A method 'QLoRA' that makes it possible to train a language model with a large number of parameters even if the GPU memory is small has appeared, what kind of method is it?
GPT-1 is a language model with 117 million parameters, GPT-2 has 1.5 billion, GPT-3 has 175 billion, and the performance of the language model is improving as the number of parameters increases. However, as the number of parameters increases, the amount of data required for training and the amount of memory used during training also increase, resulting in a significant increase in training cost. Under such circumstances, ' QLoRA ', a method that can train with less data while drastically reducing memory consumption, has appeared.
[2305.14314] QLoRA: Efficient Finetuning of Quantized LLMs
artidoro/qlora: QLoRA: Efficient Finetuning of Quantized LLMs
https://github.com/artidoro/qlora
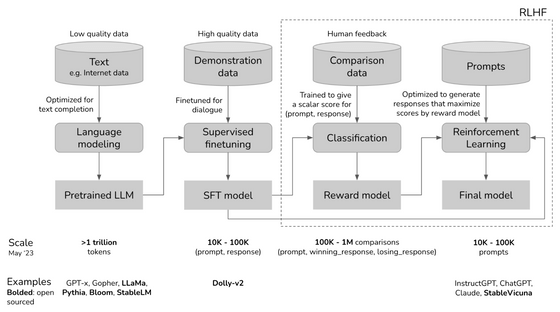
When creating a large-scale language model like ChatGPT, we first use a large amount of text data to let the model learn how to handle characters. The model created in this way is called a 'pre-trained model', and typical examples include LLaMa and RedPajama-INCITE . After that, it is common to perform additional training called fine-tuning so that the output that meets the purpose can be obtained using high-quality data such as Q&A models. Fine-tuning alone makes it possible to give fairly human-like responses, but in some cases, ``reinforcement learning by human feedback (RLHF),'' which feeds back evaluations from humans to the model, is sometimes performed to improve performance.
Since the number of model parameters is determined at the initial pre-training stage, it cannot be changed at later stages such as fine-tuning. Since general companies cannot afford the enormous computational costs required for pre-training, they will select the number of parameters from among publicly available pre-trained models. In general, the more parameters, the higher the performance, but at the same time, there was a problem that the cost of fine-tuning increased steadily.
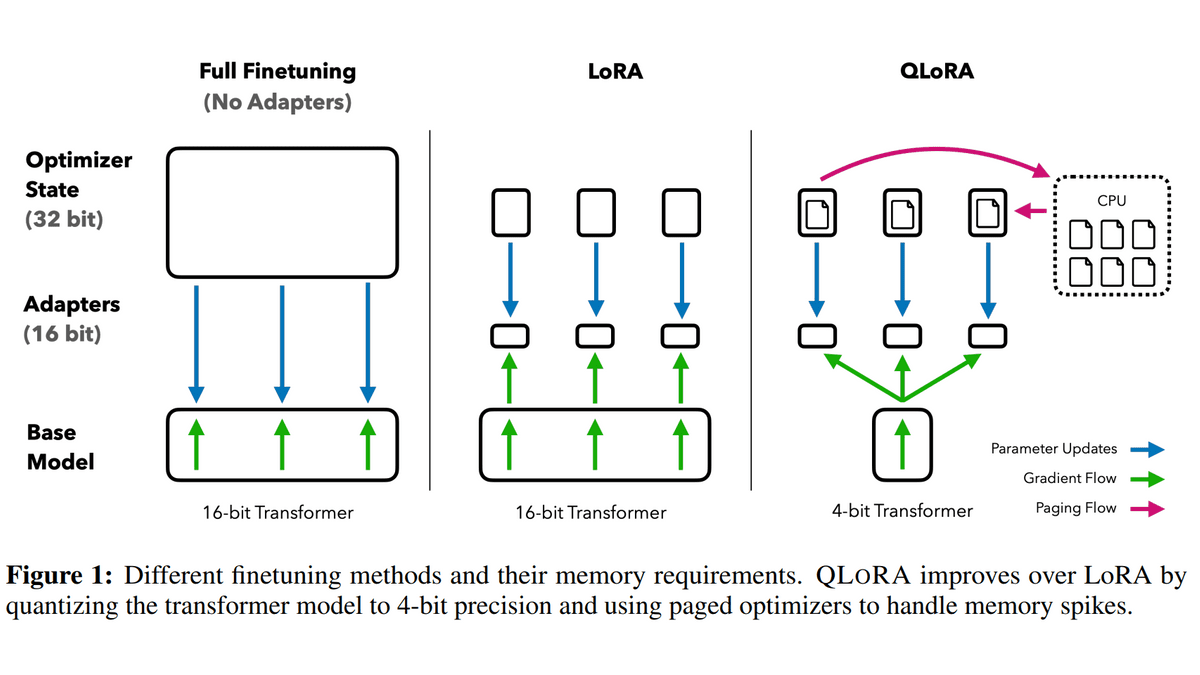
During fine-tuning, it is necessary to store the entire model in memory, and of course, it is necessary to store the calculation results for adjustment in memory for each parameter to be trained. fine-tuning requires memory many times the size of the original model. For example, if you have a model with 65 billion (65B) parameters, if you quantize each parameter with 16 bits, just loading the model into memory will consume 130 GB of memory (65 billion x 16 bits), and the training method Although it depends, it was necessary to store about 650 GB of calculation results, and a total of 780 GB of GPU memory was required for fine tuning.
