Wikimedia Foundation announces that 'relentless AI scraping is straining our infrastructure'
The recent rise of generative AI has led to a surge in demand for content used to train and infer models, with some AI companies using web-scraping bots called 'crawlers' to collect data. The Wikimedia Foundation, which runs the online encyclopedia Wikipedia, reported that traffic to content on
How crawlers impact the operations of the Wikimedia projects – Diff
https://diff.wikimedia.org/2025/04/01/how-crawlers-impact-the-operations-of-the-wikimedia-projects/
AI bots strain Wikimedia as bandwidth surges 50% - Ars Technica
The Wikimedia Foundation runs not only Wikipedia, but also Wikimedia Commons, a media file repository that stores public domain images, videos, and other files, with approximately 144 million pieces of content.
It has been reported that the bandwidth used to download content on Wikimedia Commons has increased by 50% since January 2024. According to the Wikimedia Foundation, this sharp increase is not due to human users, but mainly due to bots scraping openly licensed images from the Wikimedia Commons image catalog to provide images for training AI models.
While the Wikimedia Foundation's servers are built to withstand sudden spikes in human traffic during high-interest events, the amount of crawler traffic is unprecedented, increasing risks and costs.
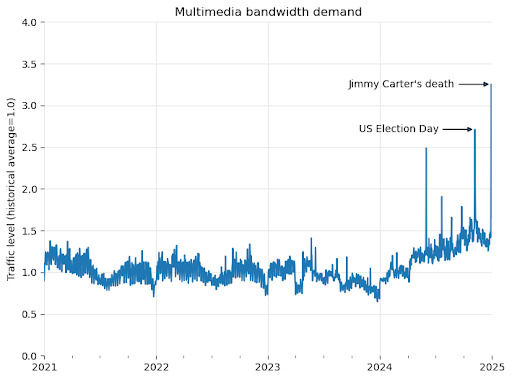
The graph below shows Wikimedia Commons' bandwidth over time. It has been steadily increasing since early 2024 and shows no signs of slowing down. This increase in baseline bandwidth leaves less room for sudden events, such as the presidential election or the death of former President Jimmy Carter , and a significant portion of time and resources are spent serving traffic other than human users.
The Wikimedia Foundation serves content to users through a global network of data centers . When content is requested, the Wikimedia Foundation sends it from a core data center and stores or caches it in the data center closest to the user, so that if the same content is requested multiple times, it is displayed quickly and seamlessly. On the other hand, if content has not been requested for a while, it is sent from the core data center to the regional data center and then to the user.
While human users tend to browse more of a particular popular topic, crawlers read many pages at once and also visit less popular pages. This results in an increase in the amount of data sent from the core data center, which increases costs in terms of resource consumption. According to the Wikimedia Foundation, an analysis of the traffic flowing into the core data center found that at least 65% was due to crawlers.
'These crawler traffic surges are causing constant chaos for our site reliability team, and we need to block these overwhelming bot traffic before it harms human users,' the Wikimedia Foundation said. 'Our content is free to use, but our infrastructure is never free. We need to act immediately to re-establish a healthy balance.'

Related Posts:





in AI, Software, Web Service, Posted by log1r_ut