Chinese company Z.ai announces open-source image generation AI 'GLM-Image,' a hybrid of autoregressive and diffusion models

GLM-Image: Auto-regressive for Dense-knowledge and High-fidelity Image Generation
https://z.ai/blog/glm-image
Z.ai announced their image generation model, GLM-Image, on January 14, 2026 (local time). It is a hybrid model that combines an autoregressive model and a diffusion model. The autoregressive model is initialized based on GLM-4-9B-041 , which has 9 billion parameters. The diffusion model follows CogView4 and employs a single-stream DiT structure with 7 billion parameters.
Hybrid GLM-Image models offer significant advantages in text rendering and knowledge-intensive generation, particularly in tasks requiring precise semantic understanding and complex information representation, while enabling generation that is faithful to the prompt.
Below is a summary of an example of image generation using GLM-Image.

Diffusion models have become the mainstream image generation model due to their training stability and strong generalization ability. Although diffusion models and
On the other hand, in recent years, there has been an increase in image generation AI that uses autoregressive models, which enable output that is faithful to prompts. However, autoregressive models have the disadvantage of slow execution. GLM-Image was developed as a hybrid model that combines the advantages of diffusion models and autoregressive models.
In GLM-Image, an autoregressive generator produces tokens carrying low-frequency semantic signals, while a diffusion decoder refines high-frequency details to provide the final image. This hybrid architecture not only works reliably for general image generation tasks, but also offers significant advantages in creative tasks requiring complex knowledge representation.
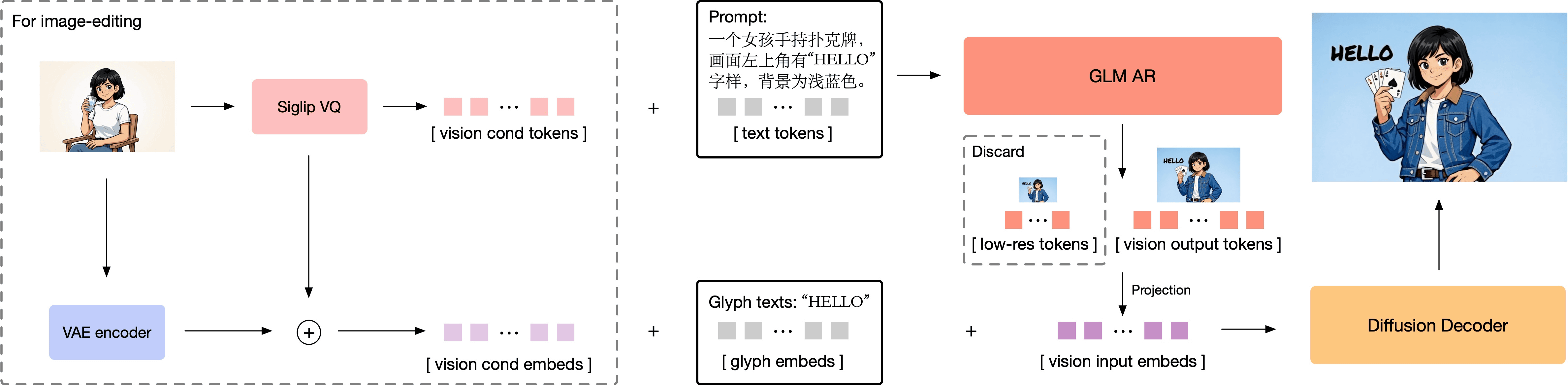
The diagram below shows the image generation mechanism of GLM-Image.
Below is a table comparing the text rendering accuracy of image generation models. GLM-Image is an open source model, yet it achieves overwhelmingly high text rendering accuracy.
| Model | Open Source | NED | CLIPScore | Word Accuracy 2 regions | Word Accuracy 3 regions | Word Accuracy 4 regions | Word Accuracy 5 regions | Word Accuracy average |
|---|---|---|---|---|---|---|---|---|
| GLM-Image | 〇 | 0.9557 | 0.7877 | 0.9103 | 0.9209 | 0.9169 | 0.8975 | 0.9116 |
| Seedream 4.5 | × | 0.9483 | 0.8069 | 0.8778 | 0.8952 | 0.9083 | 0.9008 | 0.899 |
| Z-Image | 〇 | 0.9367 | 0.7969 | 0.9006 | 0.8722 | 0.8652 | 0.8512 | 0.8671 |
| Qwen-Image-2512 | 〇 | 0.929 | 0.7819 | 0.863 | 0.8571 | 0.861 | 0.8618 | 0.8604 |
| Z-Image-Turbo | 〇 | 0.9281 | 0.8048 | 0.8872 | 0.8662 | 0.8628 | 0.8347 | 0.8585 |
| GPT Image 1[High] | × | 0.9478 | 0.7982 | 0.8779 | 0.8659 | 0.8731 | 0.8218 | 0.8569 |
| Seedream 4.0 | × | 0.9224 | 0.7975 | 0.8585 | 0.8484 | 0.8538 | 0.8269 | 0.8451 |
| Qwen-Image | 〇 | 0.9116 | 0.8017 | 0.837 | 0.8364 | 0.8313 | 0.8158 | 0.8288 |
| Nano Banana 2.0 | × | 0.8754 | 0.7372 | 0.7368 | 0.7748 | 0.7863 | 0.7926 | 0.7788 |
| TextCrafter | 〇 | 0.8679 | 0.7868 | 0.7628 | 0.7628 | 0.7406 | 0.6977 | 0.737 |
| SD3.5 Large | 〇 | 0.847 | 0.7797 | 0.7293 | 0.6825 | 0.6574 | 0.594 | 0.6548 |
| Seedream 3.0 | × | 0.8537 | 0.7821 | 0.6282 | 0.5962 | 0.6043 | 0.561 | 0.5924 |
| FLUX.1 [dev] | 〇 | 0.6879 | 0.7401 | 0.6089 | 0.5531 | 0.4661 | 0.4316 | 0.4965 |
| 3DIS | 〇 | 0.6505 | 0.7767 | 0.4495 | 0.3959 | 0.388 | 0.3303 | 0.3813 |
| RAG-Diffusion | 〇 | 0.4498 | 0.7797 | 0.4388 | 0.3316 | 0.2116 | 0.191 | 0.2648 |
| TextDiffuser-2 | 〇 | 0.4353 | 0.6765 | 0.5322 | 0.3255 | 0.1787 | 0.0809 | 0.2326 |
| AnyText | 〇 | 0.4675 | 0.7432 | 0.0513 | 0.1739 | 0.1948 | 0.2249 | 0.1804 |
Since GLM-Image is an open-source image generation model, the code and model data are publicly available on GitHub and Hugging Face.
GitHub - zai-org/GLM-Image: GLM-Image: Auto-regressive for Dense-knowledge and High-fidelity Image Generation.
https://github.com/zai-org/GLM-Image
zai-org/GLM-Image · Hugging Face
https://huggingface.co/zai-org/GLM-Image
Related Posts:








in AI, Posted by logu_ii