A fine-tuning method called LoRA was devised to solve this memory consumption problem. LoRA reduces the memory consumption required for training by training a new matrix that is
[2106.09685] LoRA: Low-Rank Adaptation of Large Language Models
https://arxiv.org/abs/2106.09685
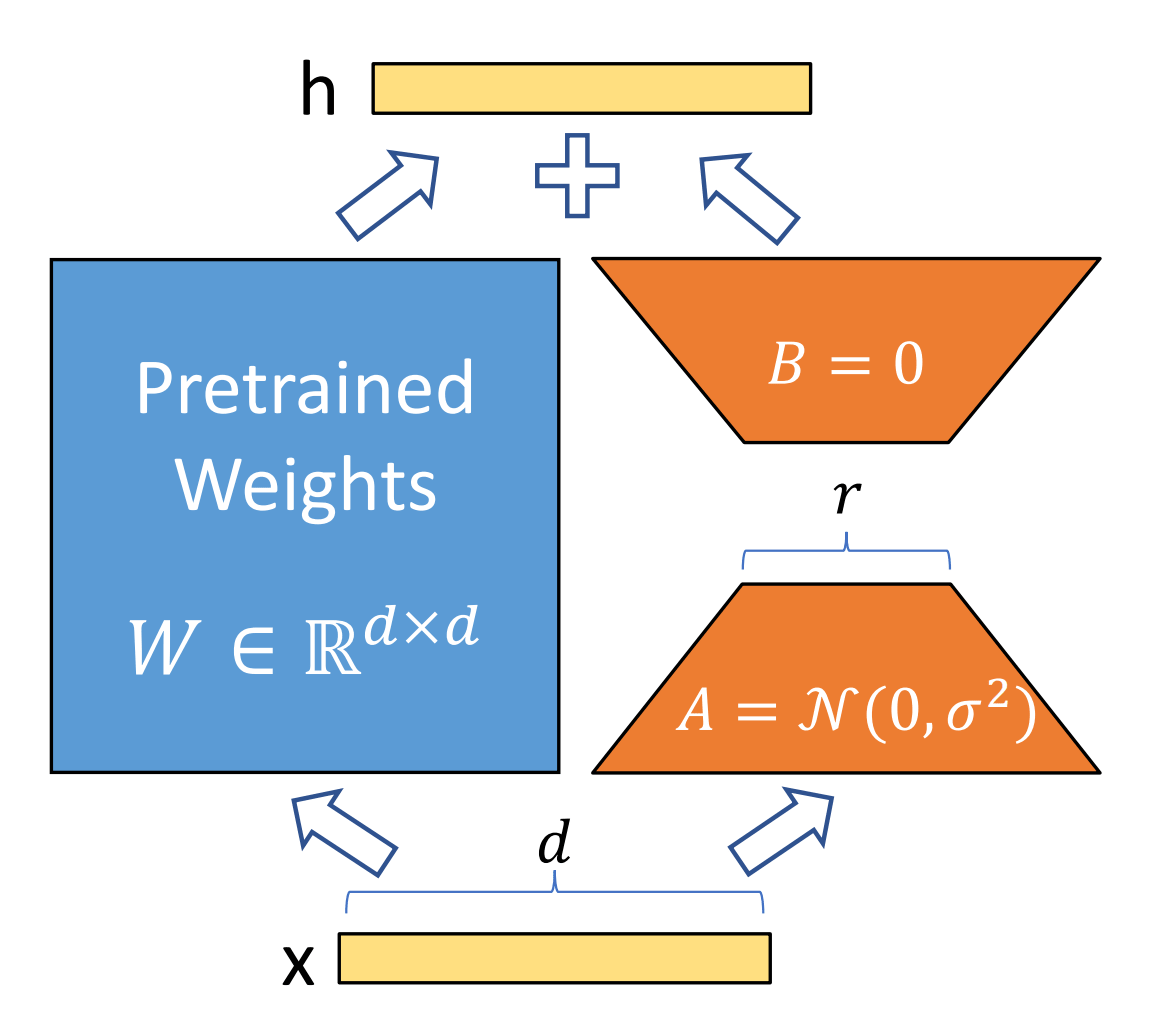
A low-rank approximation of a matrix allows us to decompose a large matrix into two smaller matrices. If the size of the original model's parameter matrix is [d]×[d], the low-rank approximation matrix is [d]×[r] and [r]×[d] where the rank number is [r]. You will end up with two matrices. By doing this, it is possible to reduce the number of parameters to be trained from d squared to 2×d×r. The LoRA paper states that GPT-3 fine-tuning reduces the number of parameters to be trained to 1/10,000 and reduces memory consumption to 1/3.
