A vintage language AI model called 'talkie' has emerged, trained using only knowledge up to the 1930s, allowing it to interact with the past and verifying its generalization capabilities.

'talkie-1930,' a 13 billion-parameter 'vintage language model' trained solely on texts up to 1930, has emerged. What sets talkie-1930 apart is that it possesses no modern knowledge and learns only from historical documents, allowing for an experience akin to conversing with a historical figure.
Introducing talkie: a 13B vintage language model from 1930
Here's an example of how Claude Sonnet 4.6 , which actually debuted on February 17, 2026, interacted with talkie. It responds naturally to everyday greetings.

Furthermore, the translation of the exchange regarding the Russian Revolution is as follows: While detailed answers were given to questions about information before 1930, information about 1930 and later, such as 'the conflict between communism and capitalism led to the Cold War,' was not included.

Using talkie-1930, it's possible to recreate the thought experiment of 'what would you ask if you could talk to people from the past?' in a way that closely resembles reality. By using a model trained solely on historical texts, it's possible to obtain responses based on the knowledge systems and values of that time, creating an experience akin to riding a time machine.
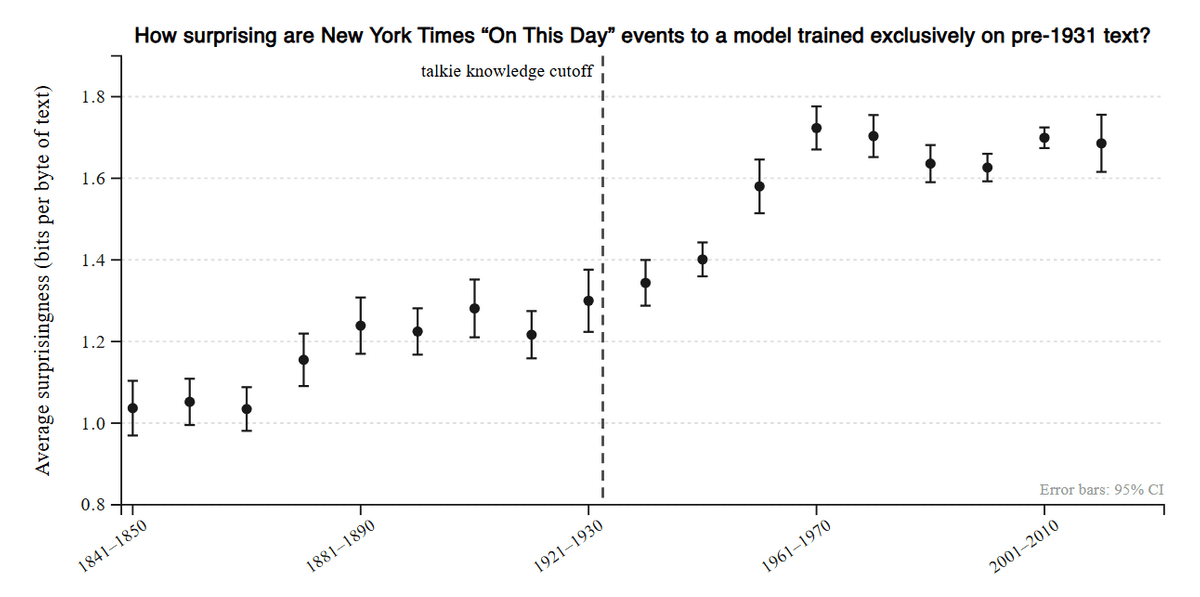
The research team also states that examining the behavior of models trained only on past information may lead to a deeper understanding of the nature of language models themselves. For example, using descriptions of approximately 5,000 historical events published in the New York Times' 'On This Day' column, they analyzed how 'unexpected' these events were to models trained on data from before 1931 and evaluated their ability to predict the future. They found that the degree of unexpectedness increased for events occurring after the knowledge cutoff, and this trend was particularly pronounced in the 1950s and 60s.
Furthermore, research is progressing from the perspective of 'whether the model can rediscover things that are invented after knowledge cutoff,' and it is being verified whether inventions such as Turing's theory of computation, helicopter patents, and xerography can be derived without prior knowledge. This also leads to the question of whether AI can reproduce the kind of creative thinking that Albert Einstein used when he discovered general relativity in 1915.
The research team also tested the model's programming capabilities. In an experiment where they presented several Python code examples to a model that supposedly had no knowledge of digital computers and asked it to write new functions on the spot, they confirmed that while its performance was significantly inferior to models trained on modern web data, it could correctly generate simple operations and minor modifications to existing code. For example, in a case where the model had to generate the inverse function of a function that shifts a string by a certain amount, it was able to derive the correct answer by simply replacing addition with subtraction, suggesting that it may have some understanding of the concept of 'inverse functions.'
