Pointing out that what is reported as progress in AI models is 'mostly nonsense'

The development of AI technology is amazing, and new AI models are born every month, with scores such as naturalness of conversation and computational power being updated. However, Dean Valentine, an engineer who builds AI security tools, points out that 'recent advances in AI models are mostly nonsense,' and talks about the problems surrounding AI.
On Recent AI Model Progress - ZeroPath Blog
https://zeropath.com/blog/on-recent-ai-model-progress
Valentine founded the company in 2024 and began a project to use the latest AI models to create a tool that would largely replace 'pentesters,' a profession that tests to find vulnerabilities in the security field. According to Valentine, shortly after the company was founded, Anthropic released Claude 3.5 Sonnet , and the results of early internal benchmarks quickly began to saturate, and Valentine and his team's security tools not only reduced basic mistakes, but also seemed to improve the quality of vulnerability descriptions and severity estimates. He was surprised.
Claude updated the AI model to 3.6 and 3.7, and Valentine's security tools also introduced new models. However, the introduction of the new model, which was announced to have higher performance, did not make a significant difference in internal benchmarks or the ability to find new bugs compared to when the old model was introduced. Therefore, Valentine pointed out that 'in fact, Claude's AI model has not performed much better even with the new one.' On top of that, Valentine said, 'The problem is that the AI industry does not have a 'right measure'. If the industry cannot come up with a way to measure the intelligence of the model, how on earth are we going to develop a metric to evaluate the impact of AI on business operations such as business management and public policy formulation?'
According to Valentine, the benchmarks referenced when a new AI model is announced may not be of a unified standard, but rather 'benchmarks for evaluating that AI model.' Benchmarks as unified standards include OpenAI's ' PaperBench ,' which evaluates AI's ability to understand and reproduce papers, and Google's benchmark , which measures AI's cybercrime capabilities. However, Valentine pointed out that when a benchmark exists as a standard, efforts tend to be made to clear existing benchmarks rather than to improve actual convenience when developing AI. There is a theory called Goodhart's Law , proposed by a British economist, which states that 'when a measure becomes a goal, it is no longer a good measure,' and Valentine warns that the current AI industry is falling into Goodhart's Law, with the desire to evaluate AI capabilities taking precedence.
AI models are getting smarter and smarter, so testing methods can't keep up - GIGAZINE

There is also the question of whether existing benchmarks are making correct evaluations. In a paper published in March 2025 by Ivo Petrov and others from the Bulgarian Institute of Technology, they used a language model that had achieved high scores in mathematical benchmarks to tackle problems at the 2025 US Mathematical Olympiad, and reported that all of the models tested struggled significantly and recorded low scores of less than 5% on average. This is because traditional benchmarks evaluate models based only on the final numerical answer, but rigorous reasoning and proof generation are essential for real mathematical tasks, and language models still lack the ability in benchmarks based on mathematical reasoning. Here, the only reason a model improves its benchmark score is that it has 'learned many answers through training,' suggesting that it may not be possible to solve unknown problems by reasoning, such as the problems in the Mathematical Olympiad that have just been asked.
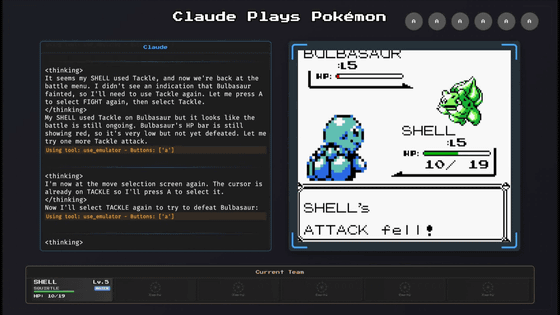
On the other hand, Valentine cited 'ClaudePlaysPokemon,' an AI model that plays the Pokemon game, as an indicator that can correctly grasp the improvement of AI capabilities. In addition to understanding basic operations, playing a game requires integrating many human-specific abilities, such as occasionally recalling what you just learned. Therefore, even advanced AI models such as Claude 3.7 Sonnet play the game quite slowly, but Valentine says that there is less noise than trusting benchmarks with unclear standards because you can see how well they are handling the tasks.
Claude 3.7 Anthropic starts streaming 'ClaudePlaysPokemon' on Twitch, letting Sonnet play Pokemon, everyone watches the super slow play while inferring - GIGAZINE
'AI will soon be at the heart of the societies we live in. The social and political structures they create as they configure and interact with each other will define everything we see around us. It's important that we make them as virtuous as possible,' Valentine said.
Related Posts: