独自の金融ビジネス特化型AI「BloombergGPT」をBloombergが発表、金融アナリストの業務や金融ニュースの作成を手助け可能

経済メディアのBloombergは過去10年間にわたり消費者向けのニュース分野でも成功を収めてきましたが、元々はデータ企業であり、記事作成時点でもリアルタイムで市場データなどを入手できる「Bloomberg Terminal」などの有料サービスを提供しています。そんなBloombergが、金融関連のニュースとデータを用いてトレーニングしたAIモデル「BloombergGPT」を発表しました。
[2303.17564] BloombergGPT: A Large Language Model for Finance
https://arxiv.org/abs/2303.17564

Introducing BloombergGPT, Bloomberg’s 50-billion parameter large language model, purpose-built from scratch for finance | Press | Bloomberg LP
https://www.bloomberg.com/company/press/bloomberggpt-50-billion-parameter-llm-tuned-finance/
What if ChatGPT was trained on decades of financial news and data? BloombergGPT aims to be a domain-specific AI for business news | Nieman Journalism Lab
https://www.niemanlab.org/2023/04/what-if-chatgpt-was-trained-on-decades-of-financial-news-and-data-bloomberggpt-aims-to-be-a-domain-specific-ai-for-business-news/
2023年3月30日、Bloombergが「BloombergGPT: A Large Language Model for Finance(BloombergGPT:金融特化の大規模言語モデル)」という論文を発表しました。この大規模言語モデル(LLM)は、金融業界内のさまざまな自然言語処理タスクをサポートするために、幅広い金融データを用いて特別にトレーニングされたAIモデルです。
LLMに基づくAIの進歩は多くの分野でエキサイティングな結果をもたらしていますが、金融業界の複雑さや専門用語の豊富さを考慮すると、「金融業界に特化したAIモデルが必要である」と論文では主張されています。BloombergGPTは金融業界向けにLLMベースのAIを適用するための初めのステップであり、感情分析や固有表現の認識、ニュース分類、質疑応答などBloombergが既存の金融業界で実施している自然言語処理タスクを改善することに役立つそうです。
また、BloombergGPTはBloomberg Terminalで利用可能な膨大な量のデータをマーシャリングすることで、同社の顧客により良い支援を提供する機会を開拓すると同時に、AIの可能性を金融分野にも最大限にもたらすことが可能になるとのことです。
Bloombergのエンジニア部門であるTech At Bloombergによると、BloombergGPTのパラメーター数は500億。金融関連の自然言語処理タスクをサポートするために、Bloombergのデータと公共のデータセットを独自に組み合わせてゼロから構築されたそうです。
Meet #BloombergGPT ????????
— Tech At Bloomberg (@TechAtBloomberg)
This 50-billion parameter #LargeLanguageModel was purpose-built from scratch for #finance using a unique mix of @Bloomberg's #data and public datasets to support financial #NLProc tasks.https://t.co/vehdOZtvu0#AI #ArtificialIntelligence #LLMs #ML #GPT
Bloombergによると、BloombergGPTは7000億を超えるトークンあるいは単語の断片であるコーパスでトレーニングされています。なお、2020年にリリースされたOpenAIのGPT-3は、約5000億のトークンでトレーニングされていました。このトレーニングデータのうち、3630億のトークンはBloombergがこれまで収集してきた金融データであり、「これまで構築されてきた金融業界固有のデータセットとしては最大のもの」だそうです。なお、残りの3450億のトークンは、他所から入手した「汎用データセット」です。なお、BloombergGPTのトレーニングに利用された汎用データセットには、大規模コーパスの「The Pile」が含まれます。
BloombergGPTでは汎用データセットを利用して汎用LLMを構築するのでも、金融業界固有のデータを利用して小規模なLLMを構築するわけでもなく、2つを混合するようなアプローチを採用しています。一般的なAIモデルは多くの領域をカバーすることでさまざまなタスクで高レベルのパフォーンマンスを実現します。しかし、BloombergGPTは金融業界固有のデータでもトレーニングすることで、金融関連のベンチマークでクラス最高の結果を達成しながら、汎用LLM向けのベンチマークでも競争力のあるパフォーマンスを維持することが可能になっているそうです。
以下のグラフは、BloombergGPTとその他のAIモデルで「金融固有(Finance-Specific)」タスクにおける自然言語処理ベンチマークのスコアと、「汎用(General-Purpose)」タスクにおける自然言語処理ベンチマークのスコアをまとめたもの。「Financcial Tasks(既存の金融固有タスクにおける自然言語処理ベンチマーク)」と「Bloomberg Tasks(Bloomberg内部で行う金融固有タスクにおける自然言語処理ベンチマーク)」の両方で競合AIモデルより高いスコアを出しており、汎用タスクにおけるベンチマークでも「MMLU(大規模マルチタスク言語モデルベンチマーク)」と「Reading Comprehension(読解力)」の両方で競合よりも高いスコアを記録しているのがわかります。
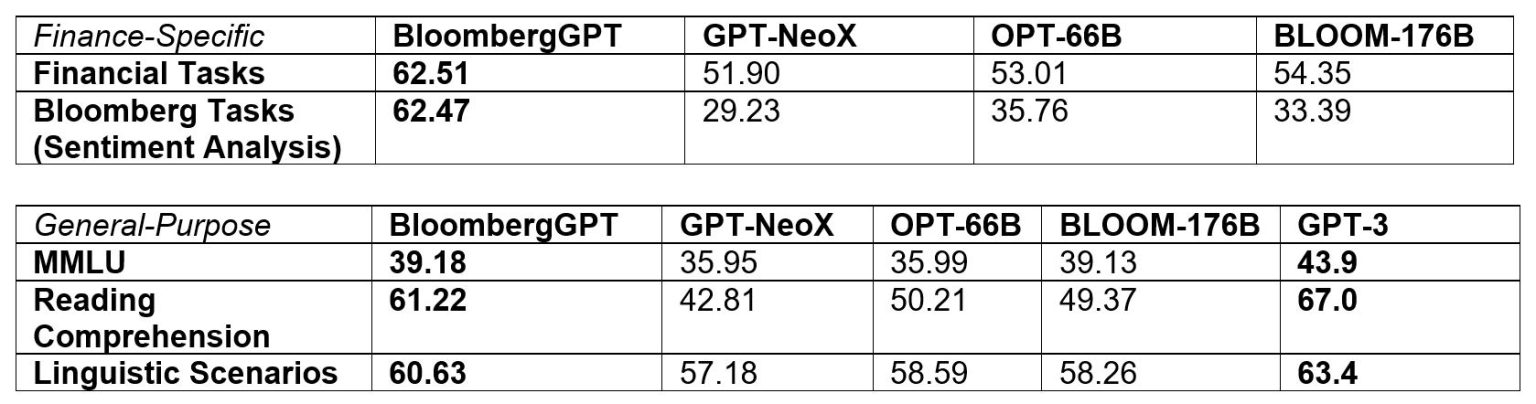
BloombergGPTは500億のパラメーターを保有していますが、同規模のパラメーターを持つAIモデルと比べると最高レベルのパフォーマンスを発揮しているとのこと。また、より多くのパラメーターを持つAIモデルと比較しても、BloombergGPTは一部のタスクでパフォーマンス面で上回るそうです。
BloombergGPTは他のLLMと同じデータセットでトレーニングされているため、ChatGPTなどで期待できるようなタスクを実行することが可能。ただし、Bloombergのニーズに密接に関わるタスクを実行することも可能で、Bloombergのニュース記事風のタイトルを作成することなどもできます。
実際にBloombergGPTを使ってBloombergのニュース記事風のタイトルを作成した事例が以下。
入力:Googleは、デジタル広告市場を独占しているとして、アメリカと8つの州からアドテク事業の分割を求めて訴えられました。この訴訟は、バイデン政権がハイテク大手に対して初めて大きな挑戦を行うものであり、1982年以来、司法省が大手企業の分割を求めるまれなケースの1つです。
出力:Googleがオンライン広告市場の独占で訴えられる
フィンテックの開発に取り組んできたというヴァン・スピーナ氏によると、BloombergGPTはアナリストに取って代わる存在になる可能性がある模様。BloombergGPTは基本的にチャットベースで動作し、財務担当者のデータ収集・整理・出力を手助けしてくれるツールとなります。基本的な財務ワークフローは反復的なものであるためチャットベースのBloombergGPTと非常に相性が良く、BloombergGPTならば休日などがないためいつでも迅速に回答を出力してくれるため、人間のアナリストと比べても利点があるというわけ。
BloombergGPT is going to replace the Analyst
— Van Spina (????,????) (@palmtreeshinobi)
Analysts are fundamentally chat-based interfaces that senior finance folks use to gather, organize, and output data
Finance workflows are already very iterative and GPT doesnt care about protected Saturdays????https://t.co/3pwdX9boHT pic.twitter.com/2ayyWIhPMd
ベンチャーキャピタルのFirstMarkで働くマット・ターク氏は、「私にとって今週最も興味深かったAI関連ニュースは、金融データでトレーニングされたBloombergの500億のパラメーターモデルです。大手テクノロジー企業やOpenAIだけでなく、多くの企業がAI分野での勝利を目指しています」とツイートしています。
The most interesting AI news of the week for me is Bloomberg’s 50B parameter model trained on financial data. Points to a polyglot future where a number of players can win in AI, as opposed to just Big Tech and OpenAI.
— Matt Turck (@mattturck)
なお、BloombergGPTの目標は、財務タスクにおいてクラス最高のAIモデルになることだそうです。
Nieman Journalism Labは「長期的にみると、小規模な出版社、特に大規模なデジタル化されたアーカイブを持つ出版社は、BloombergGPTのようなAIモデルを活用する道が開かれているように思えます」「もちろん、Bloombergの作成するものとは根本的に異なる規模であり、公開ツールよりも内部ツールとして役立つ可能性がありますが、過去1年間のAIの驚異的な進歩のペースを考えると、それはあなたが考えるよりも早く価値のあるアイデアになるかもしれません」と言及しています。
・関連記事
ニュースメディアのCNETが使っていた記事作成AIは「競合他社や系列サイトのライターの記事を盗作していた」という指摘 - GIGAZINE
CNETがAIで記事を書いていることを問題視されて記事の公開を停止へ - GIGAZINE
ニュースメディアのCNETが2022年11月から「CNET Money」という署名を付けて密かにAIで記事を作成していると報じられる - GIGAZINE
なぜ「AIによる株式投資」は普及していないのか? - GIGAZINE
「ChatGPT」などの自動生成AIは世界のGDPを7%増加させると同時に3億人の雇用に影響を与えるという調査報告、日本は世界で3番目に大きな影響を受けるとの指摘も - GIGAZINE
・関連コンテンツ