This type of model also has the advantage of being less susceptible to 'data contamination.' While modern models are criticized for the problem of evaluation data getting mixed in with the training data, vintage models use training data limited to past literature, making it less likely for evaluation data created in the present to be mixed in, thus creating an environment where generalization ability can be measured more easily.
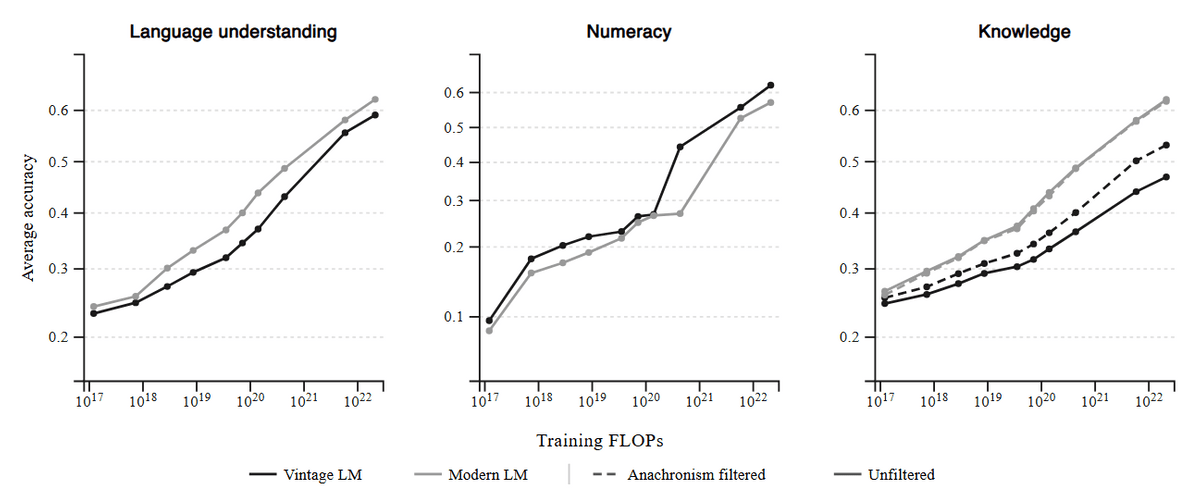
On the other hand, it lags behind modern models in many aspects of performance, and the difference is still significant, especially in knowledge-based tasks, even after excluding concepts that did not exist in 1930.
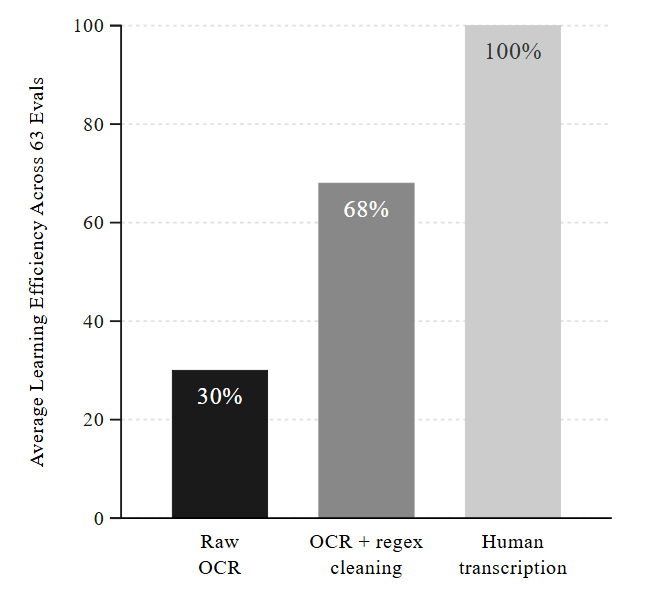
The research team states that data quality issues are the cause of the performance difference. Since digital text did not exist before 1930, everything had to be converted from paper documents using OCR (optical character recognition), but a large number of misrecognitions occurred during this process. In the experiment, models trained only on OCR data had a learning efficiency of only about 30% compared to manual transcription, and even after cleaning with regular expressions, it only recovered to about 70%.
Even more important is the problem of 'temporal leaks.' Temporal leaks are a phenomenon where future information that shouldn't be included, such as annotations added later or incorrect metadata, gets mixed into the data. In fact, early versions of the model have been found to contain knowledge about the Roosevelt administration and World War II after 1930, making complete removal a difficult challenge.

Furthermore, using data from modern chat formats can lead to chronological inconsistencies, requiring careful adjustment of the model's conversational abilities after training. Therefore, they generate instruction-response pairs from historically well-structured sources such as etiquette books, letter-writing guides, dictionaries, and encyclopedias, and use these to refine the model. They then perform reinforcement learning-like optimization using prompts that mimic various tasks, ultimately refining the model with multi-turn conversation data.
The newly announced talkie-1930 is trained on 260 billion tokens of English text from before 1930, making it one of the largest vintage language models currently available. There are plans to expand it to the equivalent of GPT-3, and even GPT-3.5, with the final data volume expected to exceed 1 trillion tokens.
It should be noted that talkie's output reflects the culture and values of the historical texts it was trained on, and therefore may generate content that would be considered inappropriate by modern standards. This is due to the model's design and the fact that modern ethical filters are not fully applied.
The research team plans to further develop the data by translating it into multiple languages, improving OCR accuracy, enhancing the detection of temporal leaks, and building historically accurate personality models. They are also calling for collaboration with historians and research institutions.
Related Posts:








in AI, Posted by log1d_ts