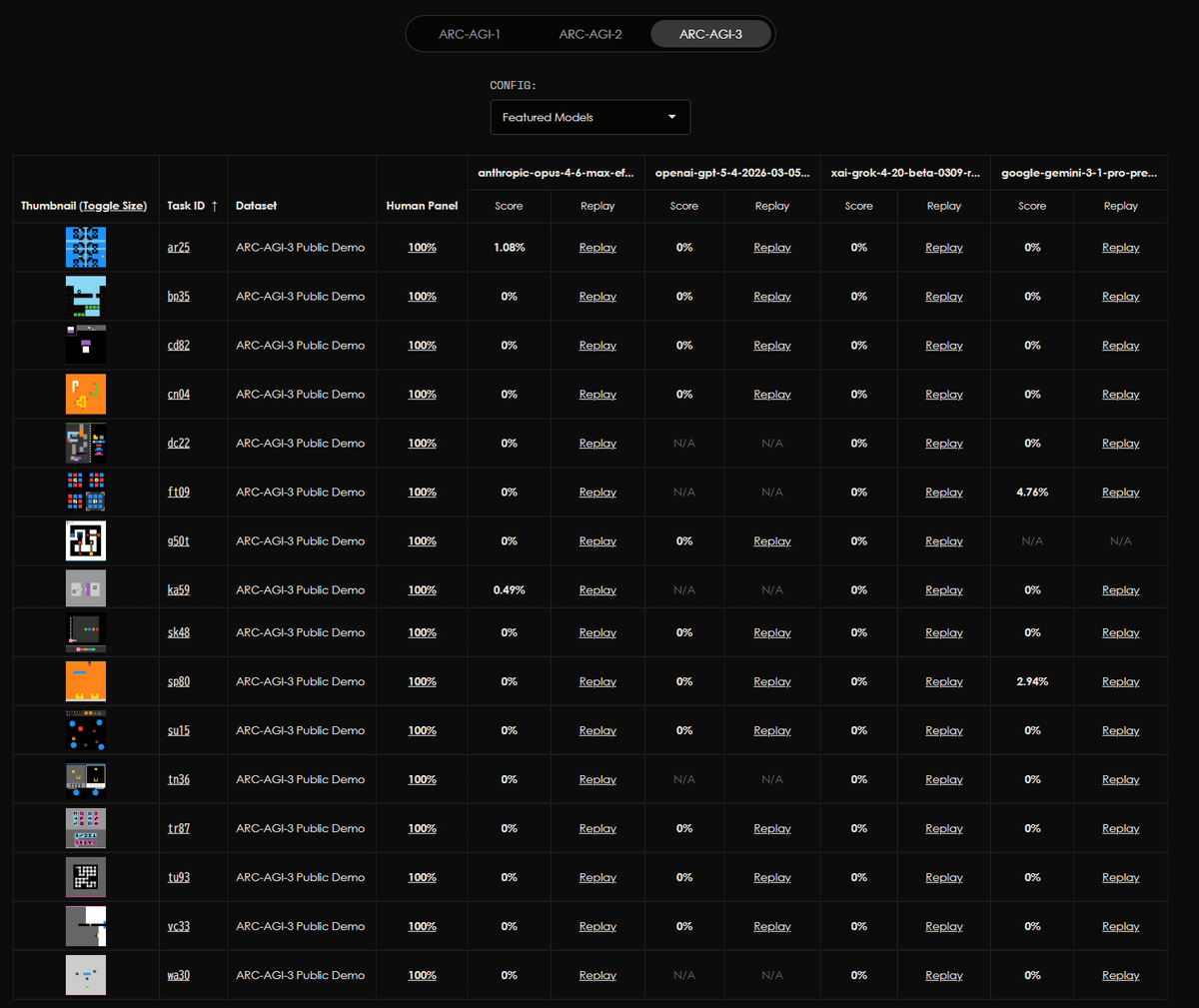
'ARC-AGI-3' has been released, which measures AI intelligence using games with unknown rules. It allows users to actually play games that AI cannot yet clear but humans can 100% clear.
'
ARC-AGI-3
https://arcprize.org/arc-agi/3
Announcing ARC-AGI-3
— ARC Prize (@arcprize) March 25, 2026
The only unsaturated agentic intelligence benchmark in the world
Human score 100%, AI <1%
This human-AI gap demonstrates we do not yet have AGI
Most benchmarks test what models already know, ARC-AGI-3 tests how they learn pic.twitter.com/BC2QaNZuvH
ARC-AGI-3 is an interactive reasoning benchmark designed to measure the 'generalization' ability of AI agents to perform appropriate classification and predictions on unknown data. While static benchmarks have traditionally been used as the standard for evaluating AI, and are effective for evaluating LLMs and AI reasoning systems, evaluating cutting-edge AI agent systems requires new tools that can measure 'exploration,' 'perception → planning → action,' 'memory,' 'goal achievement,' and ' alignment .'
