The results of investigating where 12 million images were obtained from the data set of the image generation AI ``Stable Diffusion'' composed of 2.3 billion images will be released

The image generation AI '
Exploring 12 Million of the 2.3 Billion Images Used to Train Stable Diffusion's Image Generator - Waxy.org
https://waxy.org/2022/08/exploring-12-million-of-the-images-used-to-train-stable-diffusions-image-generator/
Simon Willison's Weblog
https://simonwillison.net/
Baio, former CTO of Kickstarter and owner of Waxy.org , a blog that primarily writes about Internet culture, intellectual property rights issues, art and technology, announced on August 30, 2022. We have published the results of our research on Stable Diffusion image learning data. According to Mr. Bio, Stable Diffusion is more transparent in its model training method than other AIs that generate and analyze images. However, it is difficult to identify the dataset that is actually training the images, and Bio worked with friend and engineer Simon Willison to identify the 2.3 billion images used to train Stable Diffusion. We acquired about 12 million image data, which is only 0.5% of the total.
The collected data sets can be viewed at the following sites.
laion-aesthetic-6pls: images: 12,096,835 rows
https://laion-aesthetic.datasette.io/laion-aesthetic-6pls/images
On the site that listed the dataset, in addition to information such as text and size associated with the image, the domain of the site that collected the image was also listed. As a test, visit the URL that is the reference source of the salad image.
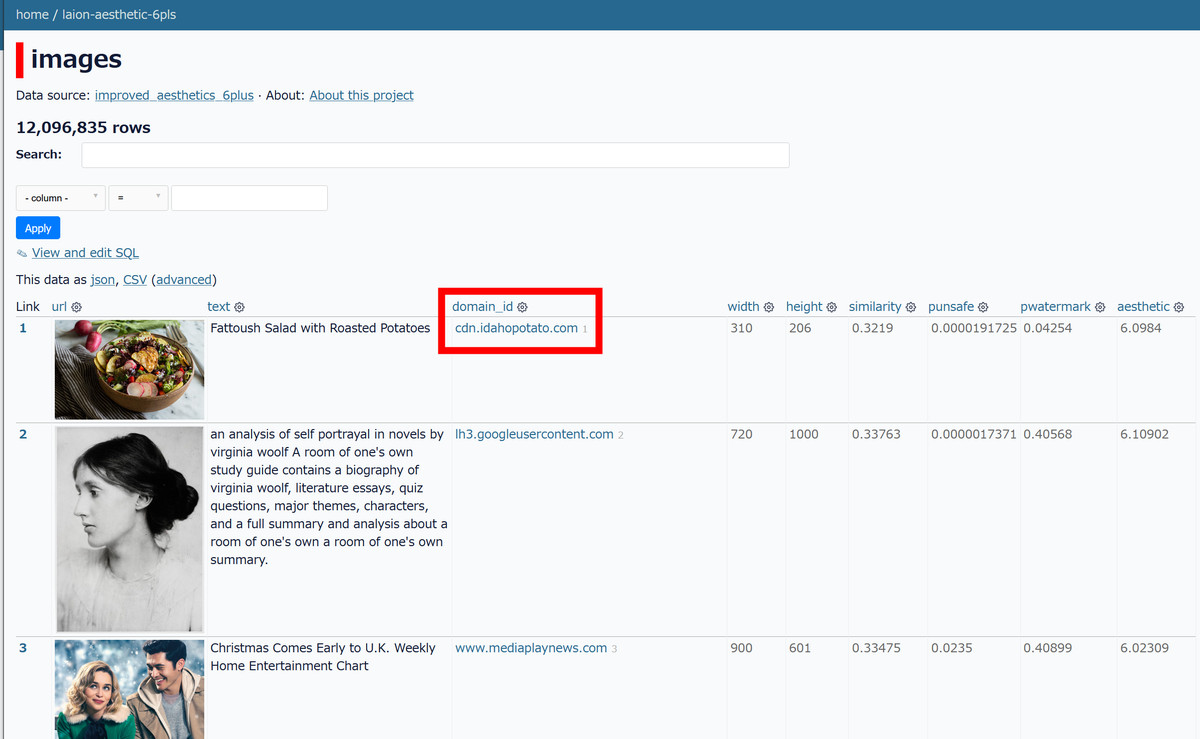
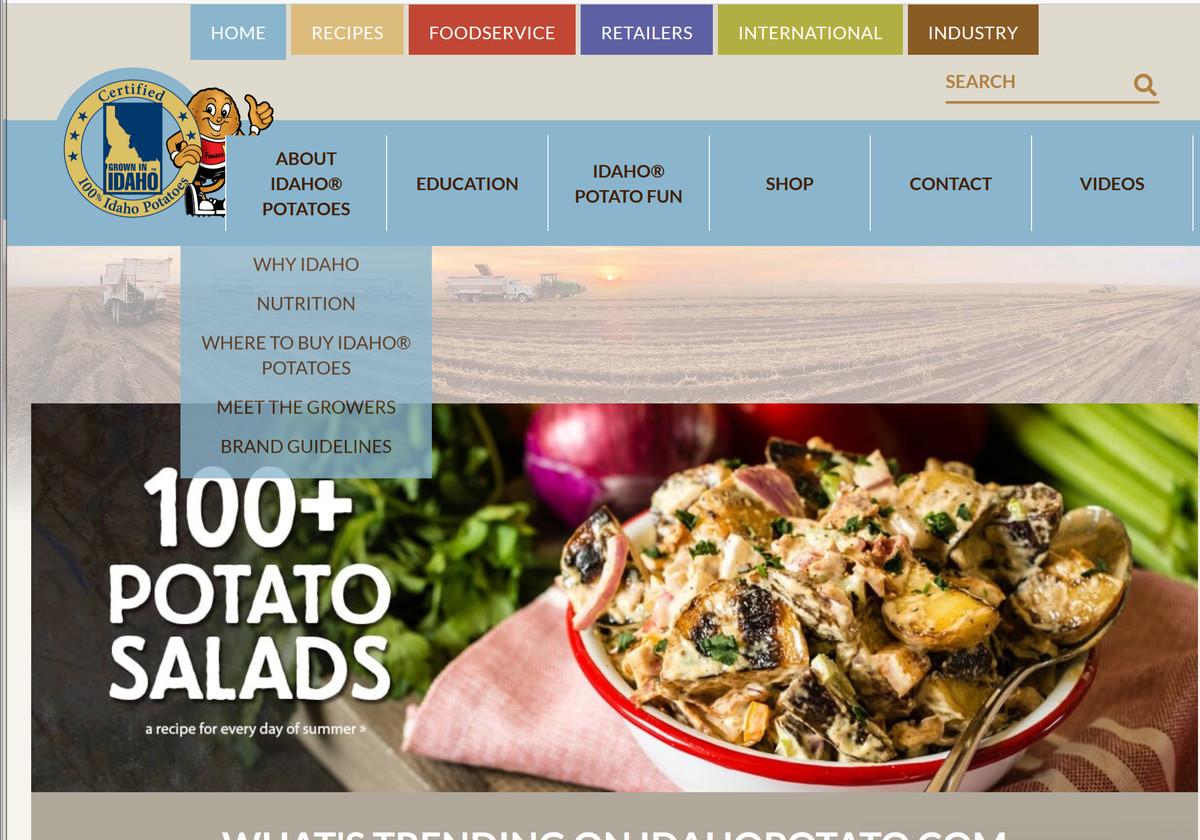
Then, I transitioned to a potato portal site called 'Idaho Potato'. Here, in addition to information about Idaho potatoes, ideas such as how to cook and store potatoes, recipes using Idaho potatoes are also published.
