Claims that a phenomenon similar to `` overlearning '', which is too optimized for learning data and cannot achieve its original purpose, is occurring not only in AI but also in society as a whole

Too much efficiency makes everything worse: overfitting and the strong version of Goodhart's law | Jascha's blog
https://sohl-dickstein.github.io/2022/11/06/strong-Goodhart.html
When considering overfitting, which is widely seen in the field of machine learning, it is important to say that ``an AI created for a specific goal cannot be trained with the goal itself, so a 'proxy' similar to the goal is used for training.'' It's a point. For example, if the goal was to 'improve the accuracy of a new image classification model', it would be illegal to train the model on a test dataset to measure this goal achievement, so a proxy training dataset instead do the training in Also, the metric for measuring accuracy improvement during training is set as a proxy goal using the training dataset instead of the actual test dataset.
The image below shows model learning and target improvement, with the rainbow line showing the target improvement and the black line showing the proxy improvement. Once training on the actual proxy dataset begins, the goal of improving the actual model accuracy will improve as the proxy goal improves.
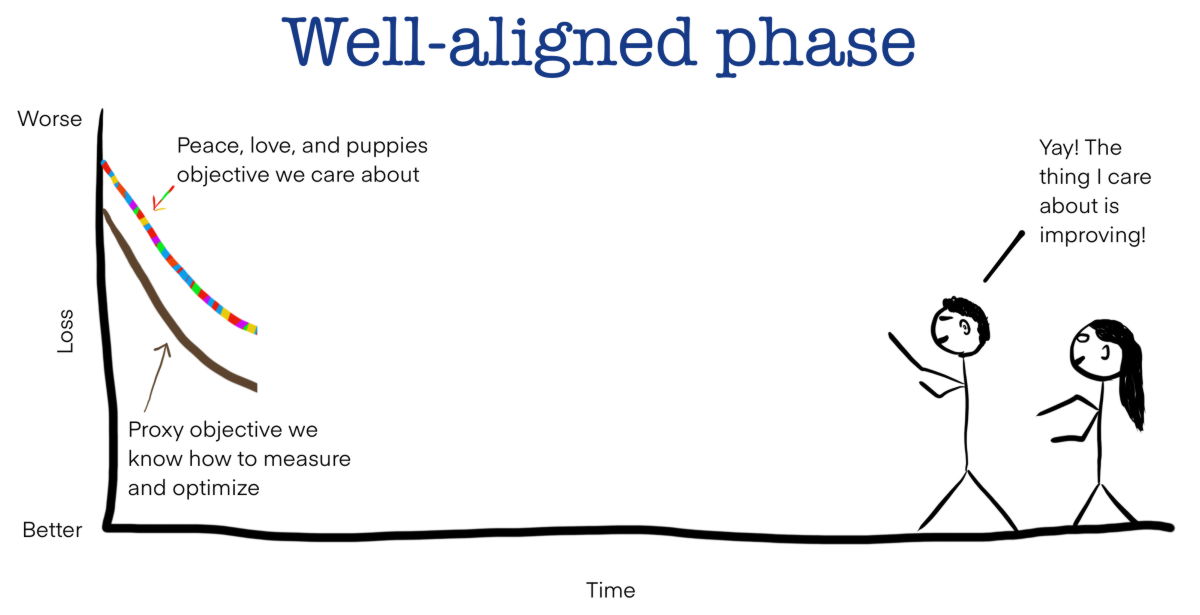
However, at some point as the optimization progresses, the similarity between the proxy and the actual goal is exhausted, and a phenomenon occurs in which the improvement of the proxy progresses while the improvement of the goal stagnate. In the field of machine learning, this phenomenon is called overfitting.

If your goals are already stagnant and you continue to optimize your proxy, your goals may start to get worse. Overfitting problems are very common in the machine learning field and appear almost regardless of what the goals and proxies are and the model architecture used.
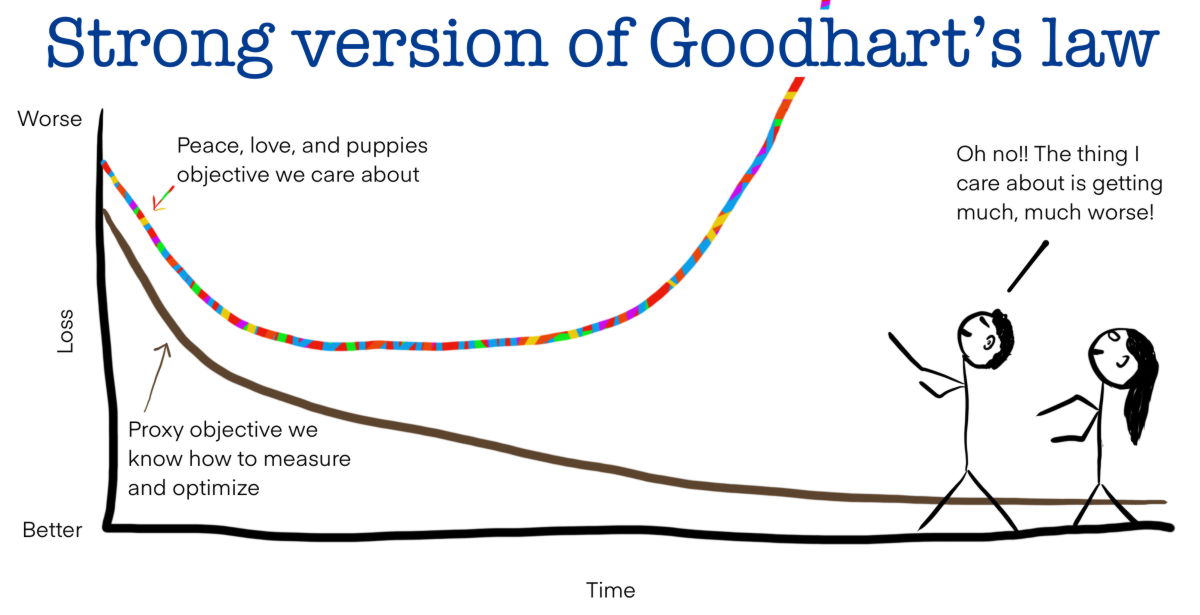
Sohl-Dickstein points out the similarity to
In machine learning, the state where the improvement of the goal stops as the proxy optimization progresses is certainly similar to Goodhart's law that 'the scale becomes useless when the goal becomes'. In addition, Sohl-Dickstein calls the state that ``if the optimization progresses with the scale as the goal, the initial achievement of the goal deteriorates'' as ``a powerful version of Goodhart's law''. .

Sohl-Dickstein argues that a stronger version of Goodhart's Law goes beyond machine learning and can be applied to socioeconomic problems. As examples of strong versions of Goodhart's Law, Sohl-Dickstein cites the following:
Goal: better educate children
Proxies: performance measures with standardized tests
Consequence: Schools will sacrifice teaching the basic academic skills they want to measure in the test in favor of teaching “skills to answer tests correctly.”
Goal: advance science
Proxies: pay bonuses for publishing scientific papers
Consequences: publication of inaccurate or sensitive results, widespread collusion between reviewers and authors
Goal: good life
Proxies: maximizing reward pathways in the brain
Consequences: Addiction to drugs, gambling, spending time on Twitter
Goal: Election of leaders who act in the interests of the people
Proxies: Picking the Leader with the Most Popular Votes
Result: Selection of leaders who are good at manipulating public opinion
Goal: Allocation of labor and resources based on social needs
Proxy: Capitalism
Consequence: Growing gap between rich and poor

Sohl-Dickstein proposes that approaches to avoiding overfitting in machine learning may be useful to solve the social problems posed by stronger versions of Goodhart's law. Below is an example of Sohl-Dickstein actually applying an approach to avoid overfitting in machine learning to real-world problems.
Countermeasure: Align proxy goals with more desired outcomes
One way to avoid overfitting in machine learning is to carefully collect training data that is as similar as possible to the test. Even in the real world, we can change controllable proxies such as laws, incentives, and social norms, and adjust them to encourage behavior more suited to goals.
Countermeasure: Set a penalty for regularization
Countermeasure: Inject system noise
To prevent overfitting, machine learning sometimes deliberately injects noise into the training data and parameters of a model. In the real world, ``to secure diversity by adding randomness to the company's recruitment exam'' and ``to randomize each class instead of notifying the test schedule in advance, it is possible to avoid excessive cramming before the test. It is said that there are possible introduction examples such as 'prevent from doing' and 'set a time lag in the processing system of the stock exchange and invalidate transactions that exceed the human reaction speed'.

Remedy: Stop learning early
In machine learning, the gap between the predicted value and the correct value is measured as 'loss', but at the same time, an index called 'validation loss' is measured, and when the validation loss begins to deteriorate Other losses Even if is improving, it is possible to prevent overlearning by stopping learning. Sohl-Dickstein cites examples such as ``stopping all market trading if stock price movements exceed a certain value'' and ``shutting down the press for 48 hours before the election.''
Countermeasure: Limit model capacity
In machine learning, overfitting can also be prevented by making the model capacity very small. In the real world, there are things like `` setting an upper limit on election funds '', `` deciding the maximum number of people who can work in a particular company '', and `` limiting the parameters that AI can use and the performance of training computers ''.
Countermeasure: Expand model capacity
Contrary to the measure of 'limiting the capacity of the model', it seems that there are cases where the reduction of the goal achievement can be avoided by making the model very large. In the real world, things like 'erasing all privacy and making all information about individuals and organizations available to everyone' and 'developing complex and arcane financial instruments that are vested on various timescales'. , but these examples may not necessarily be useful to people. Sohl-Dickstein also said that erasing privacy is 'dystopian in my view.'

Related Posts:








in Note, Posted by log1h_ik