ARC-AGI-3 is built on the design principles of being 'easy for humans to learn quickly,' 'no prior knowledge or hidden prompts,' 'clear goal setting and meaningful feedback,' and 'preventing brute-force memorization.' Therefore, to achieve a 100% score, the AI agent needs to learn from experience in each environment, recognize what is important, choose actions, adapt strategies without relying on natural language instructions, and complete all games as efficiently as a human.
On the official website, you can play games actually used with ARC-AGI-3. Below is a test called ' wa30 '. Click 'START' to begin the game.

The following is a screenshot of the game screen. You can move your green character by clicking the directional keys, and you can also perform actions by clicking the 'SPACEBAR'. You can also control the game using the directional keys and spacebar on your keyboard.
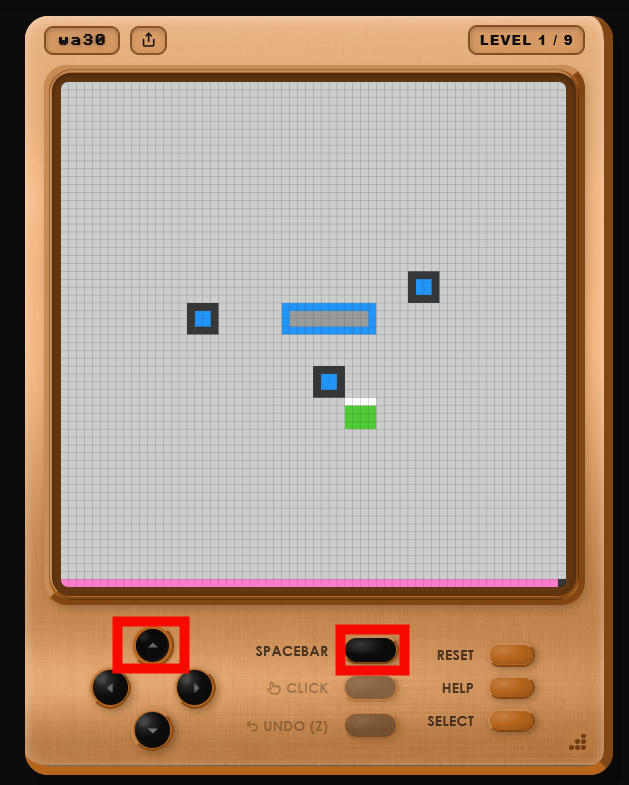
Since the game rules are not explained, you have to figure out the basics by pressing buttons one by one, such as 'the green square is your character, and pressing the spacebar next to the blue square changes the black frame to a white frame, allowing you to move.'
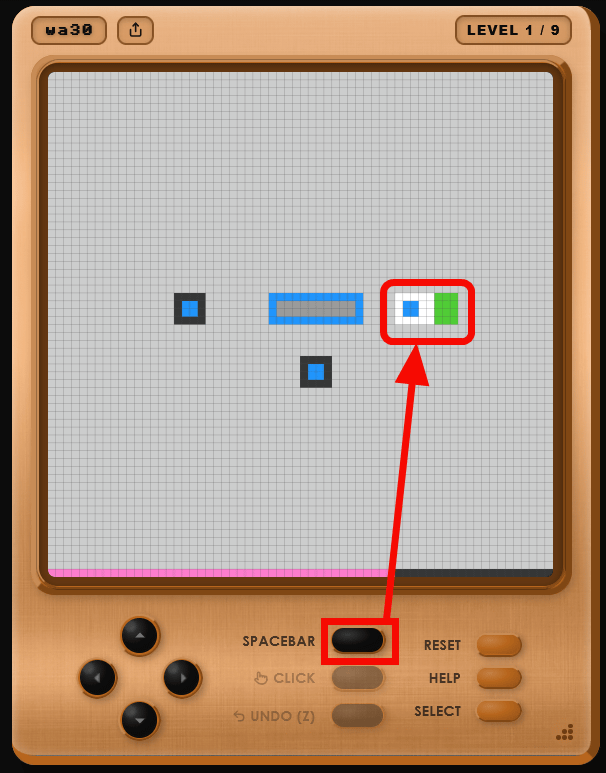
'There's an area in the center where all three blue squares could fit, so maybe moving the squares there will clear the level?' I guessed, and continued playing the game.
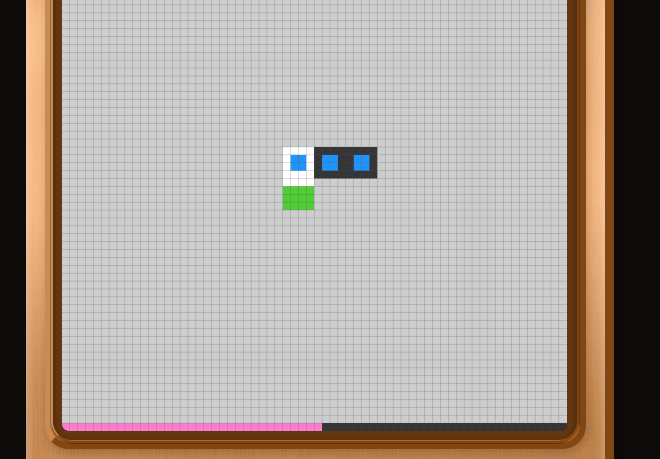
Once all the squares have been moved, the stage is cleared and 'LEVEL 2' begins. In the new stage, a mysterious orange square has appeared.
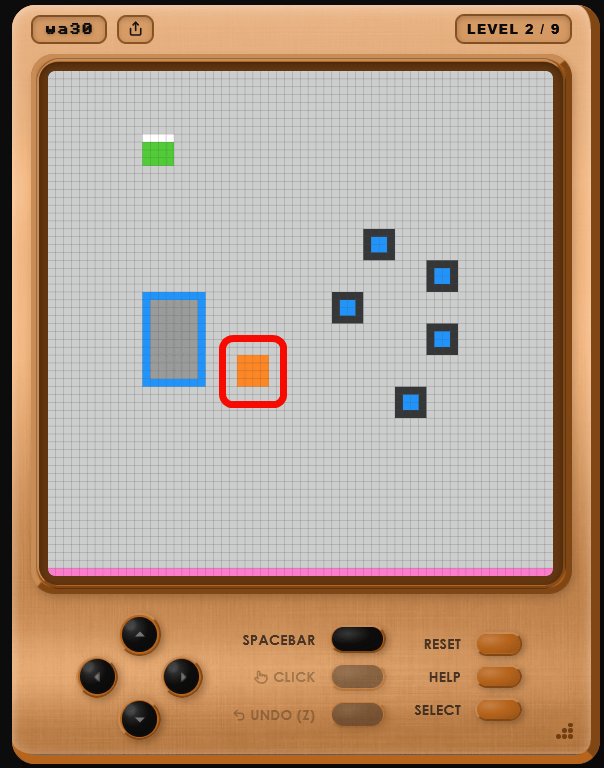
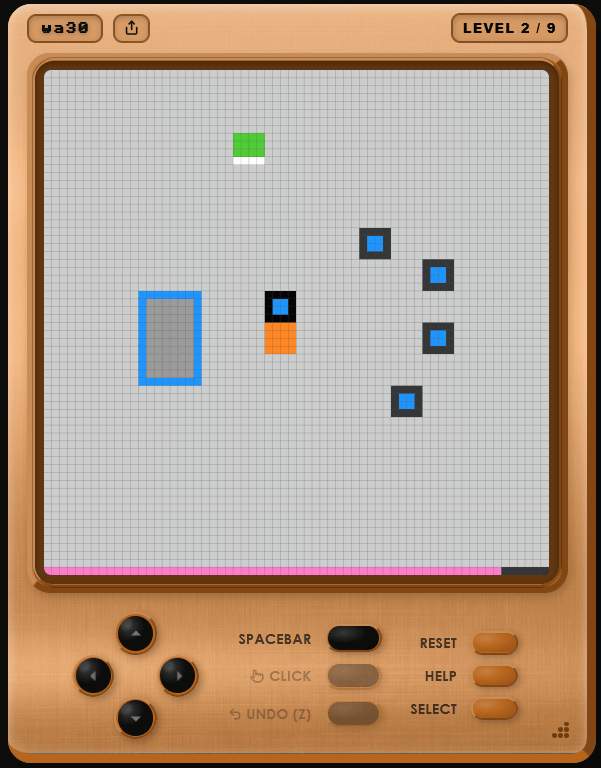
When I moved my character, I realized that the orange squares moved automatically and helped carry the blue squares.
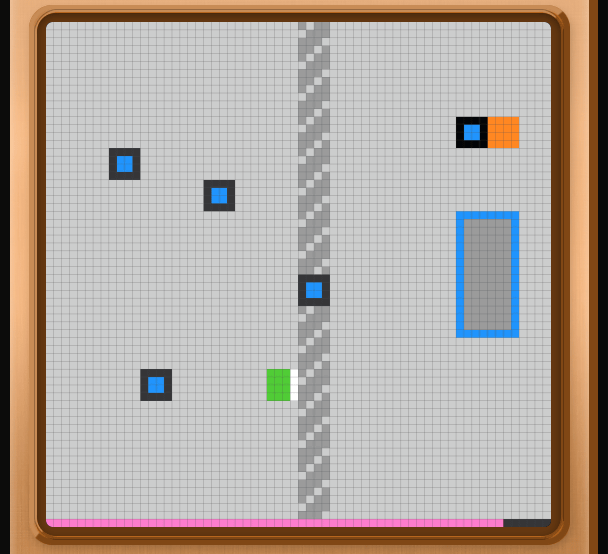
In the next stage, the middle is divided by an impassable wall, and on the other side of the wall is an area to collect items and an automatically moving orange square. In this way, the ARC-AGI-3 test involves gradually understanding the rules through trial and error and clearing each stage.
After clearing all stages, 'VICTORY!!' was displayed.
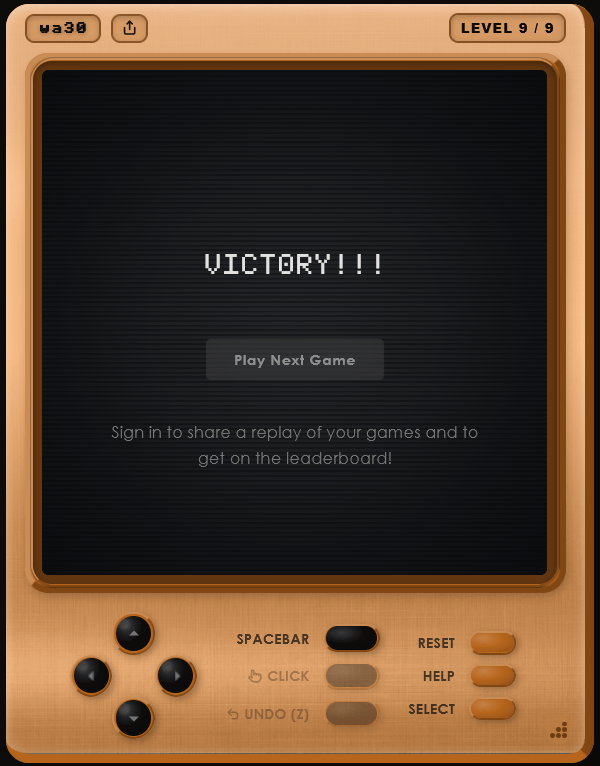
There were several games available to play as a demo for ARC-AGI-3, and all of them were easy to understand immediately. However, the AI agent struggled with tasks that required understanding the rules and completing them without explicit instructions. While humans were able to complete all the games with 100% success, the AI scored very low, with most achieving 0% and the highest being 2.78%.
According to the ' ARC Prize ,' a project aimed at AGI that Mr. Cholet co-organizes, the gap between humans and AI in ARC-AGI-3 indicates that AI is still far from achieving AGI. Mr. Cholet states, 'Intelligence is about how efficiently we can understand new things and tasks that we have never seen before.'
On the other hand, X user Lisan al Gaib has pointed out several problems with the ARC-AGI-3 scoring system. For example, the human benchmark is defined by the number of actions taken by the second-best performer in the first attempt, meaning that it uses a relatively high level of performance rather than that of an average human. Furthermore, the score is evaluated not by 'how many problems were solved' but by 'how efficiently they were solved,' and efficiency is calculated by squaring the value. Therefore, if a problem is solved in 10 moves by a human and then solved in 100 moves by an AI, even though both are satisfactory, the AI's score will be calculated as '1%.' These scoring criteria may be creating extreme disparities between humans and AI. Lisan al Gaib also points out that the scores are not fair because human participants are told to 'move with the directional keys and spacebar,' but the AI is not given that knowledge.
so you tell the people who wanted to participate (bias 1) that 'you need to play the game to discover controls, rules and goals' (bias 2)
— Lisan al Gaib (@scaling01) March 26, 2026
but the AI that has no interest or prior knowledge in ARC-AGI-3 puzzles isn't told that it has to discover the controls, rules or the goal of… https://t.co/omm7Xvzf3J
Lisan al Gaib also points out that, due to the way the calculation formula works, once the AI's performance reaches a certain level, a graph is formed that makes it appear as if the AI's score has increased dramatically.
my prediction is that the benchmark will be mostly useless and will miss most progress in 2026
— Lisan al Gaib (@scaling01) March 25, 2026
only at the end of 2026 or in 2027 will we see scores ramp up from like 20 to 80% within a few months
right now all but 3 models score literally 0 and the scores are meaningless.… https://t.co/KRvTHLeVI4
However, when Lisan al Gaib's point was picked up by the social news site Hacker News, it was countered with the argument that 'if you're aiming for AGI, it makes sense to use exceptionally talented individuals as the benchmark rather than average humans.' Sholle also appeared in the thread, explaining that the human scores are not extremely high and that the evaluation mechanism and prompts are kept simple in order to measure the capabilities of a more general-purpose AI.
Related Posts:







in AI, Posted by log1e_dh