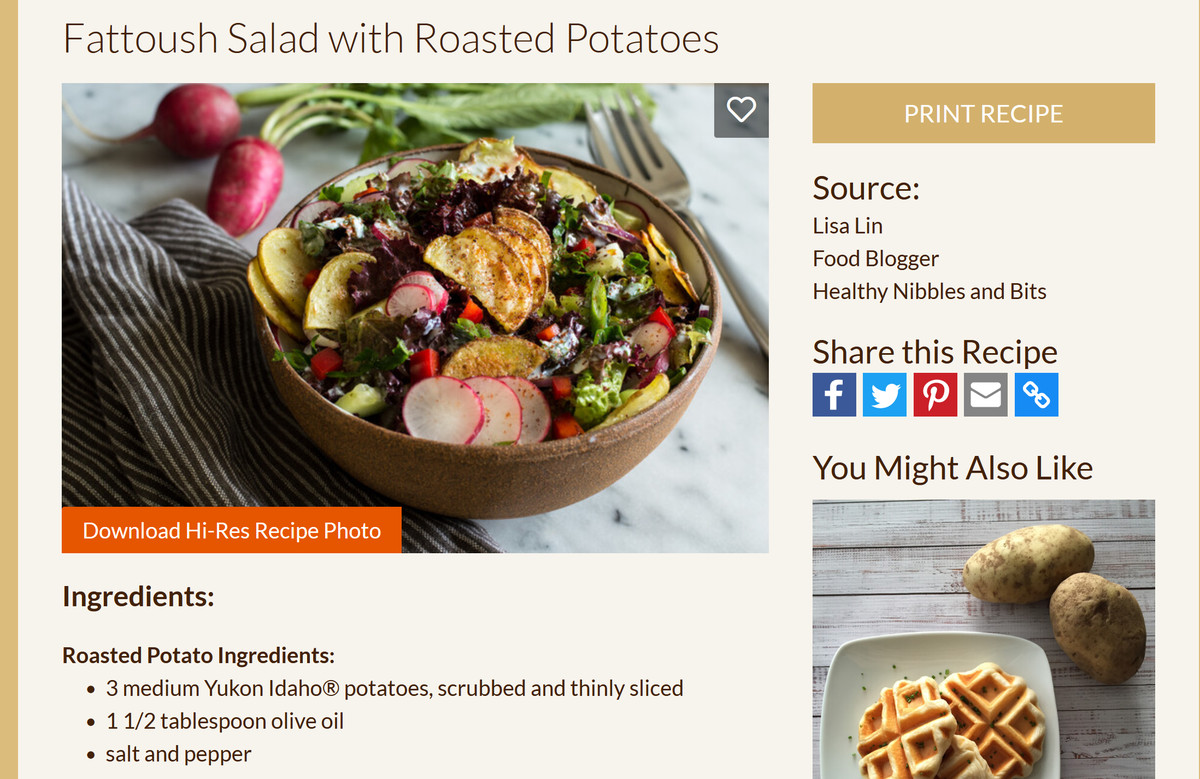
When I searched for the recipe, I found a photo of 'Roasted potato fattoush salad' that is the same as the image in the dataset list. In this way, you can tell 'Is the image here used for AI learning and automatic image generation?'
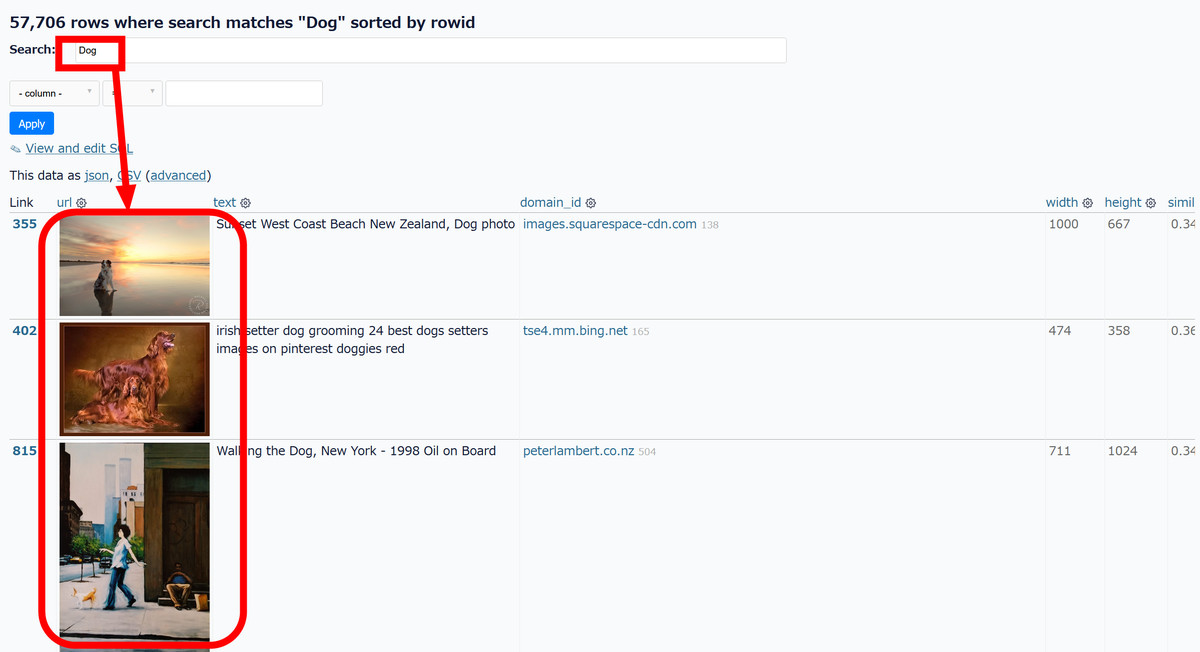
You can also search for images by keyword in the dataset list. When I tried entering 'Dog' in 'Search', various dog images were displayed.
According to Baio, Stable Diffusion is trained from three large datasets collected by LAION , a nonprofit organization that publishes open AI networks for free. LAION's image dataset is built from Common Crawl , a non-profit organization that extracts data from billions of web pages every month and releases it as a massive dataset. In the training of Stable Diffusion, the image data was narrowed down from the LAION data set with conditions such as ``resolution is sufficiently high'', ``aesthetic score is ``5'' or higher, and ``no watermark is included'', and a sample was constructed. I'm here.
Mr. Bio tagged the acquired Stable Diffusion data samples by distinguishing ``which site the data was extracted from'' for each domain. According to Mr. Bio, the images extracted from 100 types of domains accounted for about 47%, and it was found that 8.5% of the total dataset was extracted from Pinterest in particular. In addition, 6.8% of the images in blogs using WordPress accounted for 6.8%, and image sharing sites such as Flickr, DeviantArt, and Tumblr each collected tens of thousands to hundreds of thousands of images. The platform has been a huge source of image data,' Baio said.
Images from shopping sites also make up a large percentage of the dataset. Fine Art America , which sells art prints and posters, had the second largest share, or 5.8%, of about 700,000, while Canadian e-commerce site Shopify had about 240,000, a website creation tool. It seems that a considerable amount was included in the data set, about 190,000 each from the Wix and Squarespace shop pages.
The collected datasets can also be viewed by artist. Mr. Bio searched for more than 1,800 artist names using `` (Google Docs) Encyclopedia of Hidden Artists ' ' and aggregated images that refer to the artist's name. As a result, the artist with the most hits for name searches in the dataset was Thomas Kinkade , who describes himself as the 'painter of light,' and contained 9,268 images. Artists in the dataset can also be searched by category, and when searching by narrowing down to the 'comic' category, Mr. Stan Lee of Marvel Comics was most frequently seen.
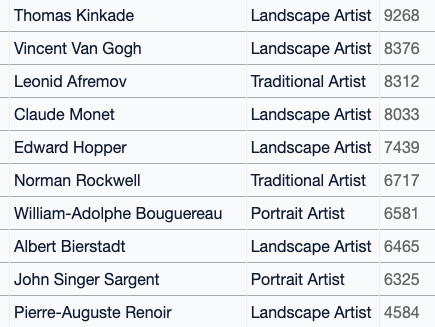
Similarly, when the names of celebrities were listed and counted, the most cited name was former President Donald Trump with about 11,000, followed by actress Charlize Theron with 9,576. About.

Finally, Mr. Bio also publishes the aggregate results for fictitious characters. The most popular ones here are Captain Marvel (4993), Black Panther (4395), Captain America (3155) and Marvel works. Next, Batman (2950) and Superman (2739) line up closely, and 'Star Wars' Luke Skywalker (2240) is more than Darth Vader (1717) and Han Solo (1013) Many images have been confirmed. In addition, 520 images of Mickey Mouse were collected, and it was ranked in the top 100 among the characters in the dataset. Aggregations for artists, celebrities, and characters are all aggregated from 0.5% of the total 2.3 billion data set, so just because you search the list and don't get hits, it doesn't mean they're not in the data set. need to be careful.
Mr. Willison, who cooperated with Mr. Bio, said on his blog, ``I think that the ethical issues of AI will become difficult as the images used for training are no longer black boxes.'' According to Willison, each image in the training set contributes only a small fraction of the automatically generated image, merely fine-tuning the weighting of the numbers spread across the network. However, those who created the original images extracted as datasets may view AI as a direct threat to their lives. Mr. Willison describes people with such a feeling as 'AI vegans', and while respecting vegans, he respects people who cannot accept the values of image generation AI, just like he eats meat. also shows their willingness to try out the wonderful possibilities of image generation AI.
Related Posts:





in Web Service, Design, Creation, Posted by log1e_dh