Since LoRA can be efficiently trained with few computational resources, it has been used in the field of image generation, where individual users are highly motivated to develop. For example, in Stable Diffusion, it is possible to generate images according to the learning content by having LoRA learn specific patterns, characters, backgrounds, etc.
Also, in the development of the language model, it is clear from the leaked text that there were voices wary of LoRA inside Google, which has an advantage in computational resources.
Google's AI-related internal documents stating that 'open source is a threat', 'winner is Meta', and 'OpenAI is not important' leaked-GIGAZINE

In this paper, based on this LoRA, by using three additional techniques, a model with 65 billion (65B) parameters can be trained on a GPU with only 48GB of memory, and training for 24 hours He said that he succeeded in drawing out performance comparable to 99.3% of ChatGPT.
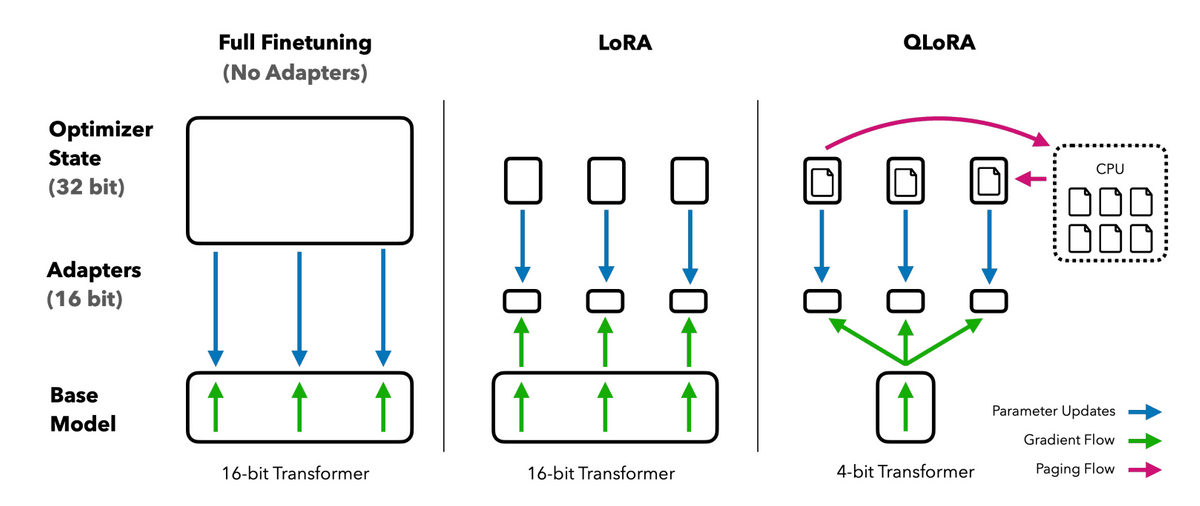
The three techniques used in the paper are:
・Quantization in NF4
In general, language models are quantized at 16 bits, and each parameter contains 16 bits of information, but QLoRA quantizes at 4 bits instead. As the amount of information decreases, so does the accuracy. Normally, the parameters of pre-trained models are normal distributions with an average of 0. Reduces accuracy loss.
・Double quantization
By quantizing the constants used during quantization, the memory consumption, which was required for 0.5 bits per parameter, was reduced to 0.127 bits.
・Page optimization
When the GPU memory reaches the upper limit, save the data to the normal memory and use a method to secure the memory necessary for calculation, thereby suppressing the GPU memory usage at peak times when updating parameters. It is said that it was done.
A model trained by Guanaco 33B with QLoRA can be

The code used in the QLoRA paper is hosted on GitHub , so feel free to check it out if you're interested.
Related Posts:






in Software, Posted by log1d_ts