Anthropic reports on 'How much authority do humans who use AI agents give to AI?'

Anthropic analyzed millions of conversational data sets from its coding agent, Claude Code, and public APIs, and published a research report on how AI agents demonstrate autonomy in the real world on February 18, 2026.
Measuring AI agent autonomy in practice \ Anthropic
The study found a significant increase in the amount of time agents spend working without human intervention in Claude Code sessions. In particular, for the top 0.1% of sessions with the longest running times, the time until the agent stopped (vertical axis) doubled from October 2025 to January 2026 (horizontal axis), expanding to around 45 minutes. This trend has been gradual rather than abrupt, even after the release of new models such as Sonnet 4.5 and Opus 4.5. This suggests that the increase is not simply due to improvements in model performance, but rather that existing models have greater autonomy than is demonstrated in production.
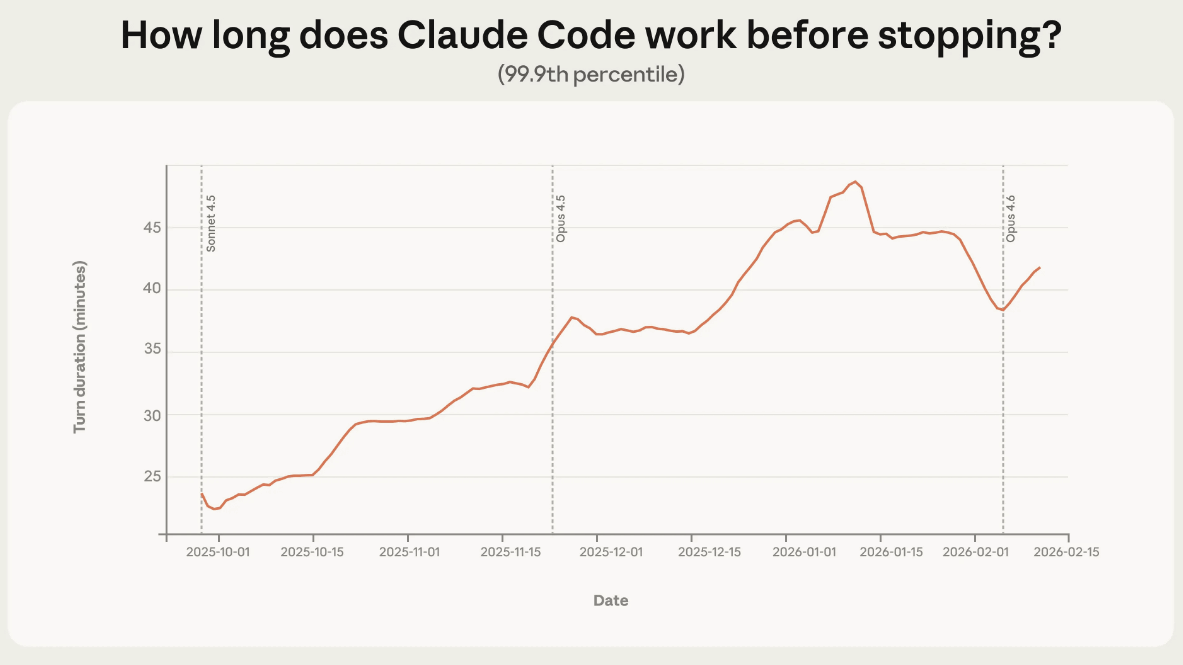
Anthropic's internal usage data also showed that the success rate for the most difficult tasks doubled, while the number of human interventions per session decreased from 5.4 to 3.3, confirming that both autonomy and practicality improved simultaneously.
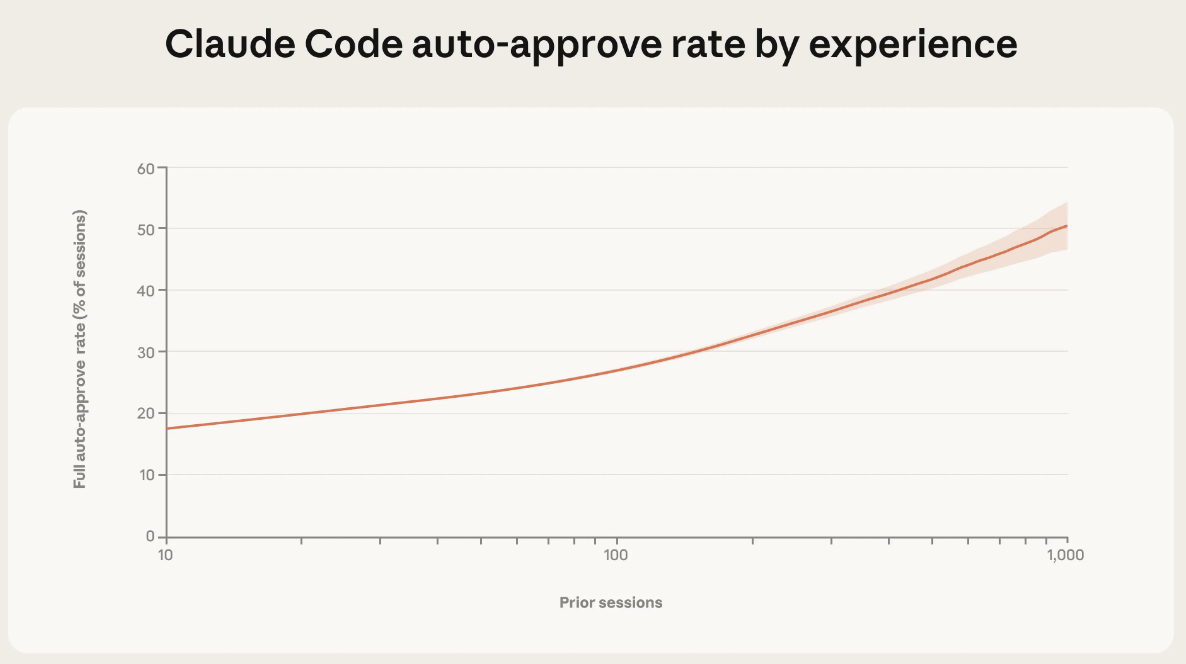
Furthermore, we found a clear pattern: as users become more familiar with Claude Code, they begin to give the agent more authority. New users with a low number of sessions (horizontal axis) only used the auto-approval setting for all actions (vertical axis) about 20% of the time, but experienced users with over 750 sessions used the setting more than 40% of the time. This indicates a steady buildup of trust in the tool.
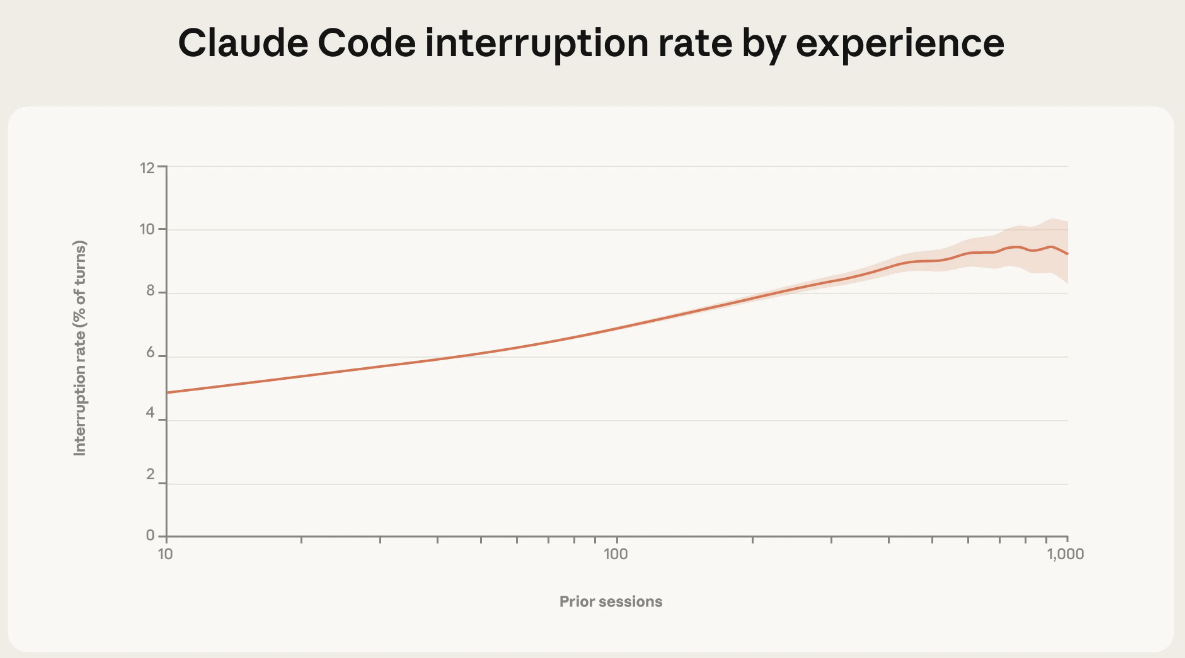
On the other hand, experienced users increased their automatic approvals while also interrupting the agent's operation more frequently. Looking at the intervention rate (vertical axis), it was around 5% for new users with few sessions (horizontal axis), but it reached approximately 9% for experienced users with many sessions. Anthropic believes this is because beginners use a 'pre-approval' monitoring strategy, approving each action in advance, while experienced users use an 'active monitoring' strategy, operating the agent autonomously but intervening immediately when a problem occurs.
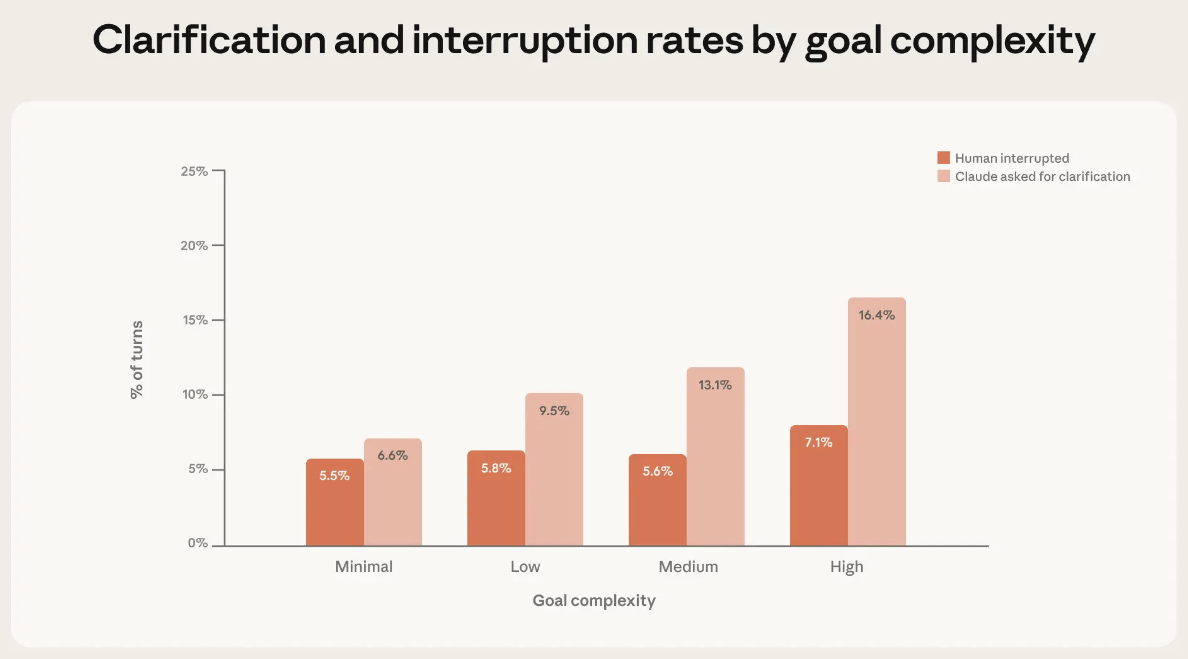
And autonomy isn't determined solely by humans; the AI itself recognizes its own uncertainty and limits its autonomy. Claude Code stops and asks for explanations more frequently the more complex the task, and in the most complex tasks, it asks questions more than twice as often as humans intervene.
Agent usage is primarily in software engineering, accounting for roughly 50% of tool usage actions in public APIs, but we are also beginning to see experimentation in areas as diverse as back-office automation, marketing, finance, and even medicine and healthcare.
From a risk perspective, 80% of current API actions are subject to 'protective measures' such as permission restrictions and human approval, and irreversible actions account for only 0.8% of all actions. However, a small number of applications have been confirmed in frontier areas where risk and autonomy coexist, such as executing financial transactions, updating medical records, and escalating security privileges. While many of these applications are currently simulated through evaluations and red team exercises, Anthropic stated that as agents penetrate more deeply into society's critical infrastructure, the boundaries between risk and autonomy are expected to expand.
Based on the results of this survey, Anthropic concludes that 'safe deployment of AI agents requires not only up-front performance evaluation but also continuous monitoring infrastructure after deployment.' It also states, 'Model developers should train AI to recognize its own uncertainty, and product developers should prioritize designs that make agent behavior transparent and allow for quick intervention when necessary, rather than forcing users to approve every single action.'
Anthropic also recommended that legislation should focus on whether humans are in a position to intervene effectively, as mandating specific interaction patterns could undermine the convenience and safety of experienced users.
Related Posts:







in AI, Posted by log1i_yk