Research to automatically convert two-dimensional pictures to three-dimensional cubes is ongoing

ByMatt Neale
How can I make AI to have the ability to "predict a solid from a two-dimensional image"? Therefore, Christian Häne, a doctoral researcher at the University of California, Berkeley, conducts research using its own method.
High Quality 3D Object Reconstruction from a Single Color Image - The Berkeley Artificial Intelligence Research Blog
http://bair.berkeley.edu/blog/2017/08/23/high-quality-3d-obj-reconstruction/
[1704.00710] Hierarchical Surface Prediction for 3D Object Reconstruction
https://arxiv.org/abs/1704.00710
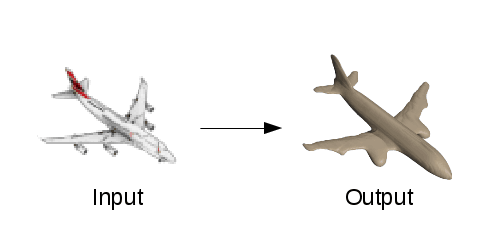
It is because humans can infer the shape of objects as cubes from a single picture or photograph because they can perceive "depth" using two eyes. Also, when you see an object on the picture, you can also deduce the part that is not actually reflected in the picture. While the above capabilities are very important for understanding the shape of an object, it is not easy to let AI do the same thing.
The basic principle used to reconstruct a solid from limited information inputs such as images and photographs is that "the shape of the object is not arbitrary". There is a fuselage if it is an airplane, there are two feathers on the side of the fuselage, and a stabilizer is always attached to the back. Human beings can see this fact in an interactive way, such as observing things overflowing the world with two eyes and touching them with their own hands. On the other hand, computers require a large amount of data to learn such principles.
Therefore, in recent research on 3D reconstruction research is "Convolution neural network(CNN) "to one kind of neural network,VoxelA method of predicting the shape of the object from the occupation amount in the object. In this method, a 3D object is subdivided, and it is judged where in the cube called a voxel, it is blank and where it is occupied by solid, where inside and outside of the object are respectively located.
To input data, color images of objects were used, CNN was able to predict the occupancy of voxels, and the network was managed and trained using the data set of CAD model. As a result, CNN learned models of various object classes.
However, with this method, there was a problem that the surface portion which should be smooth and dual side if it is originally raised in resolution, becomes decorated. Therefore, researchers took the method of hierarchically predicting whether the surface of the object has a two-dimensional nature when making a low-resolution solid at high resolution.
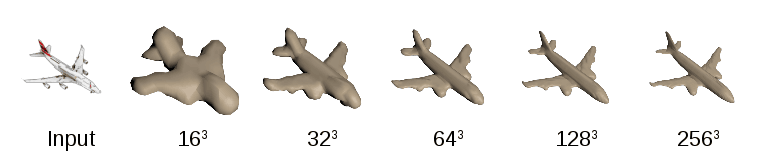
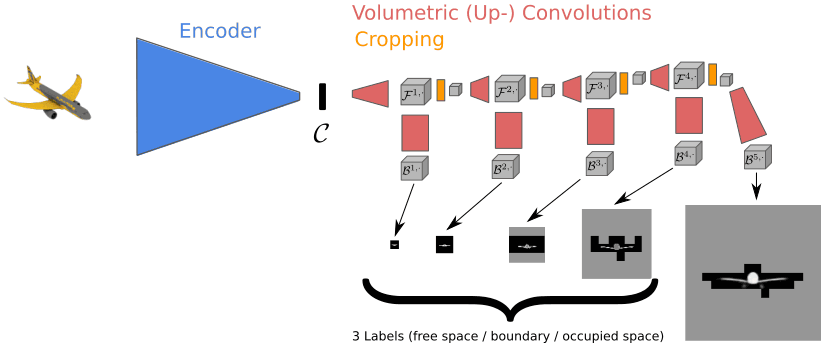
The concrete mechanism is as follows. First encode the input color image into a low volume 3D representation using a convolution encoder. And decode this as 3D occupancy. A characteristic hierarchical surface prediction (hierarchical surface prediction / HSP) in Häne et al. 'S work is also done at the time of this decoding work. In the usual case, it is predicted whether the inside of the voxel is blank or occupied, but Häne et al. Use the three classifications "borderline" in addition to "blank" and "occupied space" In order to make it possible to predict a high resolution solid with a two-dimensional surface from a low resolution solid.
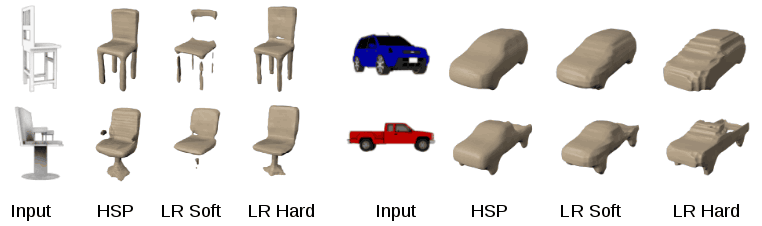
In addition, when performing three-dimensional prediction, two methods of low resolution hard (LR hard) and low resolution soft (LR soft) were taken as baselines and compared with the results of HSP, even if the same image was three-dimensionalized , It has been announced that there is considerable difference in 3D prediction. The following images are comparison diagrams, from the left input images, HSP, LR Soft, LR Hard.

Three-dimensional prediction with chairs and car images will look like this. In particular, you can see that HSP is good at expressing "smooth solid on the surface".
Related Posts:







in Software, Posted by darkhorse_log