GPT-4 Turbo is lower than GPT-4 in the benchmark, but there may be a problem with the content of the benchmark

OpenAI, which develops AI such as ChatGPT, has developed a coding support tool using GPT-4 regarding the 'GPT-4 Turbo' announced at the developer event 'DevDay' held on November 6, 2023. Mentat ran a benchmark and found that the performance was lower than GPT-4.
Benchmarking GPT-4 Turbo - A Cautionary Tale | Mentat
Details about GPT-4 Turbo are explained in the article below. OpenAI stated that GPT-4 Turbo has improved performance over GPT-4.
OpenAI announces GPT-4 upgraded large-scale language model ``GPT-4 Turbo'', has knowledge until April 2023, context window is 128K, and price is modest - GIGAZINE

Mentat compared the performance of GPT-4 and GPT-4 Turbo by acquiring 122 practice problems from the programming learning site Exercisecism and having them solve the practice problems with the same prompts through Aider . If an appropriate answer was not returned in the first prompt for each problem, a second prompt was sent along with an error message saying ``Please correct the code'' and the correct answer rate was measured.
GPT-4 answered 86 questions out of 122 correctly, exceeding a 70% correct answer rate. On the other hand, GPT-4 Turbo answered 84 out of 122 questions correctly, with a correct answer rate of only 68.8%. Based on this result alone, it can be said that the performance is equivalent, but Mentat states that the breakdown of correct answers is different. GPT-4 answered 76 questions correctly on the first prompt and 10 questions on the second prompt, while GPT-4 Turbo answered only 56 questions on the first prompt and answered 28 questions correctly. was the correct answer on the second prompt.
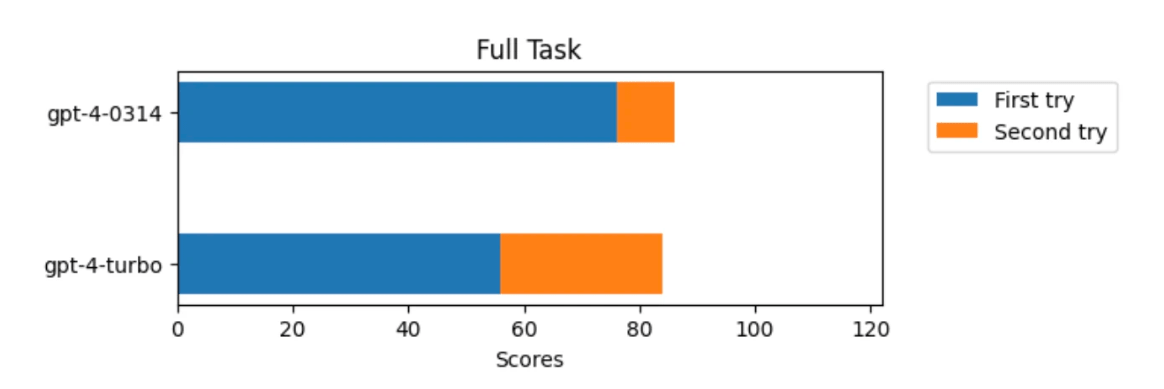
Mentat speculates that the reason for this phenomenon is that GPT-4's training data includes the content of practice problems, and that memory was lost when it was downsized to GPT-4 Turbo. Masu.
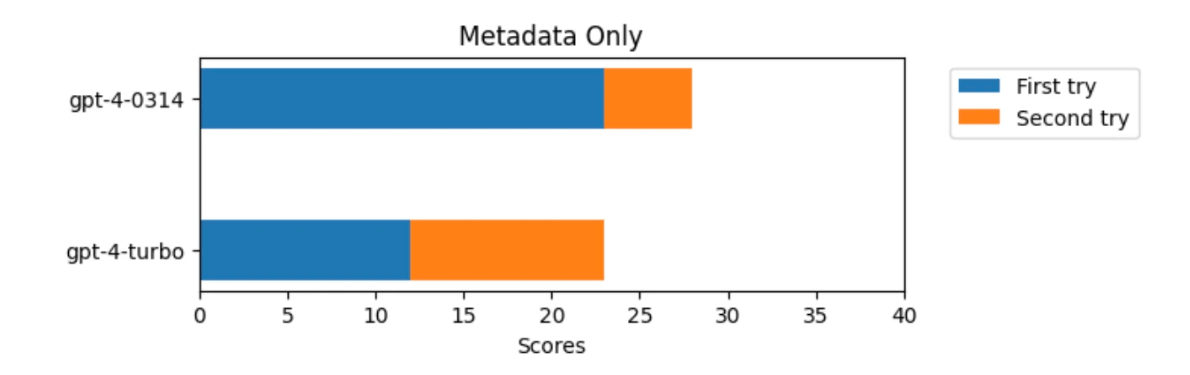
In fact, even when we removed the practice problem instructions and only presented the problem title and function placeholder, GPT-4 answered 57.5% of the questions correctly on the first prompt, including the number of correct answers on the second prompt. The correct answer rate reached 70%. On the other hand, GPT-4 Turbo has a correct answer rate of 30% on the first try, and 57.5% when combined with the second time, indicating that it remembers fewer questions than GPT-4.
Mentat also mentioned the following post posted on X (formerly Twitter) about trying to solve the SAT (University Aptitude Test) with GPT-4 and GPT-4 Turbo, and the GPT-4 score was high. He states that this may be because he memorized the exam questions during training.
OpenAI claims GPT4-turbo is “better” than GPT4, but I ran my own tests and don't think that's true.
— Jeffrey Wang (@wangzjeff) November 7, 2023
I benchmarked on SAT reading, which is a nice human reference for reasoning ability. Took 3 sections (67 questions) from an official 2008-2009 test (2400 scale) and got the… pic.twitter.com/LzIYS3R9ny
Although benchmarking on the data used during training is valuable to ensure that the AI responds properly and in the correct format, and to compare fine-tuned models to each other, it is important to benchmark against the same data set used during training. It cannot be said that a proper evaluation can be made when comparing models trained with or reduced models. Mentat says that better benchmarks are needed to evaluate GPT-4 Turbo, and they are already building tests based on commits to the open source repository that were made after the training was completed.
Related Posts:







in Software, Posted by log1d_ts