Chinese AI company MiniMax announces 'M2.5,' which has the same performance as GPT, Gemini, and Claude but costs less than one-tenth of the cost

MiniMax, an AI company based in Shanghai, China, has announced the MiniMax M2.5, a frontier model designed to dramatically improve real-world productivity. M2.5 uses reinforcement learning in complex real-world environments of hundreds of thousands of machines to achieve efficient inference and optimized task decomposition, achieving both extremely high processing speed and overwhelming cost efficiency.
MiniMax M2.5: More intelligent, more intelligent, more true world production power and life - MiniMax News | MiniMax
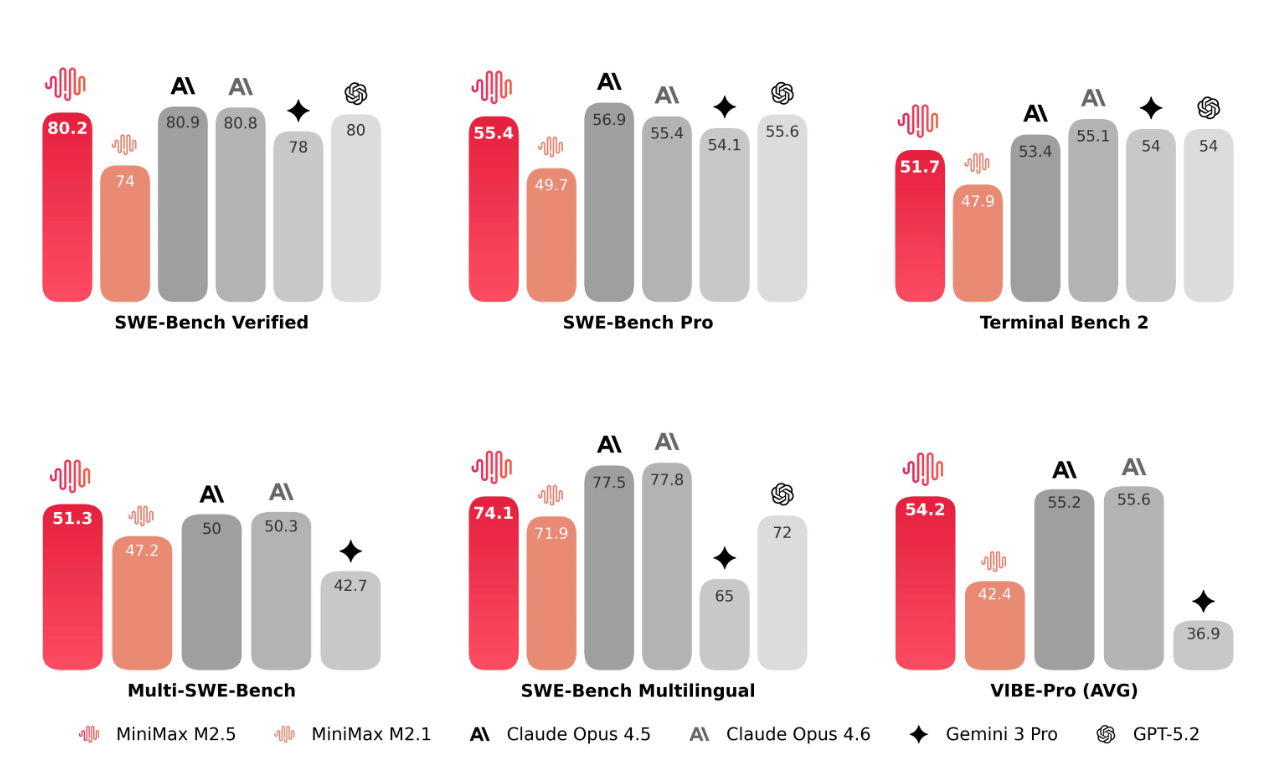
Minimax claims that the M2.5 represents a significant leap forward in programming from its predecessor, the M2.1, achieving 80.2% in the key benchmark SWE-Bench Verified , 51.3% in Multi-SWE-Bench, and 76.3% in BrowseComp when context management was enabled.
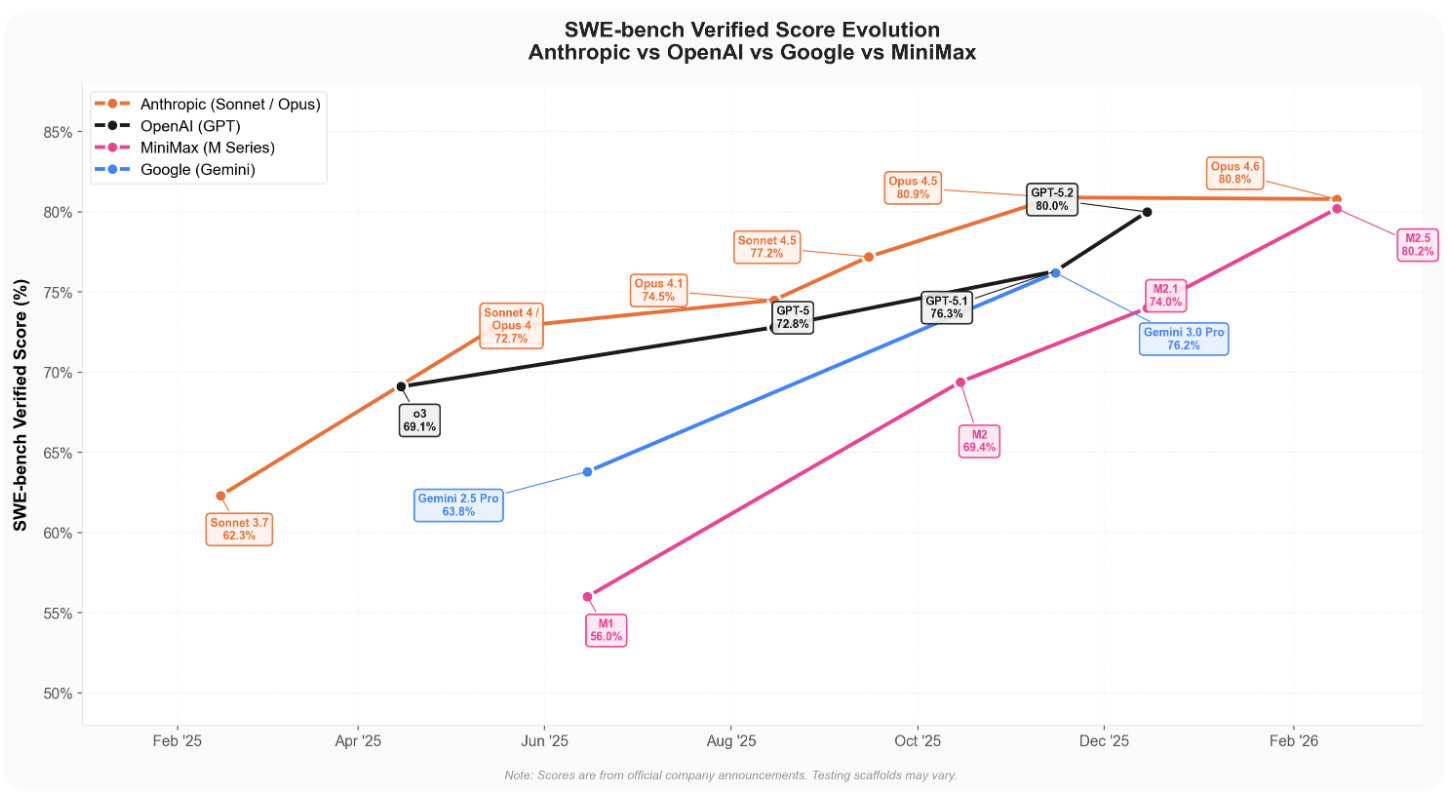
Below is a graph comparing the SWE-Bench Verified score trends of the Minimax M series (pink) with Anthropic Claude (orange), OpenAI's GPT (black), and Google's Gemini (blue).
The key point for M2.5 is the ability to think and plan like a software designer, and they have a tendency to create specifications, actively defining the project's functions, structure, and UI design before starting to write code.
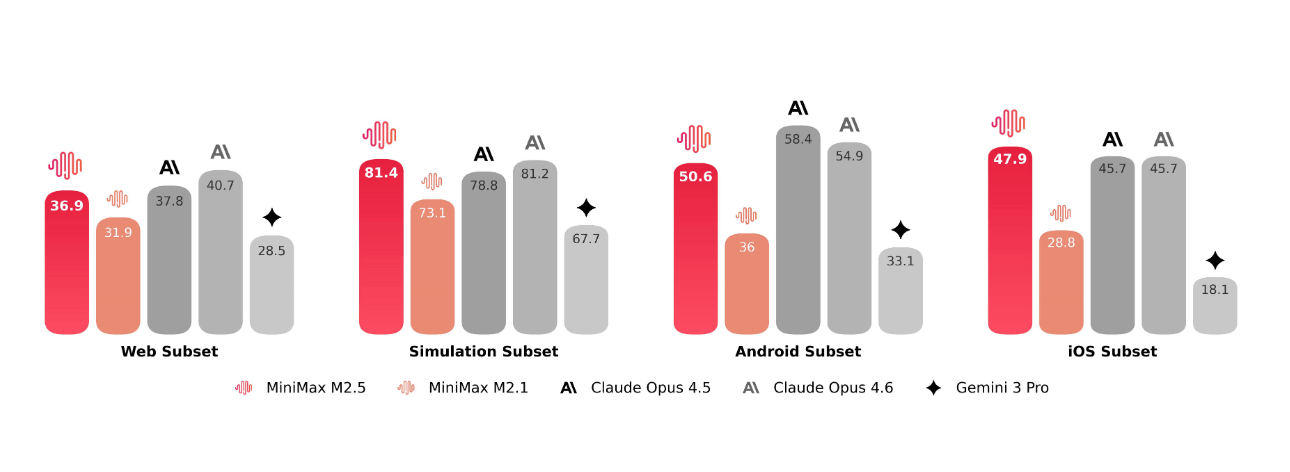
Minimax also claims to support more than 10 languages, including Python, Java, Rust, and Go, and has trained in over 200,000 real-world environments. It covers the entire development lifecycle, from setting up the development environment to system design, iterating on features, and finally code review and testing. It also enables full-stack projects across multiple platforms, including the web, Android, iOS, and Windows.
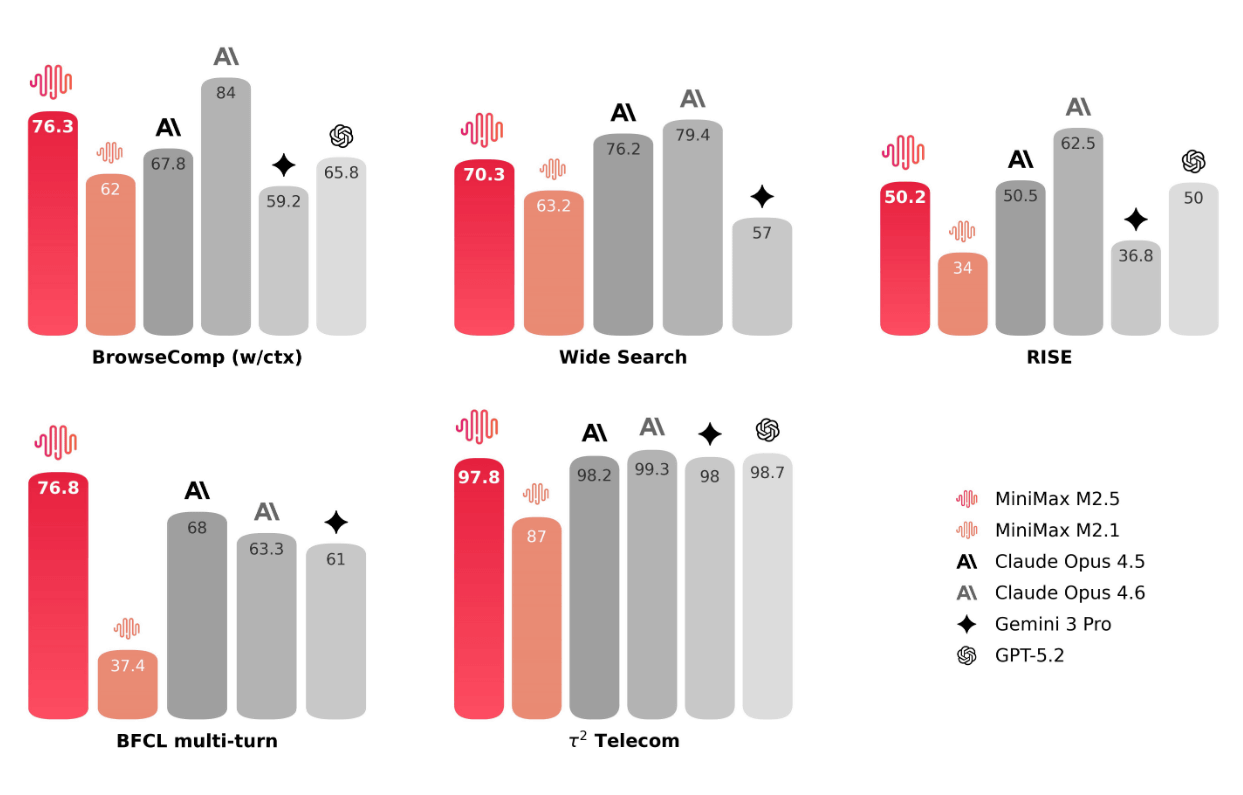
Additionally, M2.5 boasts significantly enhanced search and tool invocation capabilities, which are the foundation for agents to autonomously handle complex tasks. Compared to the previous generation, M2.1, M2.5 achieved better results in multiple agent tasks, including BrowseComp, Wide Search, and RISE, while reducing the number of search rounds by approximately 20%. This improved inference not only achieves the correct answer but also leads to a more efficient path to a conclusion. Minimax also claims to have achieved industry-leading performance in benchmarks such as
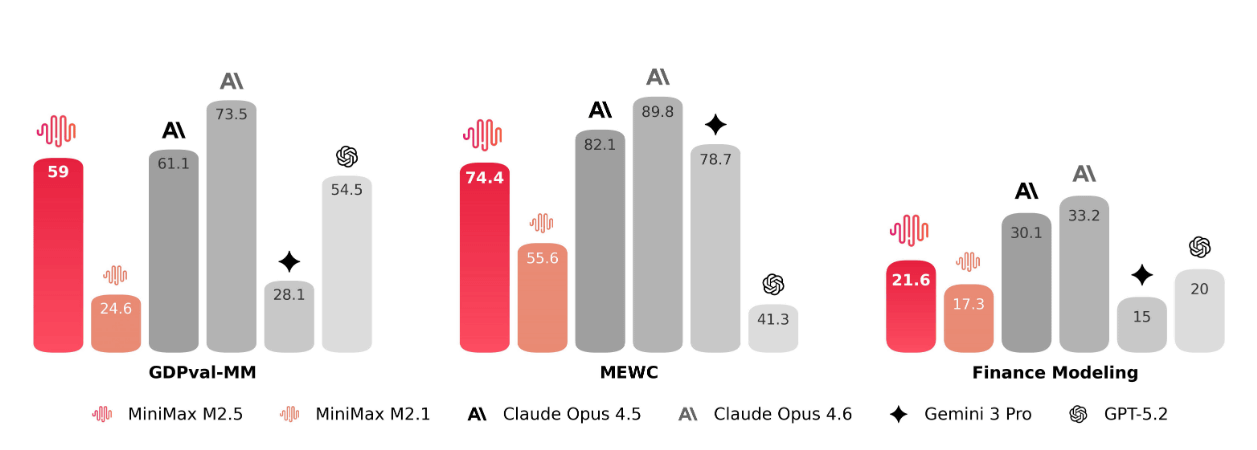
M2.5 was developed with the goal of producing deliverables that are immediately applicable in real-world workplace environments. By working closely with finance, legal, and social science experts and incorporating their industry knowledge into the learning pipeline, M2.5 has achieved significant improvements in high-value business scenarios, such as financial modeling in Word, PowerPoint, and Excel. In our internal evaluation framework, GDPval-MM , M2.5 achieved an average win rate of 59.0% against other leading models. Furthermore, evaluations using problems from MEWC , an Excel esports tournament, demonstrated M2.5's superior ability in complex spreadsheets and tool usage.
