対話型チャットAIのベンチマーク番付で1位はGPT-4ベースのChatGPTで2位はClaude-v1、GoogleのPaLM 2もトップ10にランクイン

カリフォルニア大学バークレー校の学生と教員がカリフォルニア大学サンディエゴ校とカーネギーメロン大学と協力して設立したオープンな研究組織「Large Model Systems Org(LMSYS Org)」が、ChatGPTやPaLM、VicunaなどのチャットAIや大規模言語モデル(LLM)のベンチマーク「Chatbot Arena」を公開しています。
Chatbot Arena Leaderboard Updates (Week 4) | LMSYS Org
https://lmsys.org/blog/2023-05-25-leaderboard/

Chatbot Arenaでは、LLMベースの対話型AIを評価するためのオープンプラットフォーム「FastChat」にユーザーが招待され、匿名モデル2種類を相手に会話を行い、どちらの方がより精度が高かったかの投票が行われます。この投票結果から、チェスなどで広く使用されているイロレーティングに基づいた勝敗とレーティングが行われ、順位表が公開されます。
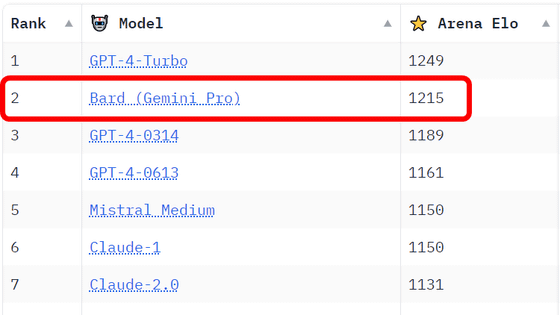
2023年4月24日から5月22日までに行われた2万7000票分の匿名投票データに基づく順位表が以下。1位はOpenAIのGPT-4をベースとするChatGPTで、2位と3位はOpenAIの競合企業であるAnthropicのClaude-v1とその軽量モデルでした。
| 順位 | モデル | イロレーティング | 解説 |
| 1 | GPT-4 | 1225 | GPT-4ベースのChatGPT |
| 2 | Claude-v1 | 1195 | AnthropicのチャットAI |
| 3 | Claude-instant-v1 | 1153 | Claudeの軽量化モデルでより高速かつ低コスト |
| 4 | GPT-3.5-turbo | 1143 | GPT-3.5ベースのChatGPT |
| 5 | Vicuna-13B | 1054 | LLaMAから微調整されたチャットAI、パラメータ数130億 |
