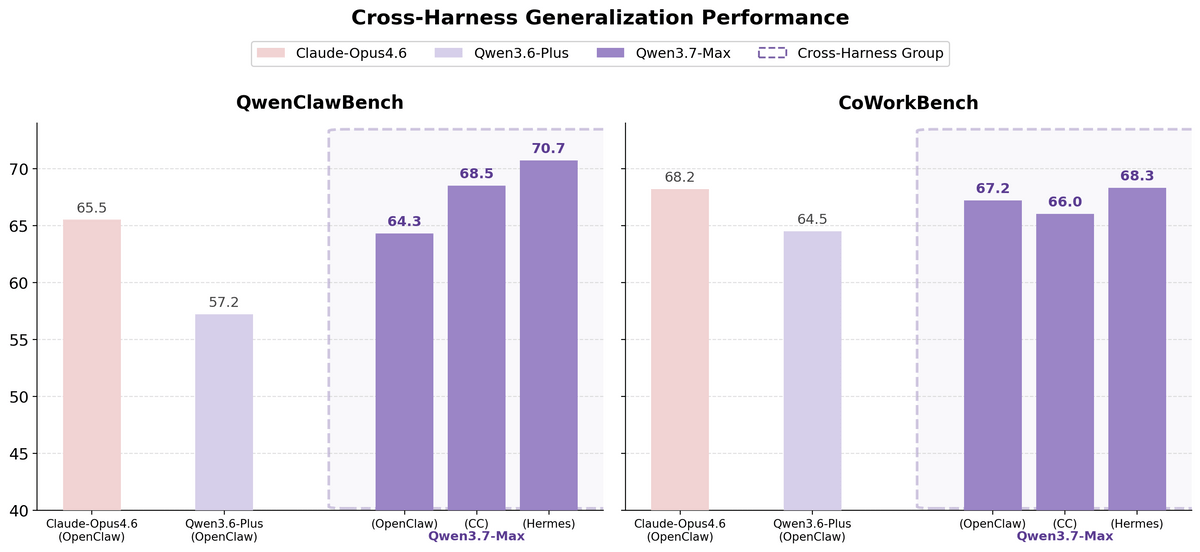
The Qwen team explained that they adopted a design that separates the 'task,' 'execution environment,' and 'validator' during training, and trains the model by changing their combinations, in order to teach the AI model problem-solving methods that work in any execution environment, rather than the quirks of a specific tool. The Qwen team stated that the consistent performance observed in QwenClawBench and CoWorkBench indicates that Qwen3.7-Max learned the ability to solve the task itself, rather than finding loopholes in a specific environment.
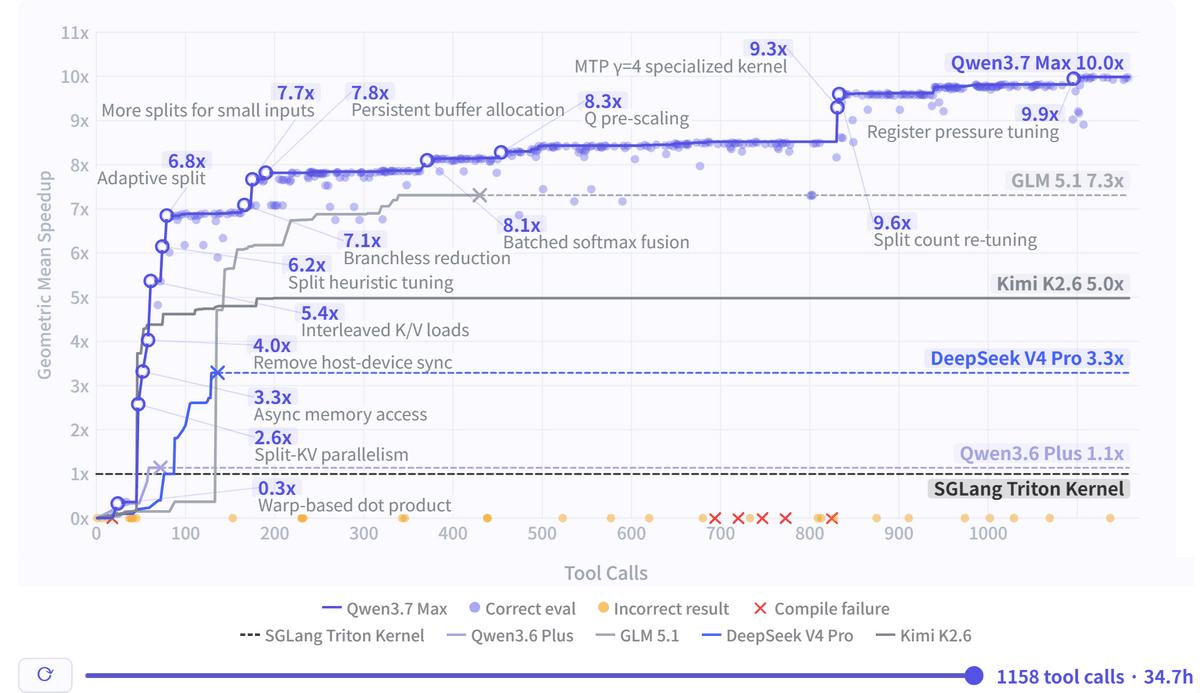
As a demonstration of long-term autonomous execution, the Qwen team has released a kernel optimization task. The target was SGLang's Extend Attention Kernel, and Qwen3.7-Max started working on an ECS instance equipped with a T-Head ZW-M890 PPU, which it had not seen during training, without any prior hardware documentation or sample kernels. Over approximately 35 hours, it performed 432 kernel evaluations and 1158 tool calls, autonomously repeating code creation, compilation, performance measurement, bug fixing, and redesign.
The diagram below shows how Qwen3.7-Max increased its speedup rate in proportion to the number of tool calls during kernel optimization. Ultimately, it achieved a geometric mean speedup of 10 times compared to the Triton reference implementation of SGLang. For comparison, when tested under the same conditions, GLM 5.1 achieved 7.3 times, Kimi K2.6 achieved 5.0 times, DeepSeek V4 Pro achieved 3.3 times, and Qwen3.6-Plus achieved 1.1 times. The Qwen team explained that Qwen3.7-Max maintained its optimization strategy even during more than 1000 tool calls and continued to find meaningful improvements even after more than 30 hours.
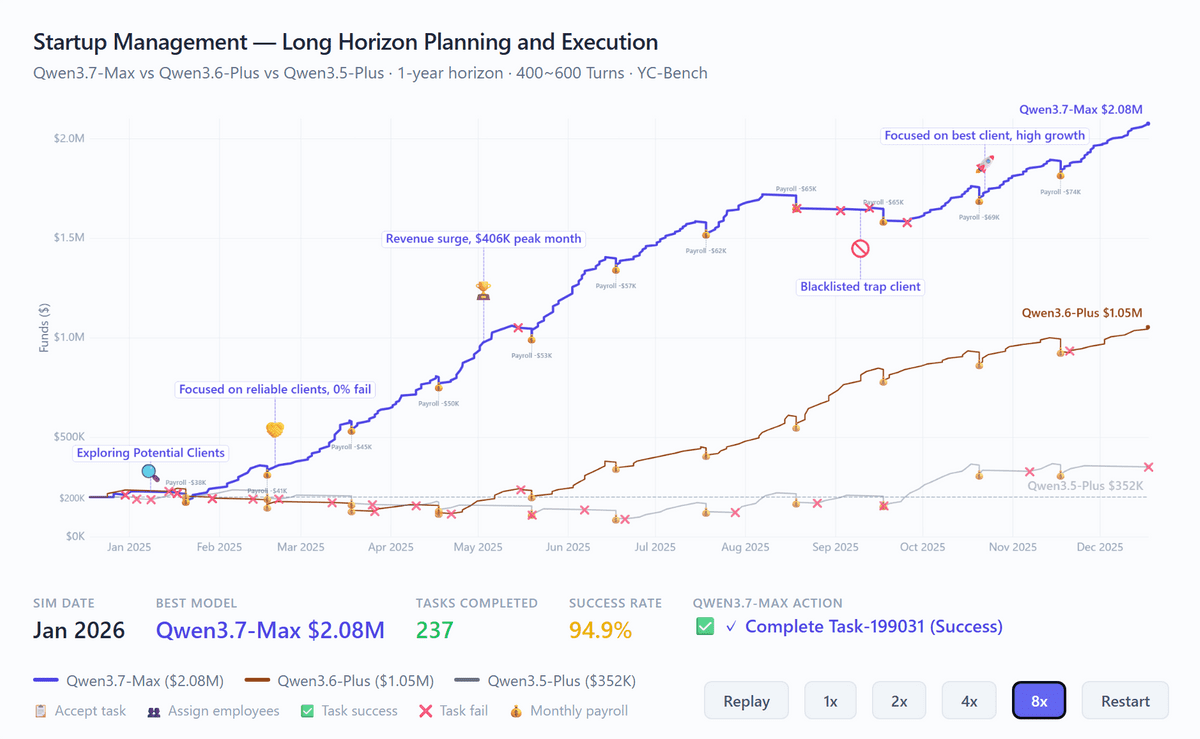
As an example of measuring long-term, multi-stage planning ability, the results of YC-Bench, which simulates a year of startup management, are also presented. YC-Bench requires hundreds of rounds of decision-making, including talent management, contract review, identifying malicious customers, and maintaining a balance between revenue and labor costs. Qwen3.7-Max achieved total revenue of $2.08 million (approximately 330 million yen), which is about double the $1.05 million (approximately 167 million yen) of Qwen3.6-Plus and about 5.9 times the $352,000 (approximately 56 million yen) of Qwen3.5-Plus. The number of completed tasks was 237.
The chart below compares the funding trends of Qwen3.7-Max, Qwen3.6-Plus, and Qwen3.5-Plus on YC-Bench. The annotation notes that Qwen3.7-Max maintained its growth by blocking malicious customers while focusing on trusted customers.
Qwen3.7-Max will be available to developers via Alibaba Cloud Model Studio. As of the time of writing, it is listed as 'coming soon,' and Model Studio is described as supporting an Anthropic-compatible API interface in addition to an API compatible with the OpenAI specification. Furthermore, Qwen3.7-Max supports the 'preserve_thinking' function, which can retain inferences from previous interactions, making it recommended for use in long AI agent tasks.
Alongside the announcement of Qwen3.7-Max, Alibaba is also strengthening its AI chips and cloud infrastructure. T-Head's new AI processor, the Zhenwu M890, boasts three times the performance of its predecessor, the Zhenwu 810E, and supports 144GB of GPU memory, 800GB of inter-chip bandwidth per second, and numerical precision from FP32 to FP4. In addition, the Panjiu AL128 Supernode Server, which integrates 128 AI accelerators into a single rack, was also announced, providing a configuration that supports large-scale AI agent inference and large-scale model training.
The Qwen team describes Qwen3.7-Max as a model that combines reasoning capabilities, cross-environment performance, and long-term productive execution for coding, office automation, and long-running autonomous tasks. The Qwen team states that Qwen3.7-Max will be a powerful foundation for building next-generation AI agents.
Related Posts:






in AI, Posted by log1d_ts