Google develops new low-latency & offline usable speech recognition system

by mentatdgt
Text input by voice is becoming a common function installed in smartphones, but there should be many people who care about the time lag to reflect voice in text. Google has developed a new completely offline speech recognition system and announced that it has succeeded in minimizing the time lag that occurs in the process of speech input.
[1811.06621] Streaming End-to-end Speech Recognition For Mobile Devices
https://arxiv.org/abs/1811.06621
Google AI Blog: An All-Neural On-Device Speech Recognizer
https://ai.googleblog.com/20019/03/an-all-neural-on-device-speech.html
Google's new voice recognition system works instantly and offline (if you have a Pixel) | TechCrunch
https://techcrunch.com/2019/03/12/googles-new-voice-recognition-system-works-instantly-and-offline-if-you-have-a-pixel/
The development of speech recognition systems has made great strides in recent years, and the development of architectures such as deep learning and recurrent neural networks has improved the accuracy and speed of speech recognition systems. However, it is said that there is still a problem of time lag in which a device such as a smartphone recognizes speech and causes it to be pronounced after the user speaks a word in his own mouth.
The delay that occurs during voice input is caused by the task of sending the input voice from the smartphone to the server of voice recognition service, analyzing the voice on the server, converting it into characters and sending it back to the smartphone. Even with a delay of a second or so, the smooth input is alienated and stressful for the user, but sometimes even longer delays may occur.
Many people wonder why they don't do speech recognition on their devices, but they need a lot of computing power to convert speech to text in just a few milliseconds. In addition to simply converting speech to text, you also need to select the words that the user intended, depending on the context.

by Adrianna Calvo
Therefore, Google has developed a speech recognition system that is so compact that it can be installed on smartphones, using Recurrent Neural Network (RNN) transducers with algorithms that have achieved high results in the field of natural language processing. Because the speech recognition system does not require communication with the server, the delay is less compared to conventional speech recognition systems, and it works offline.
The RNN transducer does not have to process the entire input speech in order to output characters, but is characterized by processing the input samples continuously. Although this model had difficulty in reducing the word error rate and was able to train it to a level acceptable for practical use, the new (PDF file) training model was developed to train the model more efficiently than before. It is possible to
However, since the completed speech recognition system is as large as 450 MB, Google compresses the data to a minimum using a technique that quantizes the parameters of the neural network. As a result, we finally succeeded in compressing the voice recognition system to only 80 MB, and we were able to bring it to a level that can be installed on smartphones.
If you click the image below, you can play a GIF movie representing the difference in input speed between a conventional speech recognition system (left) that requires interaction with the server (left) and a smartphone-based speech recognition system (right) newly developed by Google . You can see that there is a significant difference in input speed between the two.
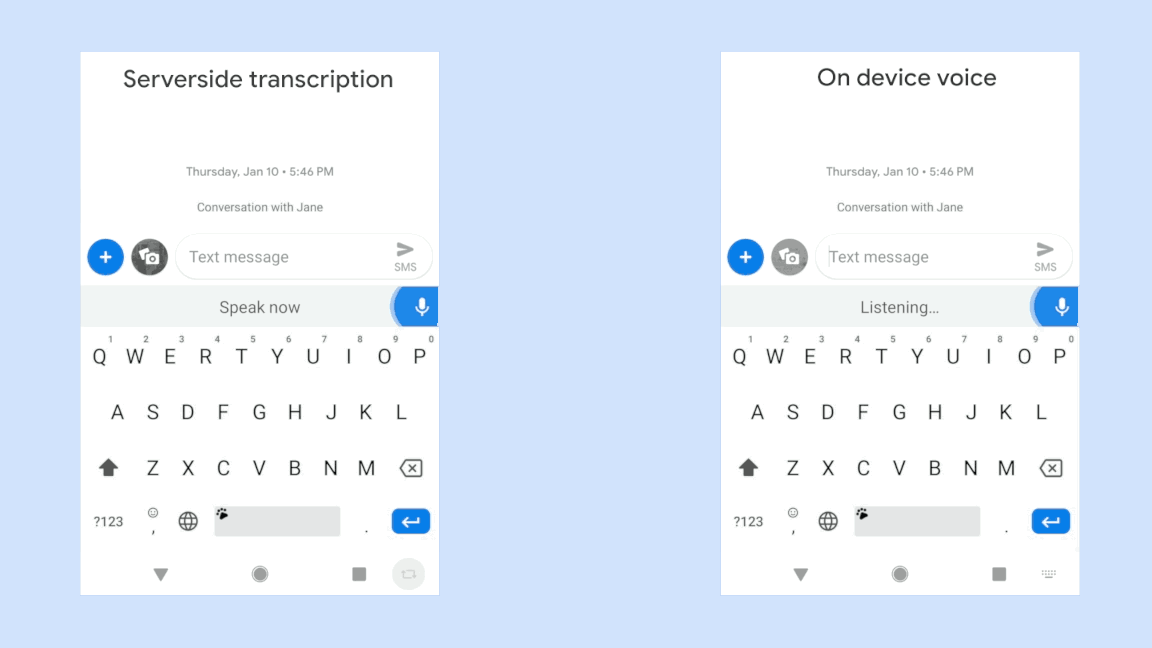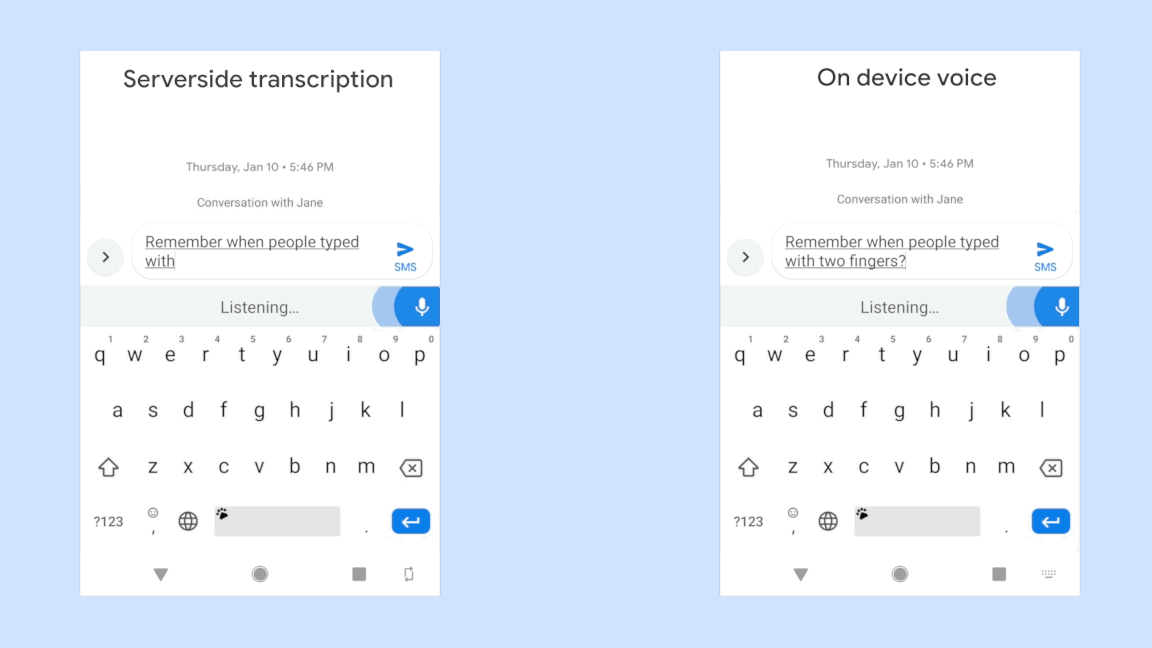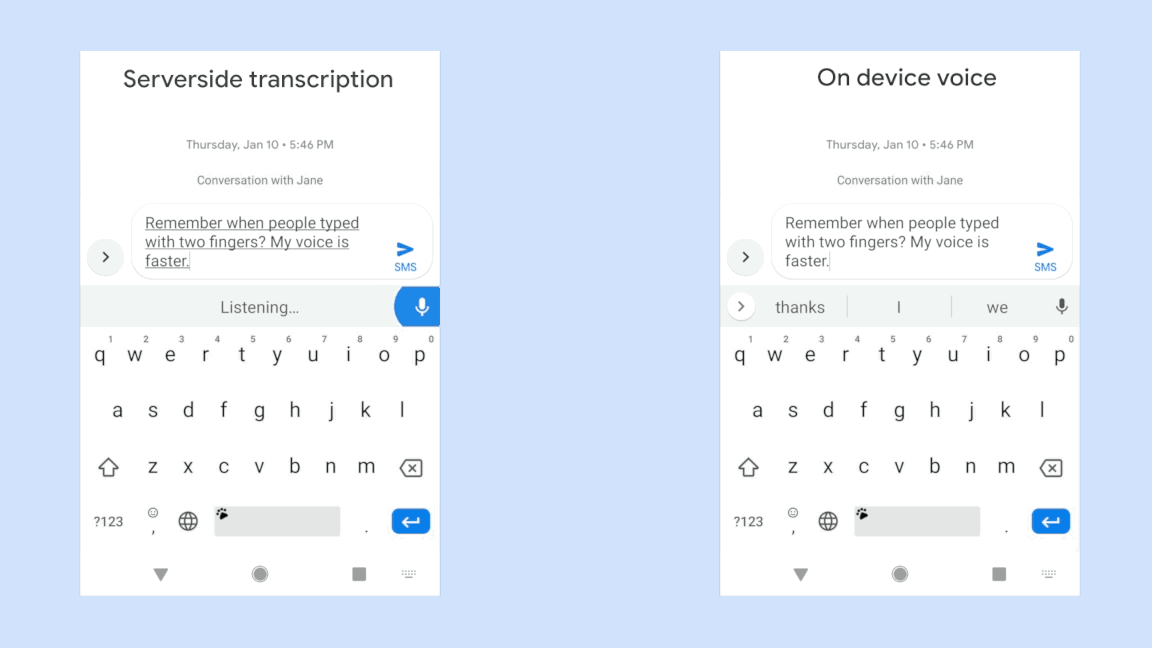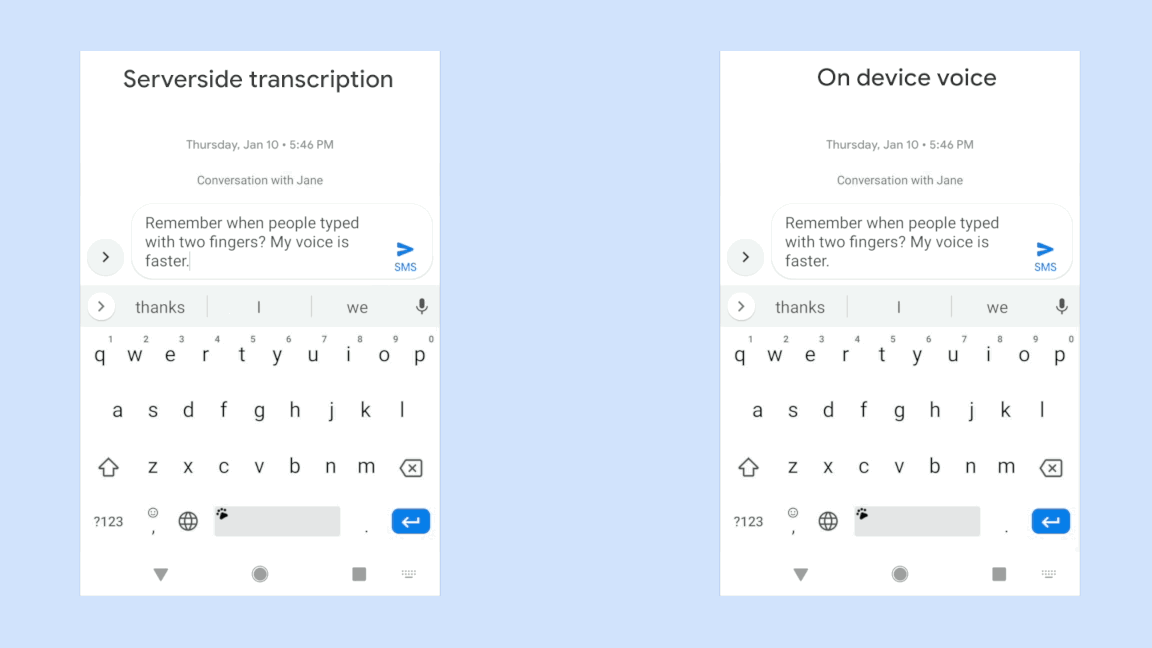
So far, the smartphone-based speech recognition system developed by Google is capable of voice input only in US English, and can only be operated with Gboard , a keyboard application made by Google, and the terminal is also compatible with Google's Pixel series only. . However, Google's development team says that in the future we expect further improvements in devices and algorithms, and expect new speech recognition systems to support a wide range of applications.

by nastya_gepp
Related Posts:








in Software, Smartphone, Posted by log1h_ik