1960s chatbot 'ELIZA' defeats OpenAI's 'GPT-3.5' in Turing test

As a result of the ``
[2310.20216] Does GPT-4 Pass the Turing Test?
https://arxiv.org/abs/2310.20216
1960s chatbot ELIZA beat OpenAI's GPT-3.5 in a recent Turing test study | Ars Technica
https://arstechnica.com/information-technology/2023/12/real-humans-appeared-human-63-of-the-time-in-recent-turing-test-ai-study/
In a study titled ``Will GPT-4 pass the Turing test?'' researchers at the University of California, San Diego pitted the chatbot ``ELIZA'' and OpenAI's ``GPT-4'' and ``GPT-3.5'' against humans. We tested how well humans can distinguish between machines.
``ELIZA'' is software created by computer scientist Joseph Weizenbaum in the 1960s, and is a precursor to chatbots that responds to human words. Based on human language, it responds as if it were having a conversation, such as 'What is it about?' or 'Please tell me in detail,' but it quickly becomes confused if you use slightly complex words.

Researchers gave GPT-3.5 and GPT-4 a command sentence (prompt) to ``act like a human'' and instructed them to convince the other person that they are human.
The researchers then launched a website called ``turingtest.live'' and conducted Turing tests on the Internet. Humans who become participants through this site are assigned to either an 'interrogator' or a 'witness.' The interrogator interrogates the other person to see if the other person is a machine, and the witness, on the other hand, asks the other person whether or not they are a machine. I was instructed to convince them that
The witnesses included ELIZA, GPT-3.5, and GPT-4 in addition to humans, so the human interrogator had to determine whether the other party was a machine through dialogue.
Below is a graph showing whether the interrogator was able to identify the machine. Interrogators correctly identified their interrogators as humans 63% of the time. The probability that the interrogator mistook ELIZA for a human was 27%, which was higher than GPT-3.5's 14%. GPT-4 varied depending on the prompt and was up to 41%.
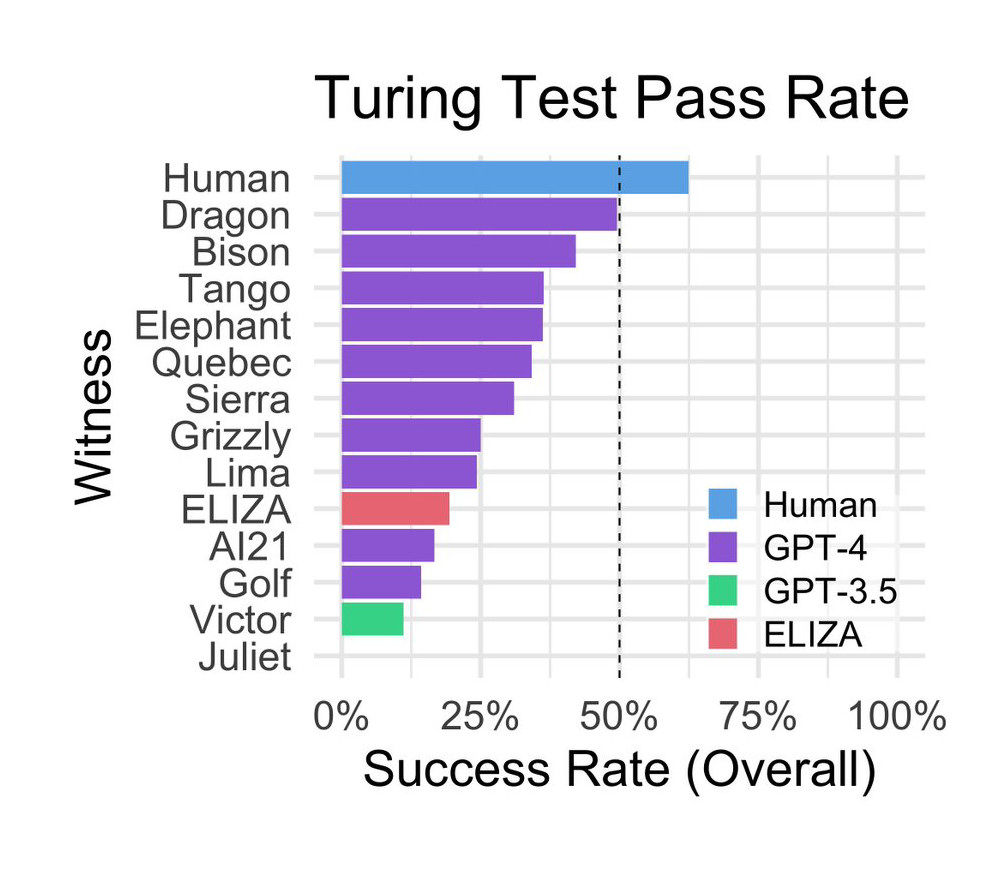
GPT-3.5 is the base model for the free version of ChatGPT and is specially configured by OpenAI to not present itself as a human. The researchers pointed out that ``GPT-3.5 and GPT-4 are tweaked to have a formal tone. We tried to change this with prompts, but there were limitations.''
Regarding the result that ELIZA unexpectedly outperformed GPT-3.5, ELIZA tends to give 'conservative' answers and often does not provide incorrect information or unclear knowledge, which is a difference between GPT and ELIZA. It is thought that he may have appeared to humans as an ``uncooperative person'' because he did not show any kind of artificial kindness or friendly attitude that might be expected from others.

Researchers say that by adjusting the prompts, GPT-3.5 and GPT-4 may have higher success rates.
Related Posts: