Anyone can challenge 'BabyLM Challenge', a challenge to newly train a large language model with only 'the amount of words that human children hear'
It is commonly believed that the performance of large-scale language models used in chat AI increases as the number of parameters and the amount of training data increases. The challenge ' BabyLM Challenge ' is being held.
babylm.github.io
In creating a large-scale language model, there is a process called pre-training at the very beginning. In pre-learning, training is performed by inputting a sentence and guessing the following word, and the large-scale language model will be able to create sentences through this training.
The amount of words used for training is increasing year by year, and BERT in 2018 was trained with 3 billion words of data, but RoBERTa in 2019 was trained with 30 billion words, GPT-3 in 2020 with 200 billion words, And Chinchilla in 2022 was trained on 1.4 trillion words of data. In this way, the performance of large-scale language models has also improved, but as shown on the left side of the figure below, humans have acquired the ability to freely manipulate words, even though they have heard only 100 million words in the 13 years since they were born. can be attached to
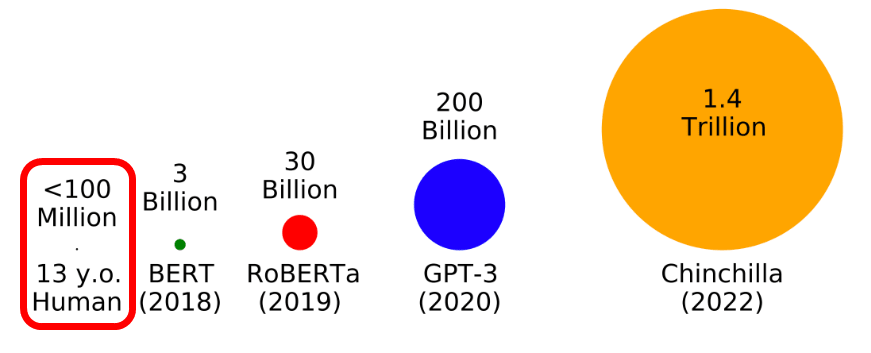
Therefore, in January 2023, a group of young scholars studying natural language processing launched the `` BabyLM Challenge ''. The BabyLM Challenge is a challenge to train a language model by limiting the amount of data to 100 million words, which is the amount of words heard by a 13-year-old child.
According to the organizers, the BabyLM Challenge can be used as a testing ground for new techniques to improve data efficiency, and new techniques appearing here will improve techniques for modeling languages with small amounts of data, and will be used in general in natural language processing. It is said that there is a possibility that it will be used for
Also, in the BabyLM Challenge, not only is the amount of data limited to 100 million words, but the training data is a transcription of spoken words such as speech. It is said that researching methods of training language models using the same type and amount of data that humans receive will also help to understand why humans can learn languages efficiently.
Anyone can participate in the BabyLM Challenge, and the training dataset has been uploaded to GitHub . The deadline for submitting models and results is July 15, 2023, and the deadline for submitting papers is August 1, 2023.
Related Posts:







in Software, Posted by log1d_ts