Chinese research team announces new AI 'Godo 2.0', number of parameters is 1.75 trillion, surpassing Google and OpenAI models

On June 1, 2021, a research team led by the
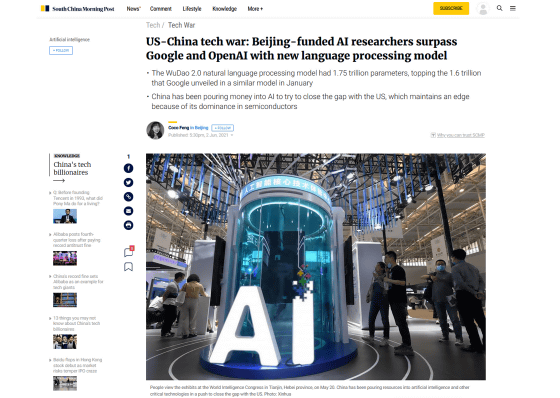
US-China tech war: Beijing-funded AI researchers surpass Google and OpenAI with new language processing model | South China Morning Post
https://www.scmp.com/tech/tech-war/article/3135764/us-china-tech-war-beijing-funded-ai-researchers-surpass-google-and
China's gigantic multi-modal AI is no one-trick pony | Engadget
https://www.engadget.com/chinas-gigantic-multi-modal-ai-is-no-one-trick-pony-211414388.html
China Says WuDao 2.0 AI Is an Even Better Conversationalist than OpenAI, Google | Tom's Hardware
https://www.tomshardware.com/news/china-touts-wudao-2-ai-advancements
Godo 2.0 is a deep learning model developed by more than 100 researchers belonging to multiple institutions, centered on the Beijing Jiyuan Artificial Intelligence Research Institute, a non-profit research institute. The number of parameters has reached 1.75 trillion, and 175 billion of the language processing model ' GPT-3 ' announced by OpenAI in June 2020 and up to 1 trillion of the language processing model 'Switch Transformer' developed by Google Brain. Researchers at the Beijing Jiyuan Artificial Intelligence Institute claim that it is more than 600 billion.
Parameters are variables defined by a machine learning model, and as learning evolves the model, the parameters are refined to allow for more accurate results. Therefore, in general, the more parameters the model contains, the more sophisticated the machine learning model tends to be.

Godo 2.0 is trained with a total of 4.9 TB of text and image data, and this training data contains 1.2 TB each of Chinese and English text. Also, unlike deep generative models that specialize in specific tasks such as image generation and face recognition, you can write essays and poems, generate supplementary sentences based on still images, and create images based on sentence explanations. It seems that it can also be generated.
'These sophisticated models trained on huge datasets require only a small amount of new data when used for specific functions,' said Blake Yan, an AI researcher in Beijing. This is because the knowledge that was once learned can be transferred to new tasks in the same way as. ' South China Morning Post reports that Godo 2.0 has already partnered with 22 companies, including smartphone maker Xiaomi.
Zhang Hongjiang, director of the Beijing Institute of Artificial Intelligence, said, 'A large-scale pre-learning model is one of the best shortcuts to general-purpose artificial intelligence,' said Godo 2.0 with a view to general-purpose artificial intelligence. Suggested.
In addition, the Chinese government has invested a large amount in Beijing Jiyuan Artificial Intelligence Research Institute, and it is said that 340 million yuan (about 5.85 billion yen) was provided in 2018 and 2019 alone. Technology competition between the United States and China is intensifying, with the

Regarding the announcement of Godo 2.0, tech media Tom's Hardware pointed out that the number of parameters is not always important for AI performance, but the amount and content of datasets are also important. For example, GPT-3 was trained with only 570GB of data, but this data was squeezed from a 45TB dataset by preprocessing. So, he insisted, 'The raw numbers associated with Godo 2.0 are impressive, but they may not indicate the performance of the model.'
Related Posts:







