'Qwen3.5-Omni' has been released, enabling text generation, code generation, image recognition, speech synthesis, and web search.

Alibaba's AI research team, Qwen (Tongyi Lab), announced ' Qwen3.5-Omni ' on March 30, 2026. Qwen3.5-Omni is an omnimodal model capable of understanding text, images, audio, and video, and can generate not only text but also audio. It is touted as having audio and video understanding capabilities that surpass Gemini 3.1 Pro.
Qwen3.5-Omni: Scaling Up, Toward Native Omni-Modal AGI
Qwen-Omni - Alibaba Cloud Model Studio - Alibaba Cloud Documentation Center
https://www.alibabacloud.com/help/en/model-studio/qwen-omni
Qwen3.5-Omni is an AI model trained using over 100 million hours of visual-speech data. It incorporates a 'Hybrid MoE Talker' and a 'Hybrid MoE Thinker,' and by transmitting the Thinker's text output to the Talker, it can produce context-aware speech. Furthermore, the entire model is designed with real-time response in mind.
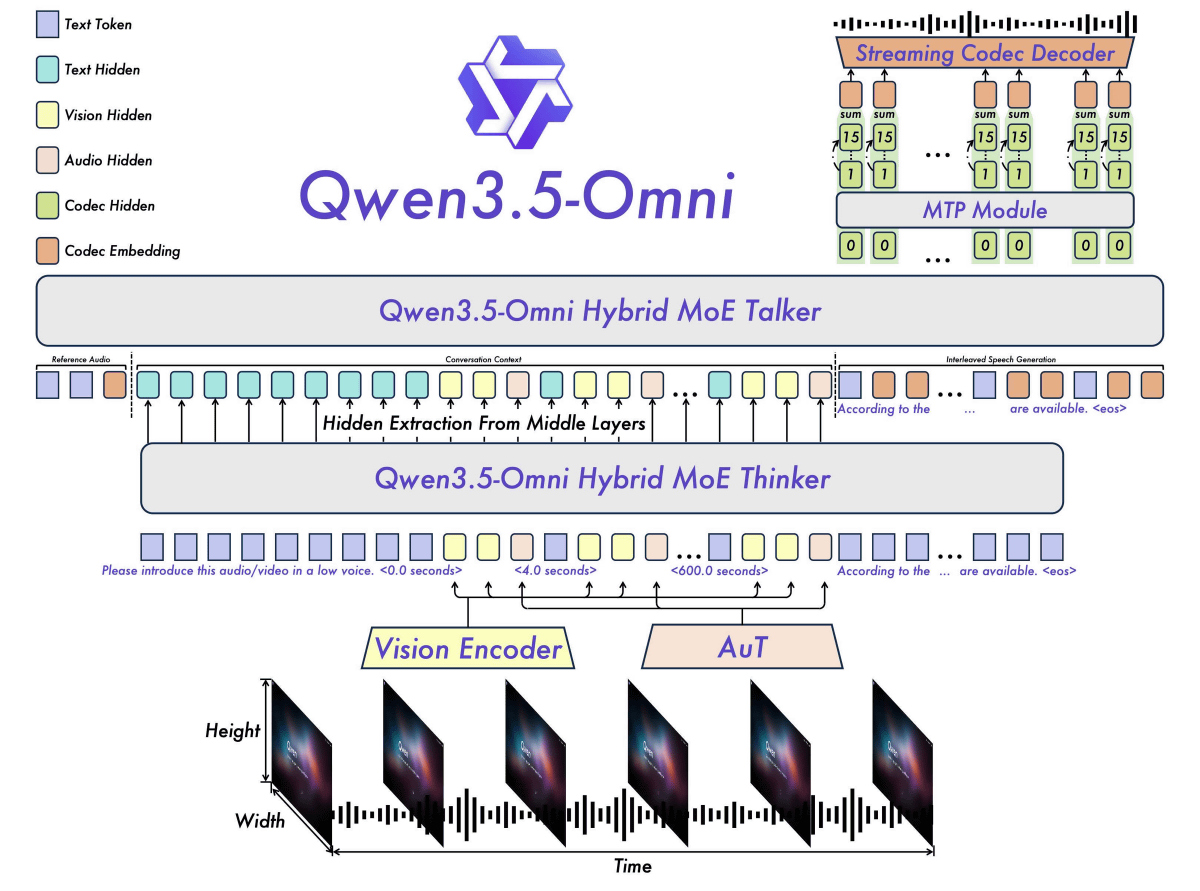
Qwen3.5-Omni has a maximum sequence length of 256,000, allowing for input of up to 10 hours of audio or 400 seconds (1 FPS) of audiovisual data. Its speech recognition function supports 74 languages, including 39 Chinese dialects, as well as Japanese and English. Furthermore, its speech synthesis supports 29 languages, including 7 Chinese dialects, as well as Japanese and English.
Qwen3.5-Omni is released in three models: 'Qwen3.5-Omni Plus,' 'Qwen3.5-Omni Flash,' and 'Qwen3.5-Omni Light,' and is available via offline and real-time APIs.
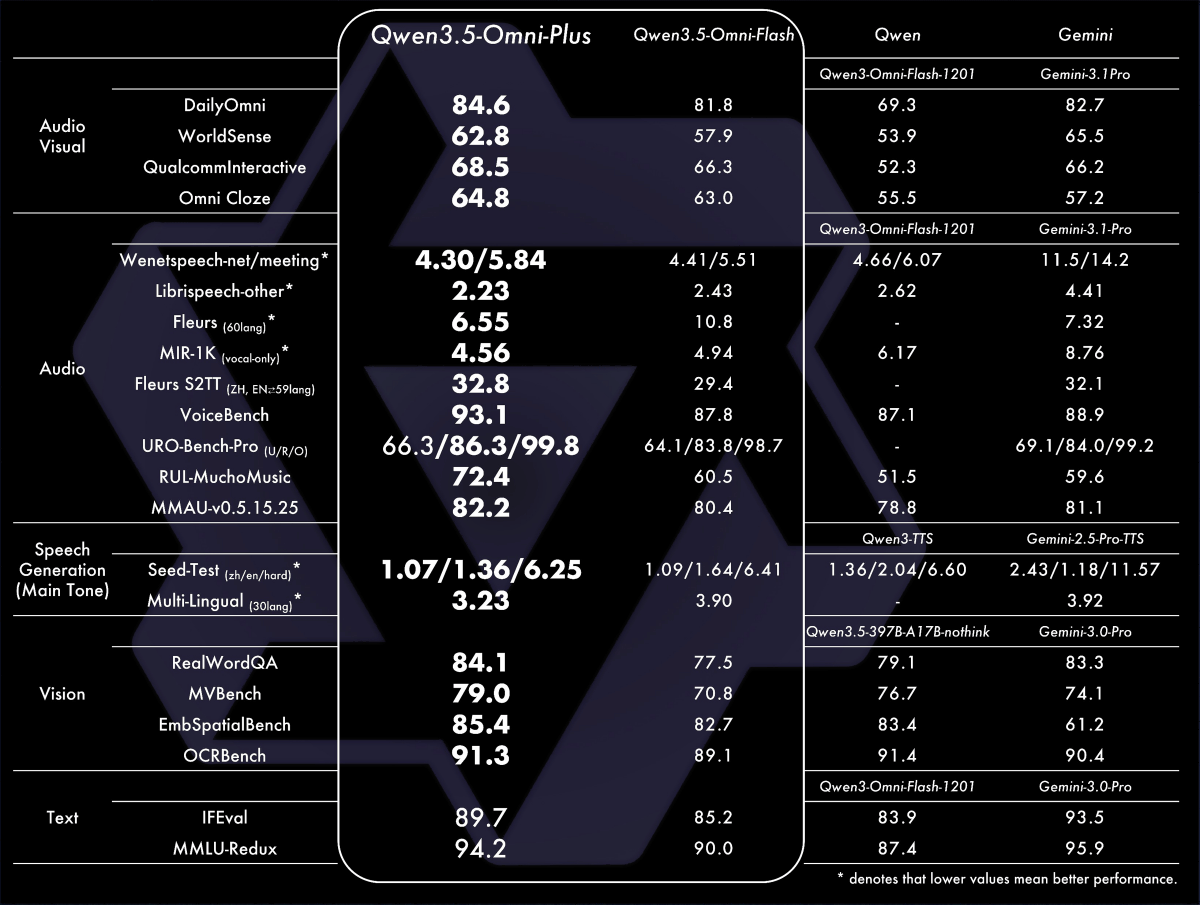
The table below shows the benchmark results for the 'Qwen3.5-Omni Plus,' 'Qwen3.5-Omni Flash,' 'Older Qwen Models,' and 'Gemini 3.1 Pro.' The Qwen3.5-Omni Plus outperforms the Gemini 3.1 Pro in several tests.
The following is a demo video demonstrating the audiovisual data recognition performance of Qwen3.5-Omni. It accurately describes the events contained in the video in text.
2/10 Script-Level Captioning pic.twitter.com/q4bKesjJVo
— Tongyi Lab (@Ali_TongyiLab) March 30, 2026
It's also possible to input a video showing a hand-drawn design while verbally explaining the desired function, and have the system output the appropriate code. Tongyi Lab refers to this series of operations as 'Audio-Visual Vibe Coding.'
4/10 Audio-Visual Vibe Coding pic.twitter.com/6XCB53L6QA
— Tongyi Lab (@Ali_TongyiLab) March 30, 2026
You can also generate high-quality audio while adjusting the tone of voice.
7/10 Voice Style, Emotion and Volume Control pic.twitter.com/L3iMuRp4T4
— Tongyi Lab (@Ali_TongyiLab) March 30, 2026
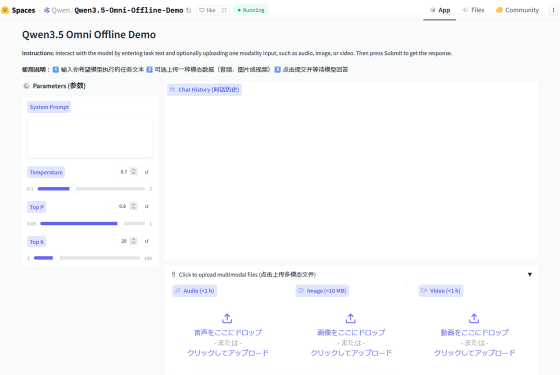
You can run the Qwen3.5-Omni demo at the following link.
Qwen3.5 Omni Offline Demo - a Hugging Face Space by Qwen
https://huggingface.co/spaces/Qwen/Qwen3.5-Omni-Offline-Demo
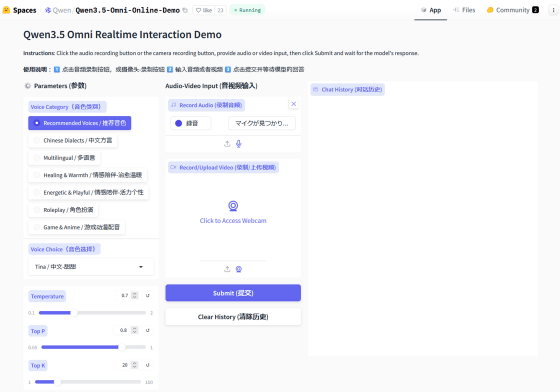
A demo of the real-time response function has also been released.
Qwen3.5 Omni Online Demo - a Hugging Face Space by Qwen
https://huggingface.co/spaces/Qwen/Qwen3.5-Omni-Online-Demo
Related Posts:







in AI, Posted by log1o_hf