Inception Announces Mercury 2, the World's Fastest Diffusion Model-Based Inference LLM

Introducing Mercury 2 – Inception
https://www.inceptionlabs.ai/blog/introducing-mercury-2

AI isn't a single prompt with a single answer, it's a complex loop of agents, search pipelines, and extraction jobs running in the background, where latency isn't a one-off, but cumulative across every step, every user, and every retry.
However, existing LLMs still suffer from the bottleneck of 'autoregressive sequential decoding,' meaning they can only process one token at a time, Inception points out.
That's why they developed 'Mercury 2.' Mercury 2 generates responses through parallel processing, rather than sequential decoding, allowing multiple tokens to be generated simultaneously and converge in a small number of steps. Simply put, this allows responses to be generated much faster than traditional LLMs. Mercury 2's response generation speed is said to be more than five times faster than existing LLMs.
The outline of Mercury 2 is as follows:
Speed: 1009 tokens generated per second on NVIDIA Blackwell GPUs
Price: $0.25 (approx. 39 yen) for 1 million input tokens, $0.75 (approx. 117 yen) for 1 million output tokens
Quality: Competitive with leading speed-optimized models
Features: Tunable inference, context length 128,000 tokens, use of native tools, schema -compliant JSON output
The chart below compares the number of tokens that can be generated per second by Mercury 2, Anthropic's lightweight, cost-conscious AI, Claude Haiku 4.5 , and OpenAI's lightweight, inexpensive LLM , GPT-5 mini . Mercury 2 can generate 1,009 tokens per second, more than five times the number of tokens that Claude Haiku 4.5 and GPT-5 mini can generate.

The following graph shows the results of benchmark tests performed on multiple LLMs: Mercury 2, GPT-5 nano (minimal), Claude Haiku 4.5 (without inference),
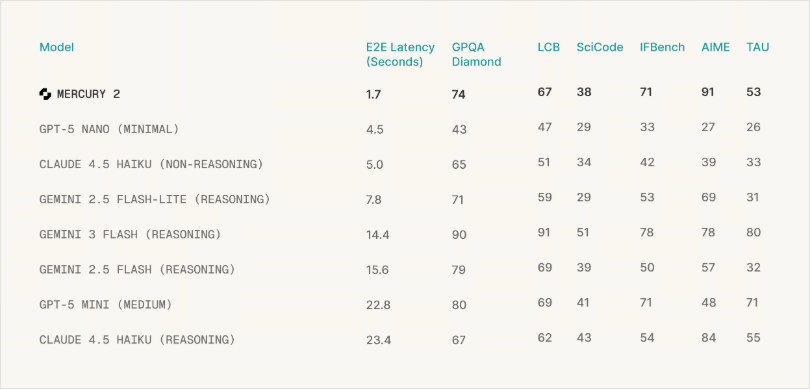
Mercury 2 has the shortest 'E2E Latency' (the delay between input and the final output). It also recorded moderate scores in the GPQA Diamond benchmark, which evaluates reasoning ability, the LCB ( LiveCodeBench ) benchmark, which measures coding ability, and the TAU benchmark, which evaluates coding ability for LLMs.
It has achieved top-class scores in SciCode , a benchmark that measures scientific computing and research-level coding ability, IFBench (Instruction Following Benchmark), a benchmark that measures the ability to follow instructions, and AIME , a benchmark that evaluates mathematical reasoning ability using past AIME questions.
Mercury 2 is available at the time of writing, and early access can be requested from the following page.
Early Access – Inception
https://www.inceptionlabs.ai/early-access
A demo version has also been released that allows you to use Mercury 2 as a chat AI.
Inception Chat
https://chat.inceptionlabs.ai/
Related Posts:







in AI, Posted by logu_ii