Cohere has announced 'Transcribe,' an open-source speech recognition model specifically for transcription that also supports Japanese.

AI company Cohere announced its open-source speech recognition (ASR) model ' Transcribe ' on March 26, 2026. This model supports English, Japanese, Chinese, Korean, Vietnamese, French, German, Italian, Spanish, Portuguese, Greek, Dutch, Polish, and Arabic, and can be downloaded from Hugging Face or tried out via Cohere's API.
Cohere Transcribe: state-of-the-art speech recognition
Transcribe | Cohere
https://cohere.com/transcribe
CohereLabs/cohere-transcribe-03-2026 · Hugging Face
https://huggingface.co/CohereLabs/cohere-transcribe-03-2026
Transcribe is an open-source ASR model specifically designed for converting speech to text, intended for enterprise applications such as meeting transcription, speech analysis, and real-time customer support. Cohere positions it as the foundation for enterprise speech intelligence.
A key feature of Transcribe is that it aims for high transcription accuracy while being designed for practical use, rather than being an experimental model for research purposes. According to Cohere, it ranked first on Hugging Face's Open ASR Leaderboard with an average word error rate (WER) of 5.42%, beating OpenAI's Whisper Large v3 at 7.44%, ElevenLabs Scribe v2 at 5.83%, and Qwen3-ASR-1.7B at 5.76%. These results are explained as demonstrating high performance even under realistic conditions such as conversations with multiple speakers, acoustic environments like conference rooms, and diverse accents.
Open ASR Leaderboard - a Hugging Face Space by hf-audio
https://huggingface.co/spaces/hf-audio/open_asr_leaderboard
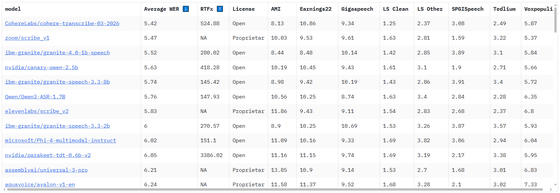
Furthermore, Cohere explains that Transcribe also received high marks in human comparative evaluations, where evaluators compared the transcription results based on criteria such as whether the meaning was properly preserved, whether there was hallucination, whether proper nouns were correctly transcribed, and whether the text was word-for-word and appropriately formatted. As a result, it achieved an average success rate of 61% in English and 64% against Whisper Large v3.
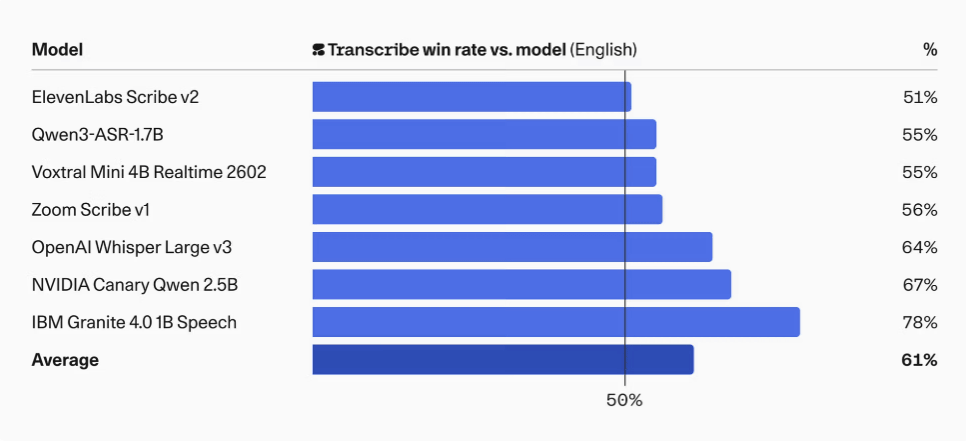
Furthermore, it is reported that the win rate against Qwen3-ASR-1.7B was 70% and against Whisper Large v3 was 66% in Japanese.
The model has 2 billion parameters and employs a Conformer-based encoder-decoder architecture. The input audio waveform is first converted into a Mel spectrogram, then the Conformer encoder, which handles most of the parameters, extracts the acoustic representation, and a lightweight Transformer decoder generates text tokens. Training was done from scratch, and it supports 14 languages: English, Japanese, Chinese, Korean, Vietnamese, German, French, Italian, Spanish, Portuguese, Greek, Dutch, Polish, and Arabic.
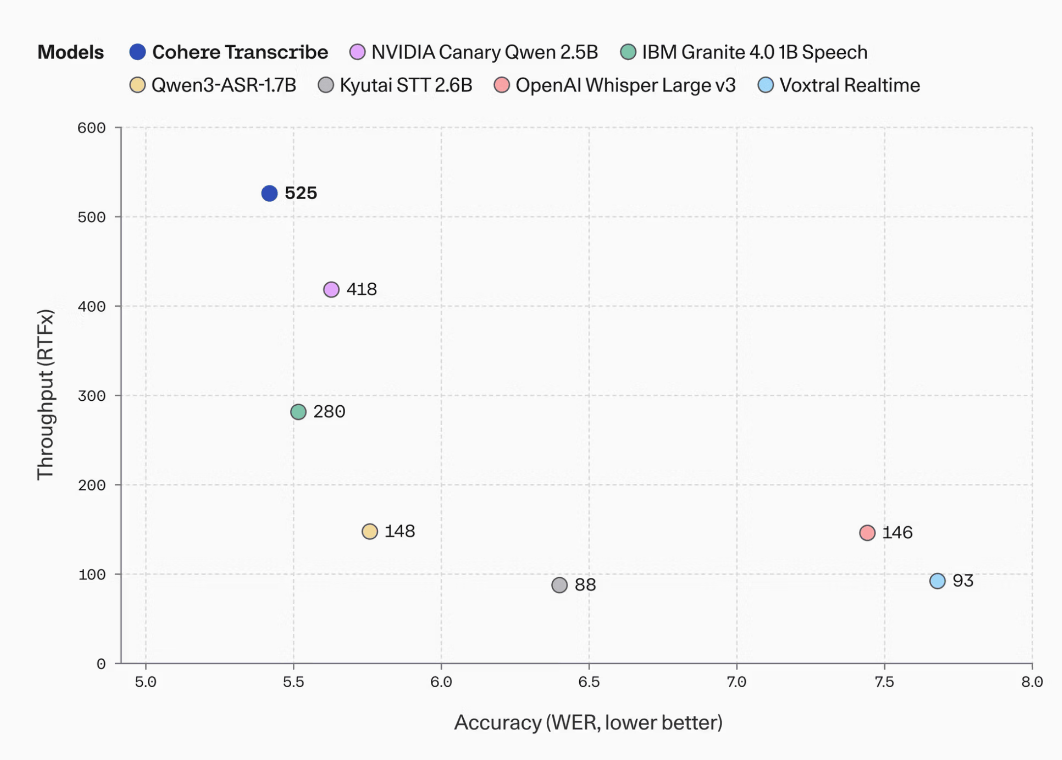
Processing speed is also a key consideration, and Cohere is described as being in a superior position among ASR models with parameter sizes exceeding 1 billion in terms of balancing accuracy and throughput. Below are the throughput (RTFx) and error rate (WER) for major ASR models with parameter sizes exceeding 1 billion. Cohere's Transcribe (blue) has a WER of 525, which means it can process input audio 525 times faster than real time. At the same time, Transcribe has the lowest WER among the other models, indicating high transcription accuracy.
Transcribe is offered as an open waitlist, making it easy to operate while controlling the infrastructure in your own environment. Cohere is described as having an inference load that is manageable on practical GPUs, local environments, and edge environments, making it suitable for cases where you want to process highly confidential audio data without sending it externally.
Furthermore, for those who want to use a low-latency inference environment without infrastructure management, the company also offers this through its managed inference platform, Model Vault .
On the other hand, Transcribe does not support automatic language detection and requires users to pre-select one of 14 languages. It may not perform well with code-switched audio, and it lacks features such as timestamping and speaker separation (dialysion). Furthermore, it tends to attempt to transcribe even in silent or non-speechless areas, so it is recommended to use VAD (Voice-Audio Detection) or a noise gate in front of it for practical use.
Cohere has also indicated its intention to integrate Transcribe more deeply with its AI agent orchestration platform, 'North.' While it is currently available as a highly accurate transcription model, the company envisions developing it into a broader platform for businesses to use for searching, analyzing, and automating audio data in the future.
Related Posts:






in AI, Posted by log1i_yk