The core element supporting these technological advances is the expansion of reinforcement learning. We introduced 'Forge,' a self-developed agent-native reinforcement learning framework, and by completely separating the agent and engine, we optimized the versatility of tools and scaffolding. Asynchronous scheduling and a tree-structured sample integration strategy have increased the learning speed by approximately 40 times. On the algorithm side, we continued to use
The MiniMax M2.5 is fully integrated into the company's proprietary platform, 'MiniMax Agent,' allowing users to leverage specialized skills such as advanced coding, search, and office work through APIs. Two models are available: 'M2.5' and 'M2.5-Lightning,' which differ in processing speed and cost, allowing users to choose the model that best suits their needs.
The standard version of M2.5 can output 50 tokens per second, costing $0.150 (approximately ¥23.0) per million input tokens and $1.20 (approximately ¥184) per million output tokens. The high-speed version, M2.5-Lightning, can provide a stable output of 100 tokens per second, costing $0.300 (approximately ¥45.9) per million input tokens and $2.40 (approximately ¥367) per million output tokens.
Minimax claims that the M2.5 is 10 to 20 times cheaper than other major frontier models on an output price basis, and that the cost of running it continuously for one hour at 100 tokens per second is $1 (approximately 156 yen), and that the cost drops to $0.30 (approximately 47 yen) at 50 tokens per second. They also showed an example of how running four instances 24 hours a day, 365 days a year would still fit within a $10,000 (approximately 1.56 million yen) annual budget, emphasizing that with the M2.5, businesses can utilize advanced AI agents without worrying about costs.
Related Posts:






in AI, Posted by log1i_yk