The laws of scaling AI have reached their limit, and the situation in which 'increasing training data or the amount of training will improve AI performance' has already ended.
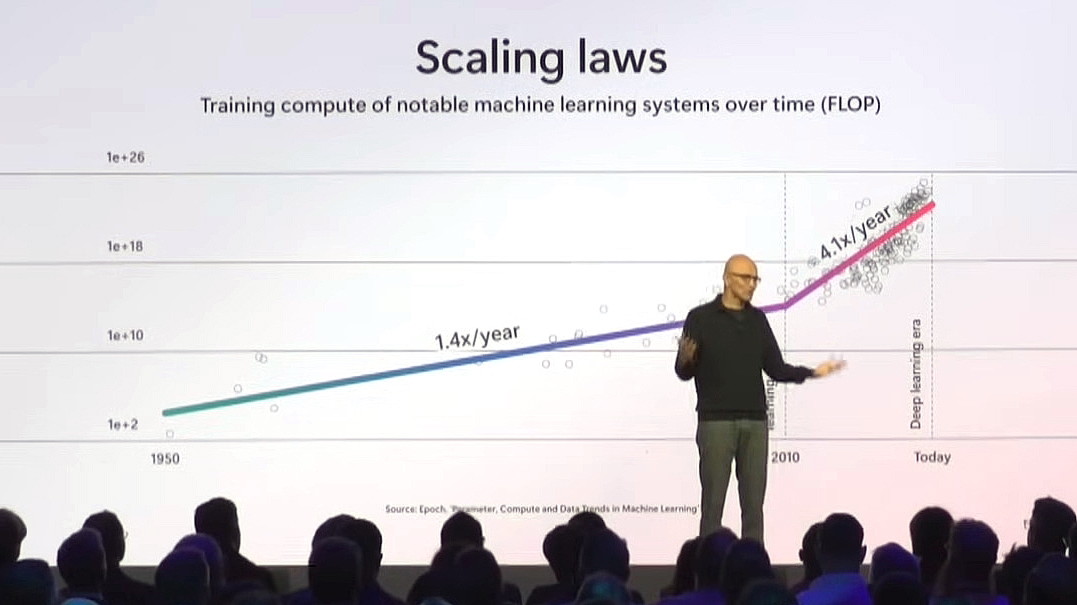
The AI scaling law is a law
The new AI scaling law shell game - by Gary Marcus
https://garymarcus.substack.com/p/a-new-ai-scaling-law-shell-game
According to Marcus, the meaning of the term 'scaling law' continues to change, and the scaling laws spoken of at the time of writing are roughly divided into three types. The first is similar to the one proposed by OpenAI, which is 'the longer the learning time, the stronger the AI's performance,' the second is 'the longer the inference time, the stronger the AI's performance,' and the third is 'the longer the time spent on additional learning of a trained AI model, the stronger the AI's performance.'
Of the three scaling laws, the law that 'the longer the learning time, the stronger the AI performance' is being denied by AI companies. For example, OpenAI CEO Sam Altman said in April 2023 that 'I believe the era of large AI models (that rely on scaling laws) is over.'
The rule that 'the longer the inference time, the stronger the AI performance' is famously mentioned by Microsoft CEO Satya Nadella in a speech in October 2024. You can watch CEO Nadella's speech in the video below.
Satya Nadella AI Tour Keynote: London - YouTube
OpenAI's ' OpenAI o1 ' is famous as an AI that improves performance by lengthening the inference time. OpenAI o1 takes longer to infer than GPT-4o, but has higher performance, and it was promoted for scoring higher than GPT-4o in 54 of the 57 tests. However, on the other hand, it shows that it can only achieve performance equal to or lower than GPT-4o in 3 of the 57 tests.
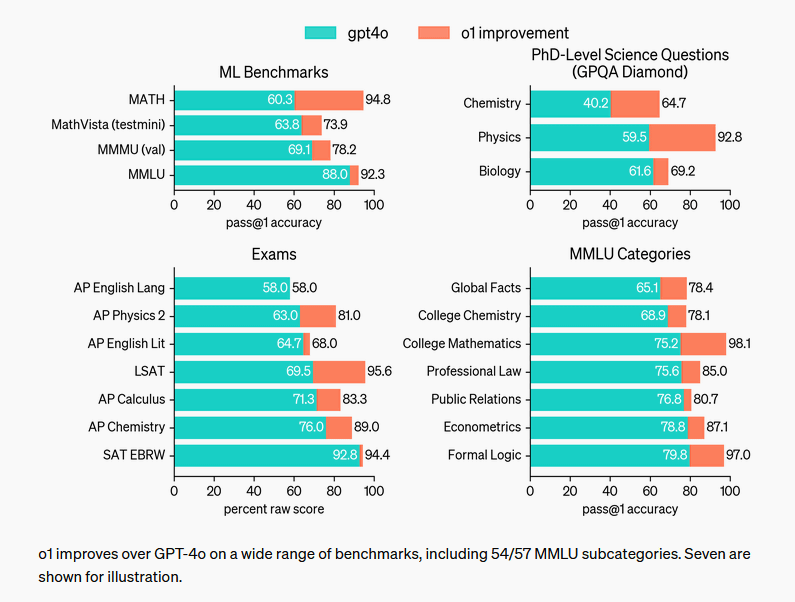
GPT-4 showed a dramatic improvement in performance compared to GPT-3, but OpenAI o1 did not show such a large improvement in performance. Based on these facts, Marcus points out that the law that 'the longer the inference time, the stronger the AI performance' also breaks down.
Regarding the third principle, 'the longer you spend on additional training of an already trained AI model, the stronger the AI's performance will be,' Marcus said, 'This is like saying, 'If I tweak a few parameters, I don't know how much it will improve, but I think it will improve performance,' so it's not really a principle.'
In addition, companies that are advancing AI research and development are continuing to make capital investments even as the limits of scaling laws are whispered about. For example, Meta has revealed that it is using more than 100,000 NVIDIA H100s to train next-generation AI models . In addition, xAI, an AI company founded by Elon Musk, is also operating an AI learning cluster equipped with more than 100,000 H100s and is expanding its scale. On the other hand, it has been pointed out that operations in data centers where hundreds of thousands of AI chips are in operation are becoming more complicated due to the impact of chip cooling and fault management.
Elon Musk's AI company 'xAI' has started operating the AI learning cluster 'Colossus' equipped with 100,000 NVIDIA H100s, and is scheduled to complete an 'AI learning cluster equipped with 200,000 H100s' within a few months - GIGAZINE

Related Posts:







