Major daily newspaper The New York Times files lawsuit against OpenAI and Microsoft for copyright infringement

New York Times Sues OpenAI and Microsoft Over Use of Copyrighted Work - The New York Times
https://www.nytimes.com/2023/12/27/business/media/new-york-times-open-ai-microsoft-lawsuit.html

The New York Times sues OpenAI and Microsoft for copyright infringement - The Verge
https://www.theverge.com/2023/12/27/24016212/new-york-times-openai-microsoft-lawsuit-copyright-infringement
The New York Times wants OpenAI and Microsoft to pay for training data | TechCrunch
https://techcrunch.com/2023/12/27/the-new-york-times-wants-openai-and-microsoft-to-pay-for-training-data/
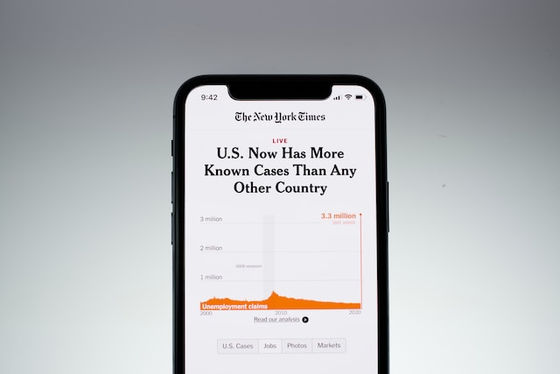
The New York Times claims:
Large-scale language models (LLMs), which form the basis of generative AI such as OpenAI's ChatGPT and Microsoft's Copilot, use content from The New York Times for training.
This allows the AI to mimic the New York Times' style of expression, creating content that directly competes with the New York Times.
By using AI to generate content that competes with The New York Times's, the newspaper is undermining its relationship with its readers and taking away revenue sources such as subscription fees, licensing fees, advertising, and affiliate revenue.
In its complaint, The New York Times also argues that 'AI models threaten the provision of quality journalism by undermining news organizations' ability to protect and monetize their content. ' It also criticized Microsoft and OpenAI, saying, 'Through Bing Chat (Copilot) and ChatGPT, Microsoft and OpenAI are attempting to free ride on The New York Times' significant investment in journalism by using our content to build alternative products without our permission or payment.'
The New York Times also pointed out that 'Microsoft and OpenAI made a lot of money from the release of AI models trained on New York Times content.' The New York Times has been negotiating with Microsoft and OpenAI to pay them a fair fee for using its content without permission, but 'no resolution has been reached.'
In response, OpenAI spokesperson Lindsay Held said, 'We respect the rights of content creators and owners and are committed to working with them to ensure they benefit from AI technology and new revenue models,' and 'Our ongoing dialogue with The New York Times has been productive and constructive, so we are surprised and disappointed by this development. Like many other publishers, we hope to find a mutually beneficial way to work together.' Microsoft did not respond to The Verge's request for comment.
The New York Times is seeking billions of dollars in damages and has also asked the court to block Microsoft and OpenAI from using New York Times content to train AI models and to remove New York Times content from training datasets.

The New York Times is one of the news organizations that blocked OpenAI's web crawler in 2023. This prevents AI development companies from collecting content from websites and using it to train AI models. In addition to the New York Times, media outlets such as the BBC, CNN, and Reuters have also blocked OpenAI's web crawler.
Meanwhile, other media outlets are allowing OpenAI to use their content by paying them. Axel Springer, a major German media company that owns media outlets such as Politico and Business Insider, signed a contract with OpenAI in December 2023 to allow ChatGPT to obtain data directly from Politico and Business Insider. The Associated Press also signed a contract to allow OpenAI to train AI models based on news articles.
AP, Open AI agree to share select news content and technology in new collaboration: https://t.co/MnqRD3HBHe
— AP CorpComm (@AP_CorpComm) July 13, 2023
Continued
OpenAI reveals that it mistakenly deleted evidence data in copyright lawsuits - GIGAZINE

Related Posts:







in Note, Posted by logu_ii