| 6 | PaLM 2 | 1042 | GoogleのチャットAI「Bard」と同じく「PaLM 2」をベースにしたチャットAI. |
| 7 | Vicuna-7B | 1007 | LLaMAから微調整されたチャットAI、パラメータ数70億 |
| 8 | Koala-13B | 980 | GPT-3.5 TurboがベースのチャットAi |
| 9 | mpt-7B-chat | 952 | MosaicMLのオープンソースLLM「MPT-7B」ベースのチャットAI |
| 10 | FastChat-T5-3B | 941 | LMSYS orgが開発したチャットAI |
| 11 | Alpaca-13B | 937 | MetaのLLaMAをファインチューニングしたLLM「Alpaca 7B」ベースのチャットAI |
| 12 | RMKV-4-Raven-14B | 928 | Transformer採用のLLMと同等のパフォーマンスを持つRNN採用LLMベースのチャットAI |
| 13 | Oasst-Pythia-12B | 921 | LAIONによるオープンアシスタント |
| 14 | ChatGLM-6B | 921 | 清華大学によるオープンなバイリンガル対話言語モデル |
| 15 | StableLM-Tuned-Alpha-7B | 882 | Stablity AIの言語モデルベースのチャットAI |
| 16 | Dolly-V2-12B | 886 | Databricks MITによってチューニングされたオープンソースのLLMベースのチャットAI |
| 17 | LLaMA-13B | 854 | MetaのLLaMA-13BをベースにしたチャットAI |
勝率を色で示した表が以下。勝率が高いほど青く、低いほど赤く表示されています。
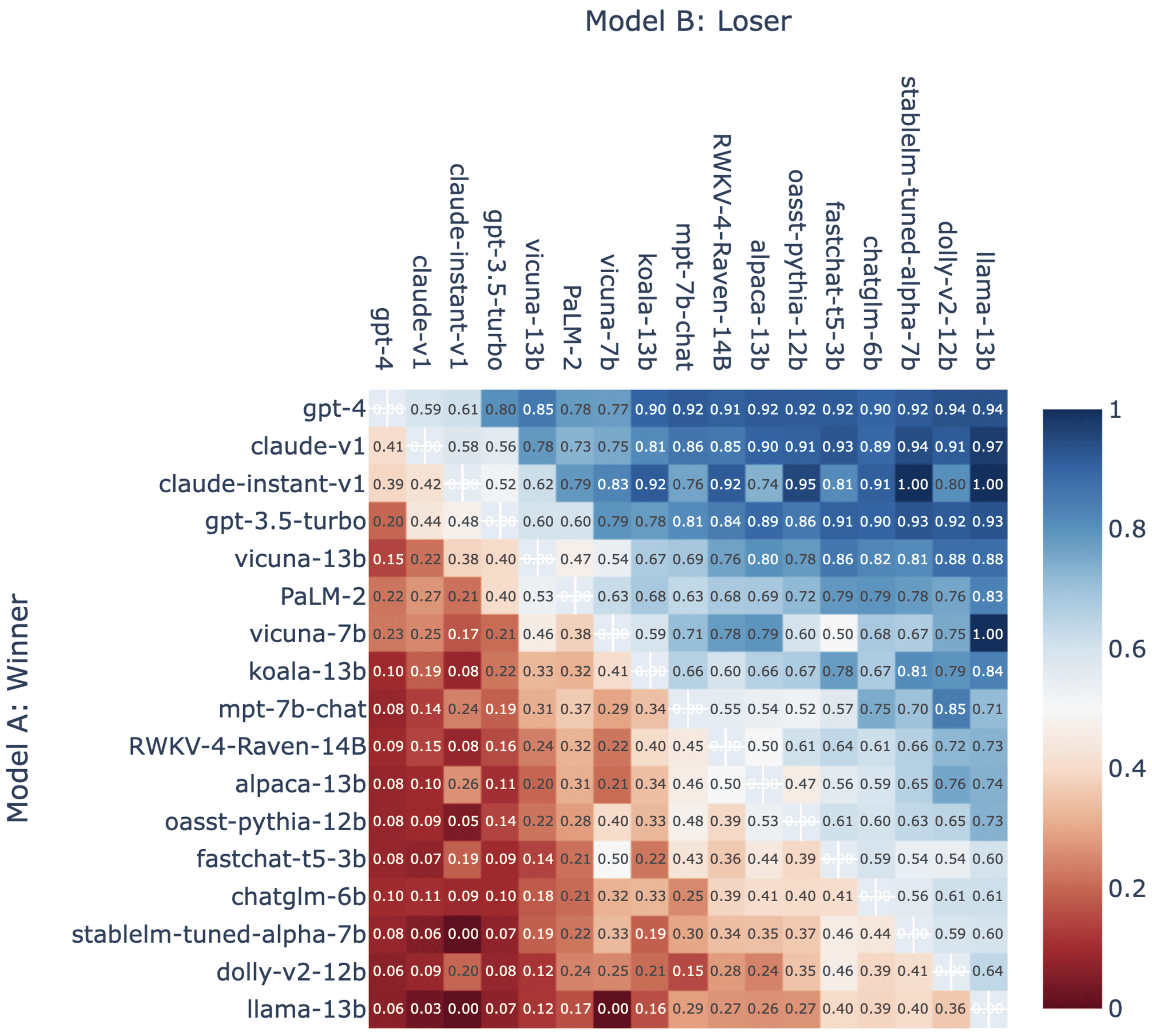
今回の結果で、LMSYS Orgは「Google PaLM 2」に注目しています。PaLM 2は順位表で見ると6位にランクインしており、勝率も決して低くありません。ただし、LMSYS Orgは「PaLM 2は他のモデルに比べて規制が厳しいようです。ユーザーが不確かな質問や答えにくい質問をした場合、PaLM 2は他のモデルと比べて回答を控える可能性が高くなります」と述べています。
