Google has released Gemini 3.1 Flash TTS, a Japanese-language voice synthesis AI, so I tried it out. It's possible to control emotions with voice tags.
Google released its synthesized speech AI, ' Gemini 3.1 Flash TTS, ' on April 15, 2026. Gemini 3.1 Flash TTS supports Japanese and over 70 other languages, and can output high-quality speech while controlling emotions. A free demo app was also available, so I tried it out.
Gemini 3.1 Flash TTS: New text-to-speech AI model
Gemini 3.1 Flash TTS (Text-to-Speech) Preview | Gemini API | Google AI for Developers
https://ai.google.dev/gemini-api/docs/models/gemini-3.1-flash-tts-preview?hl=ja
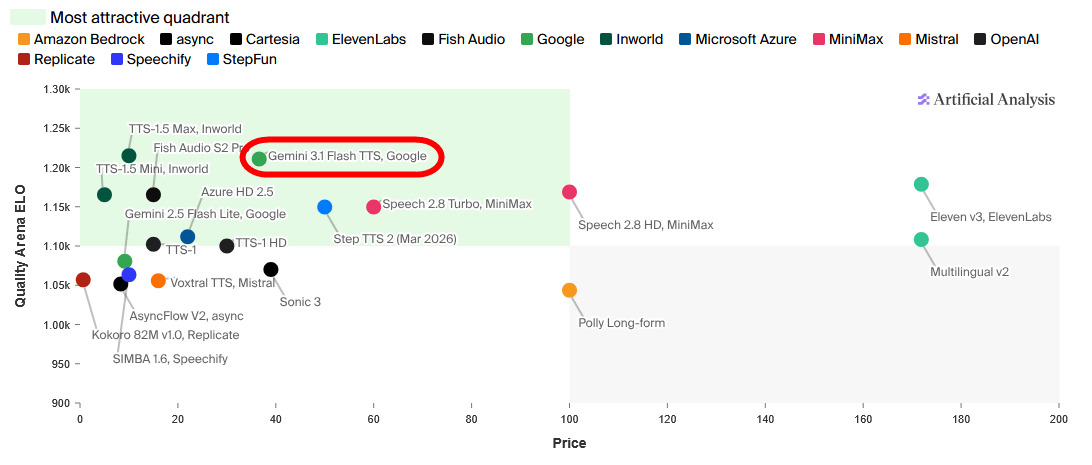
Gemini 3.1 Flash TTS is a speech synthesis AI that allows you to input text and output speech. It supports over 70 languages, including Japanese, and tests conducted by the third-party organization Artificial Analysis have confirmed that it can synthesize speech with industry-leading quality.
The following diagram shows the cost-effectiveness of various speech synthesis AIs verified by Artificial Analysis, with the horizontal axis representing API usage price and the vertical axis representing quality score. It clearly shows that Gemini 3.1 Flash TTS is an inexpensive yet high-performance model.
A free demo of Gemini 3.1 Flash TTS has been released, so let's try synthesizing some speech. First, click the link below to access the demo site.
generate-speech | Google AI Studio
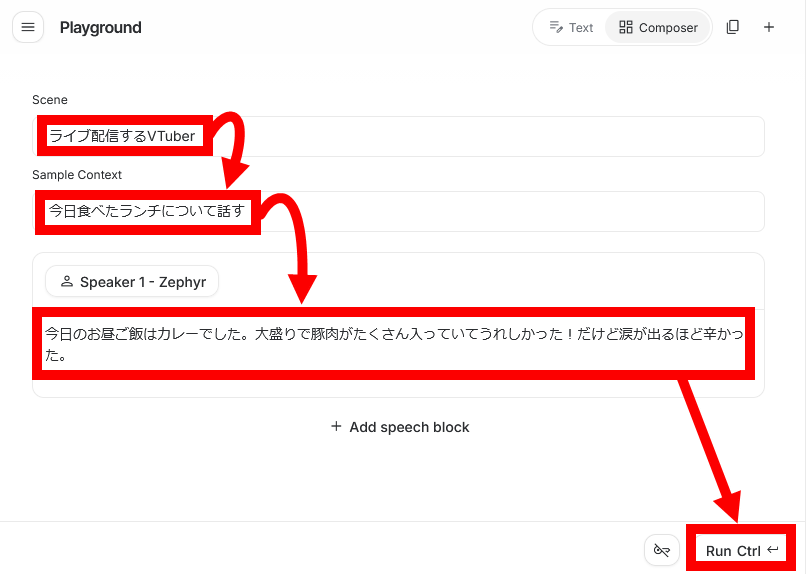
Click on the section enclosed in the red box that says 'Turn text into natural-sounding speech'.
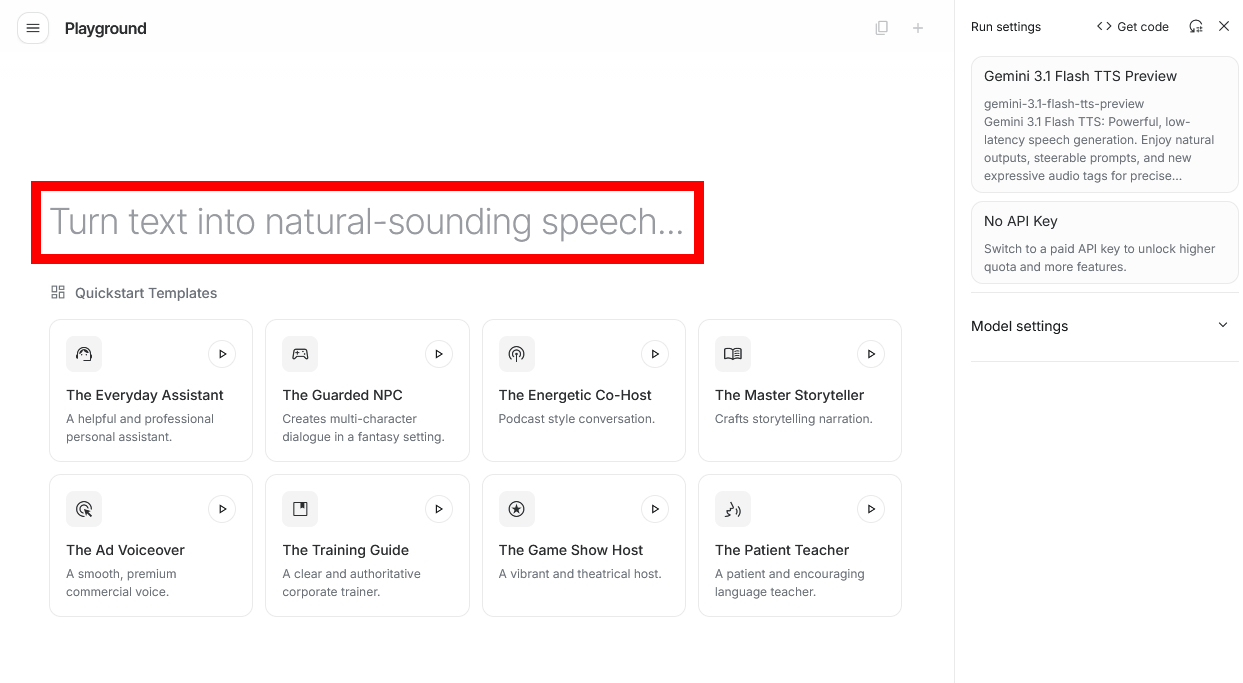
Once the prompt input screen appears, enter the 'scene,' 'context,' and 'what to say' from top to bottom, and then click the execute button in the lower right corner.
The audio was synthesized in a few seconds, and a play button and seek bar appeared at the bottom of the screen.
