Report on why Roblox, with more than 100 million monthly active users, caused a four-day failure

Roblox, an online gaming platform that allows you to create games and play games created by others, was out of service for four days from October 28th to 31st, 2021 due to a failure. Roblox has put together a report on the official blog about what exactly caused it and how it recovered.
Roblox Return to Service 10 / 28-10 / 31 2021 --Roblox Blog
The following is a brief summary of what kind of obstacle it was.
・ Service downtime is 73 hours
・ There are two root causes
1: Performance deteriorates due to enabling new functions of Consul in a high load environment
2: BoltDB performance deteriorates dramatically due to specific load conditions
・ The reason why the service outage lasted for a long time was because we were investigating another cause and it was delayed to reach the root cause.
-An important monitoring system that can better understand the cause of the outage has been affected by the outage.
・ Furthermore, it took time to start up from the state where the service was completely stopped.
Roblox's services run in Roblox data centers, where their own systems are built on their own hardware, with more than 18,000 servers and 170,000 containers. In Roblox In order to manage this scale system of HashiCorp of ' Nomad ', ' Consul ', ' Vault a combination of the three service called' ' HashiStack things and are using.'
Nomad is a scheduling tool that determines which container runs on which node and which port, and Consul is a tool used for services discovery , health checks, session locks, KV stores, and more. Consul consists of 10 machines, 5 of which are read-only read replicas and 1 of the remaining 5 is elected leader by the Raft algorithm to manage synchronization. Consul's normal dashboard looks like this.
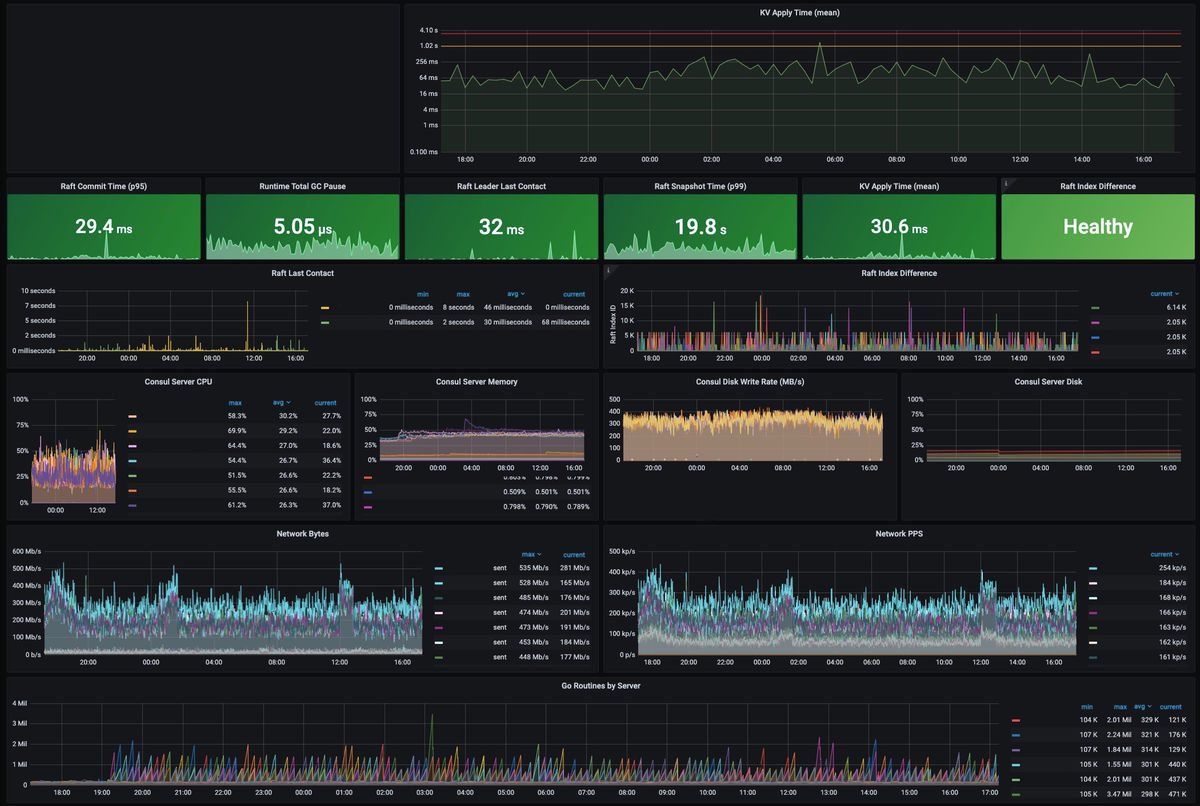
Roblox said that in the months leading up to a major failure, Consul was upgraded to add new streaming capabilities that could significantly reduce CPU and network bandwidth. Then, on the afternoon of October 28, the CPU load of Vault, a service that stores sensitive data, increased, and an investigation by engineers began.
Initial research found that Consul's write latency to the KV store, which should normally be less than 300 ms, has increased to 2 seconds. Hardware failures are not uncommon at Roblox scale, so the engineer team replaced Consul's cluster nodes to deal with it, but the performance continued to decline, and at 16:35 the number of players was higher than normal. It will be halved and eventually the system will be completely shut down.
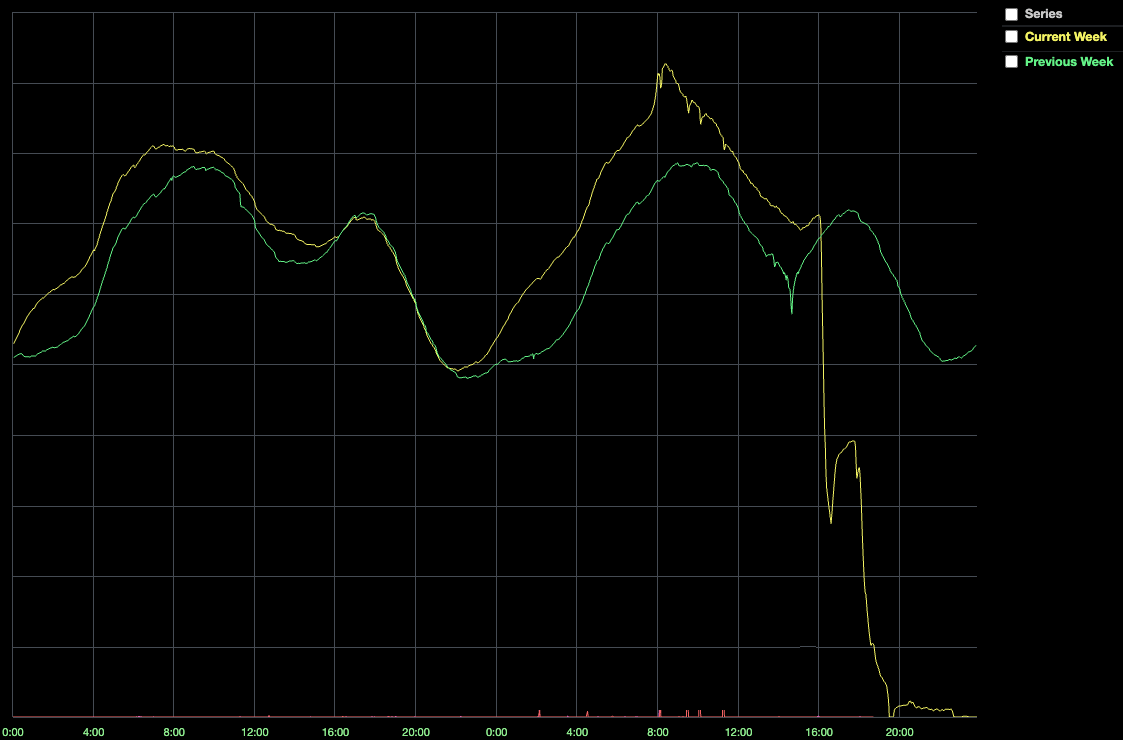
On Roblox's system, Consul was a single point of failure because if a service wanted to communicate with another, it would have to ask Consul where to connect. The team of engineers took the situation of a complete service outage and replaced all the nodes in the Consul cluster with more powerful machines, but things didn't improve.
The team then decided to roll back the Consul cluster to a pre-stop snapshot. Although the system configuration data is lost a little, the user data is safe and the lost configuration data can be restored manually, so it was judged that there was no problem. Immediately after resetting it worked fine, but Consul's performance started to slow down again and returned to its original state after 2 hours. At this point, 14 hours had passed since the failure occurred, but all that was known was that something was overwhelming Consul.
In order to find the root cause of the failure, the engineer team tried to reconfigure the system as small as possible. We reduced the Roblox service, which normally runs on hundreds of instances, to a single digit, disabled all non-essential elements, and launched the system. Due to the wide variety of changes, this process took several hours and restarted the system at 16:00 on October 29, 24 hours after the failure. However, around 2:00 am on October 30th, Consul's performance suffers again. After this, the team began to suspect that Consul itself was the cause, rather than 'something is overwhelming Consul.'
Examining the debug logs and OS metrics
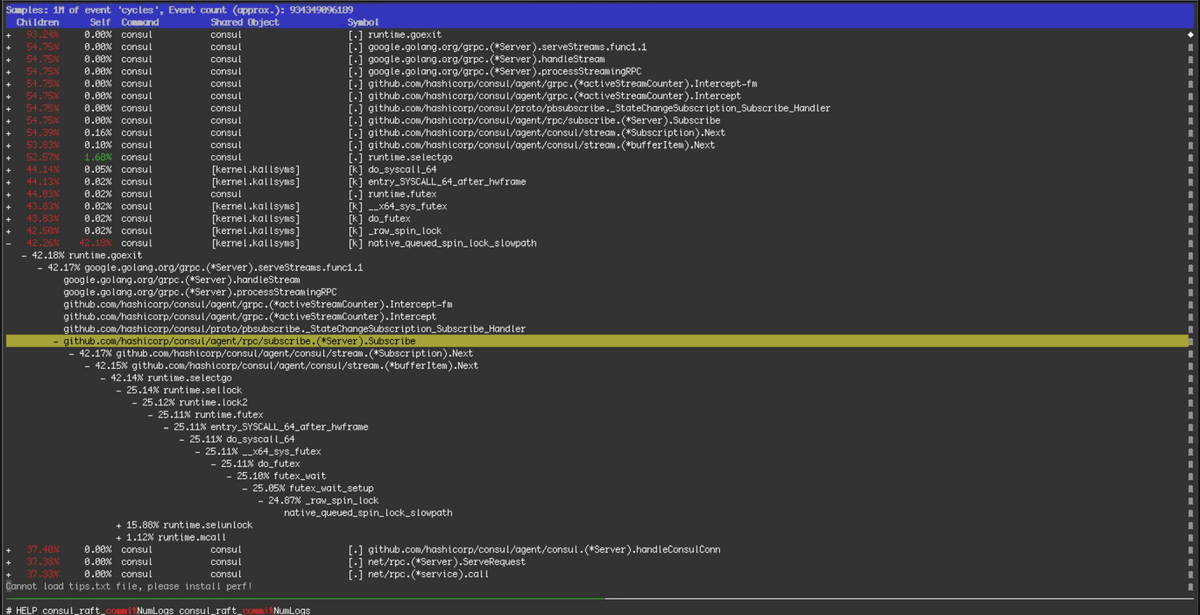
54 hours after the failure, the system became stable and the engineer team was able to focus on returning service. Roblox uses a common microservices pattern for its backend, with databases and caches at the bottom. The database was not affected by the failure, but there was a problem with the cache system. But because it's a cache, the team of engineers decided to redeploy it to get it back to normal.
However, since the cache system was built with an emphasis on 'incrementally injecting into a system that is already processing a large amount of traffic' rather than 'expanding the cache from scratch', it was built to expand the cache. It took a lot of time. Sixty-one hours after the failure, the Consul cluster and cache system became healthy, and the rest of the system was restored.
In order to avoid the system becoming unstable due to sudden processing of a large amount of traffic, the number of users was adjusted using DNS steering, and the recovery work was carried out step by step over the course of a day. All users had access to the service 73 hours after the failure.
Even after the system was normalized, Roblox and HashiCorp's team of engineers continued to investigate the root cause and make improvements to prevent recurrence. Consul's streaming protocol has been fixed, and important improvements include:
Eliminate 'circular dependencies' where tools for monitoring Consul depend on Consul
Since the tool for monitoring Consul depended on Consul, there was a lack of data for investigating the cause when a Consul failure occurred.
-Redundancy of back-end services
I was running all the Roblox backend services on a single Consul cluster, which caused a long-term failure like this one. In order to avoid this, it is said that expansion to another data center and availability zone is being carried out.
・ Consul load reduction
By splitting important services into separate dedicated clusters, the load on the central Consul cluster was reduced. In addition, it was possible to improve performance by removing a large number of obsolete KV stores.
・ Improvement of system startup procedure
Due to factors such as cache expansion and warming up, Roblox's service has been delayed. It is stated that it is implementing efforts to automate this launch process.
Related Posts:







in Software, Posted by log1d_ts