例えば、Linuxターミナルやプログラミング言語のインタープリターをエミュレートするように要求すると、PaLM 2は拒否したそうです。さらに、LMSYS Orgは「PaLM 2の推論能力は十分ではない」と評価しています。
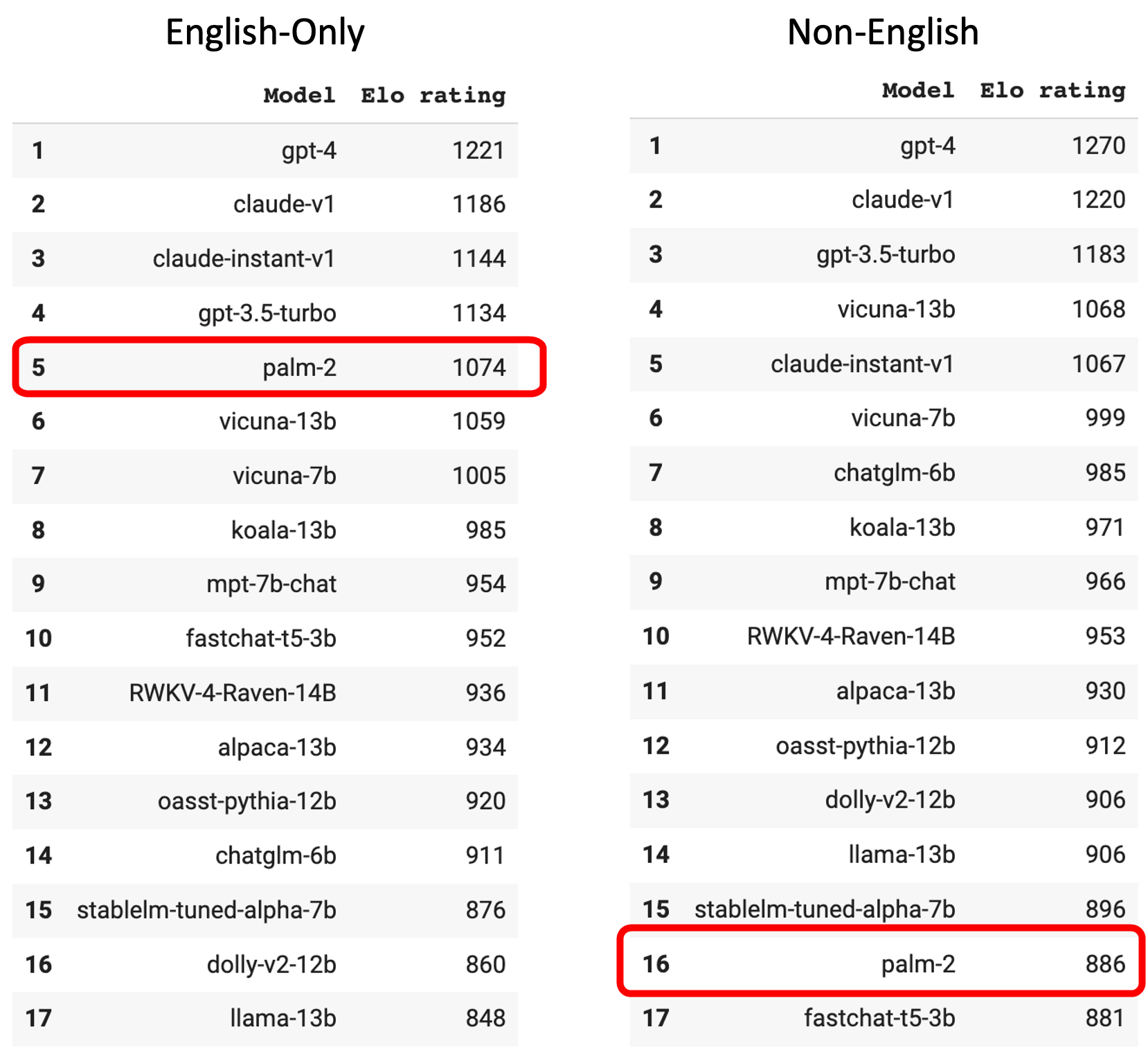
また、PaLM 2は中国語やスペイン語、ヘブライ語など英語以外の質問には回答しないという傾向も見られたそうです。英語で質問した場合のみを考慮した順位だと、PaLM 2は5位にランクインしましたが、英語以外で質問した場合の順位では16位に転落しました。
そして、LMSYS Orgは、Vicuna-7Bやmpt-7b-chatといった比較的小型のLLMをベースにしたチャットボットの順位が高いことにも注目しています。パラメーターが2倍以上ある大きなモデルと比較した時、小型のモデルの方がパフォーマンスは有利であることが示されたそうで、LMSYS Orgは「LLMのパラメーター数のサイズよりも、高品質の事前トレーニングとファインチューニングのデータセットの方が重要なケースもあるようです」と述べ、モデルのサイズを削減するには事前トレーニングとファインチューニングで高品質なデータセットを用意することが重要なアプローチだと指摘しています。
・関連記事
オープンソースの大規模言語モデル開発プロジェクト「RedPajama」が最初のモデル「RedPajama-INCITE」をリリース、無料で商用利用も可能 - GIGAZINE
Stability AIがオープンソースで商用利用も可能な大規模言語モデル「StableLM」をリリース - GIGAZINE
GoogleのAI用プロセッサ「TPU v4」はNVIDIAの「A100」より高速で効率的だとGoogleの研究者が主張 - GIGAZINE
GPT-3に匹敵するチャットAIモデル「LLaMA」をiPhoneやPixelなどのスマホで動かすことに成功 - GIGAZINE
AI戦争に勝利する方法とは? - GIGAZINE
・関連コンテンツ