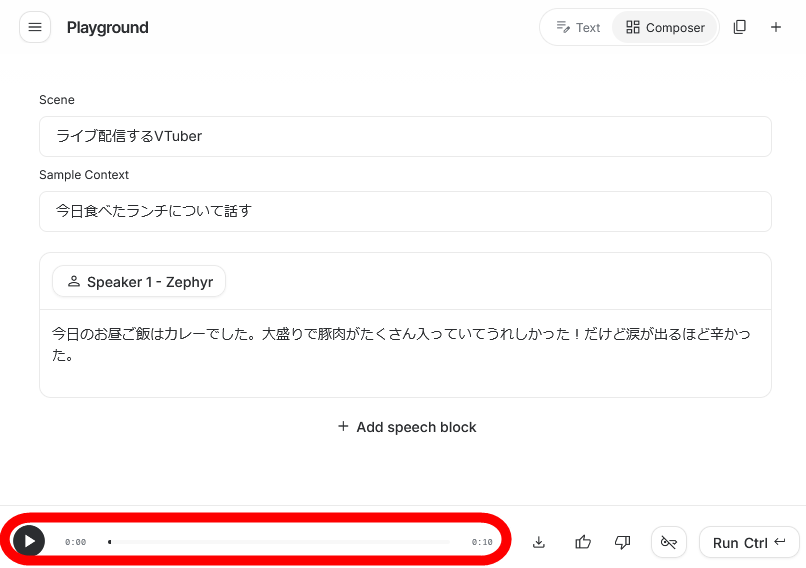
You can hear the outputted audio by playing the video below. High-quality audio that accurately reproduces emotions and intonation was synthesized without any specific settings.
Gemini 3.1 Flash TTS allows you to specify emotions using ' voice tags .' Voice tags can be specified in English, such as ' [amazed] ' or ' [crying] .' There are no specific tags that can be used; it seems that writing an emotion in English will generally work.
Let's actually try adding the audio tags ' [whispers]' , ' [laughs] ', and ' [shouting] ' and synthesizing the audio.
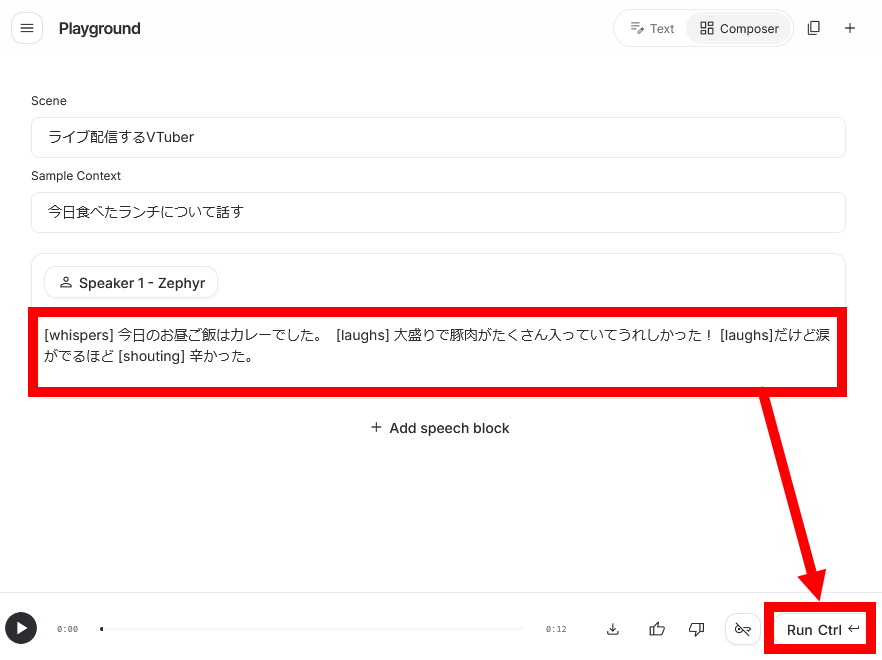
The synthesis results are as follows. The output was an audio response that faithfully followed the instructions.
I tried creating voice data that sounds like a live streamer using Google's speech synthesis AI [Emotion Controlled Version] - YouTube
Audio data generated with Gemini 3.1 Flash TTS has a SynthID embedded in it to indicate that it is AI-generated content. Additionally, a model card outlining the specifications of Gemini 3.1 Flash TTS is available at the following link.
Gemini 3.1 Flash Audio (Flash Live, TTS) - Model Card — Google DeepMind
https://deepmind.google/models/model-cards/gemini-3-1-flash-audio/
Related Posts:







