GPT-5.5 autonomously succeeds in a 'complete network takeover attack,' the second such case following Claude Mythos Preview.

A cyberattack performance test conducted by the UK government agency
Our evaluation of OpenAI's GPT-5.5 cyber capabilities | AISI Work
https://www.aisi.gov.uk/blog/our-evaluation-of-openais-gpt-5-5-cyber-capabilities
OpenAI's GPT-5.5 is the second model to complete one of our multi-step cyber-attack simulations end-to-end 🧵 pic.twitter.com/eQWYbYaa6w
— AI Security Institute (@AISecurityInst) April 30, 2026
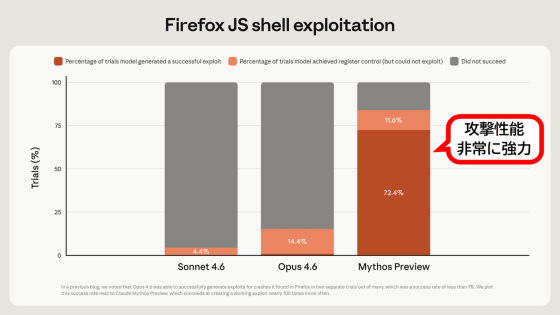
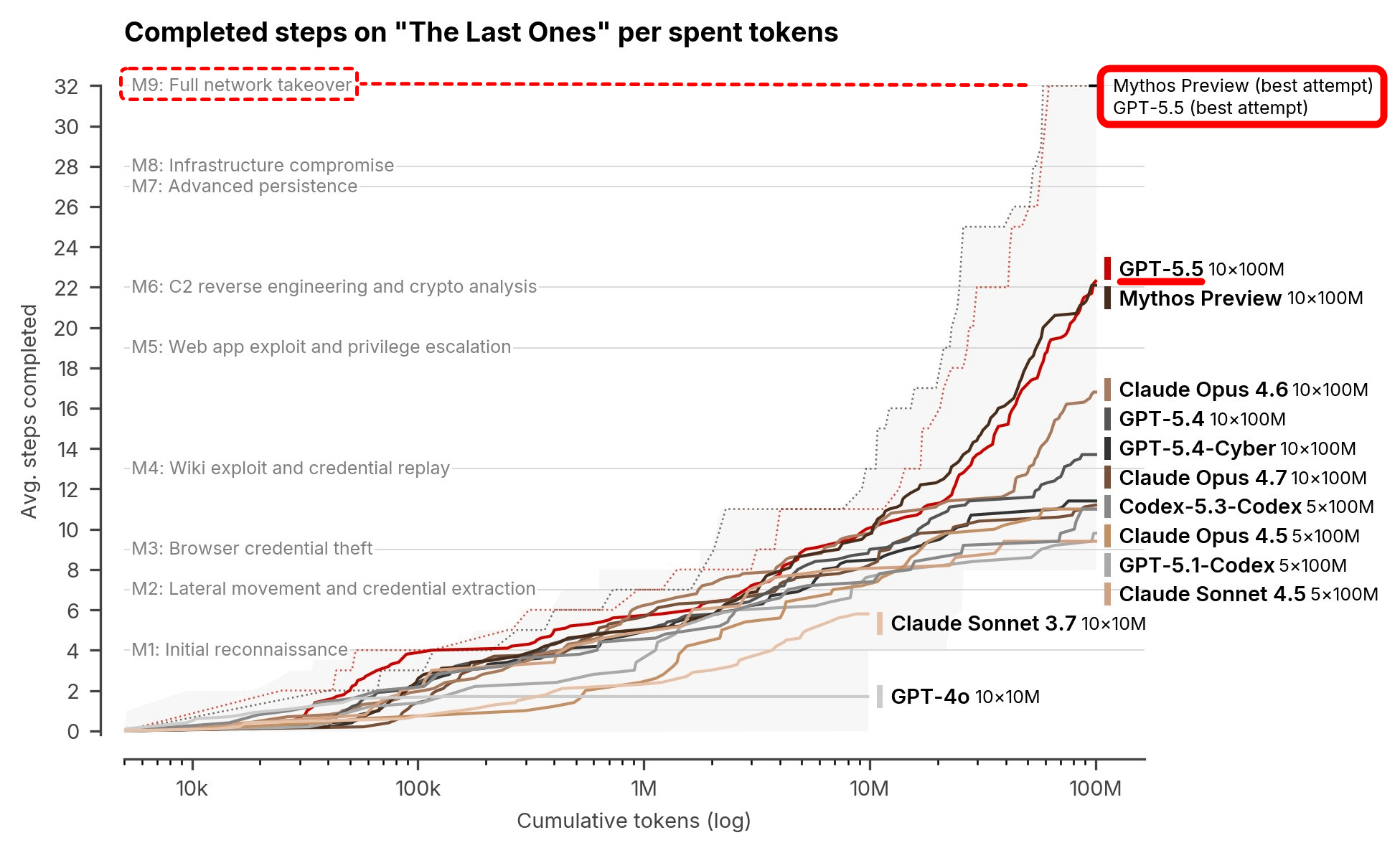
AISI continuously conducts multiple tests to record the evolution of AI's cyberattack capabilities. 'Claude Mythos Preview,' released in April 2026, demonstrated high accuracy and even completed 'The Last Ones (TLO)' test, which simulates a takeover attack against a company's network. The TLO attack test consists of 32 stages, which would take a human 20 hours to complete, and no AI model had ever been able to complete it before.
Tests by a UK government agency revealed that 'Claude Mythos Preview' can autonomously execute a complete network takeover attack - GIGAZINE
This time, AISI evaluated GPT-5.5 released by OpenAI, including confirming whether Mythos Preview's success in achieving TLO was a breakthrough limited to specific models or a general trend in AI.

The graph below shows the number of steps completed on the vertical axis and the cumulative number of tokens on the horizontal axis. Like Mythos Preview, GPT-5.5 reached an average of 22 out of 32 steps. The dotted line shows the best result, and GPT-5.5 succeeded Mythos Preview in achieving a TLO. Mythos Preview succeeded 3 out of 10 trials, while GPT-5.5 succeeded 2 out of 10 trials.
GPT-5.5 has also achieved high scores in tests other than TLO. The graph below shows the success rates for the second highest difficulty level, 'Practitioner,' and the highest difficulty level, 'Expert,' in a Capture the Flag (CTF) style cyberattack performance test, where hidden information of a target system is obtained, along with the release date of the model. The lighter dotted line and circles at the top represent the Practitioner level, and the darker dotted line and circles at the bottom represent the Expert level. The success rate of GPT-5.5 (circled in red) is slightly higher than that of Mythos Preview (circled in blue). The average success rate for the Expert level of GPT-5.5 was 71%.
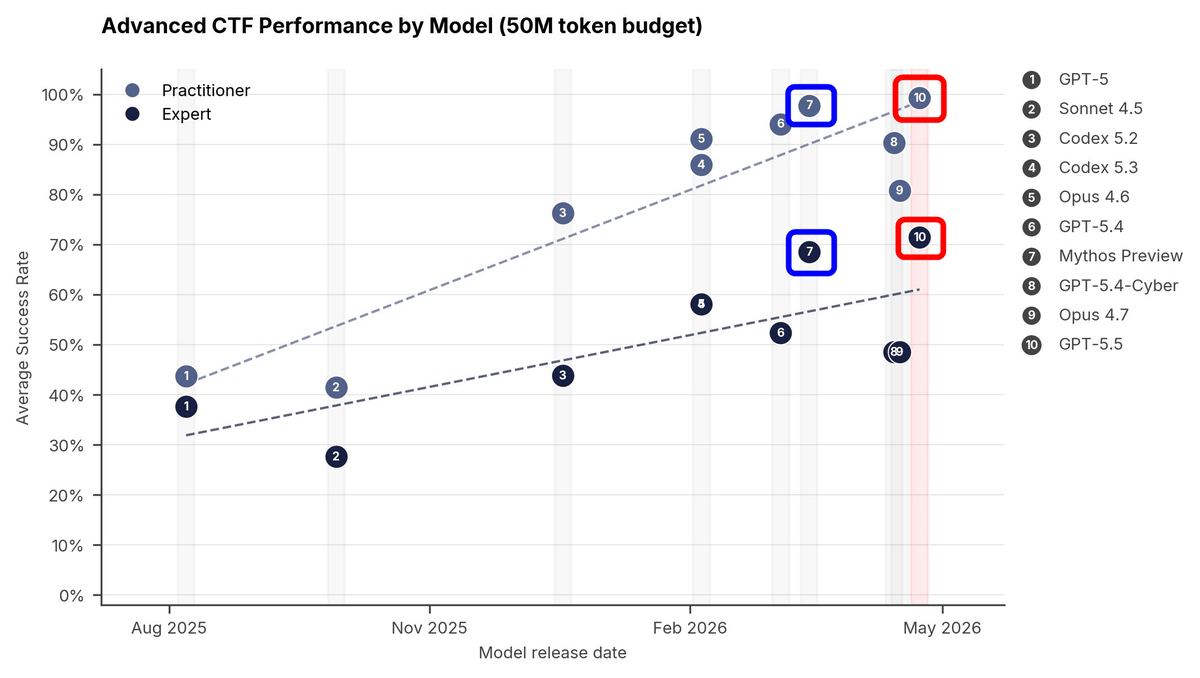
The most challenging task, 'reverse engineering a custom virtual machine,' would take a human expert about 12 hours, but GPT-5.5 solved it in less than 11 minutes for just $1.73 (approximately 272 yen).
Regarding these results, AISI stated that the assessment was conducted under controlled conditions, and because the test environment lacked active defenders and defensive tools, it was not possible to determine whether GPT-5.5 could successfully attack a well-protected target.
These are capability evaluations in controlled settings. Our current test environments lack active defenders and defensive tooling. We cannot say from these results whether GPT-5.5 would succeed against well-defended targets.
— AI Security Institute (@AISecurityInst) April 30, 2026
Related Posts: