Metaが次世代のオープンLLM「Llama 3」を公開、無料で商用利用可能なモデルの中では過去最高の性能

MetaがLlamaファミリーの次世代大規模言語モデル「Llama 3」をリリースしました。研究目的のほか、月間アクティブユーザーが7億人以下の場合は無償で商用利用が可能となっています。
Meta Llama 3
https://llama.meta.com/llama3/
Introducing Meta Llama 3: The most capable openly available LLM to date
https://ai.meta.com/blog/meta-llama-3/
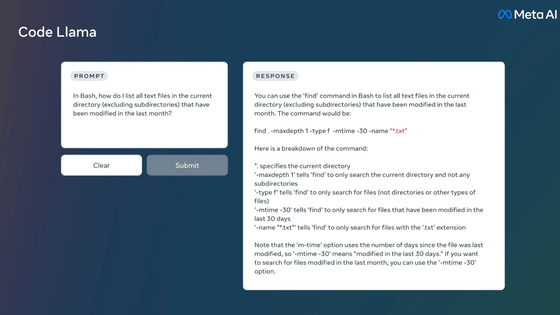
今回リリースされたのは80億(8B)パラメーターと700億(70B)パラメーターの2つのモデルです。共に事前トレーニングの後に命令追従用のためのファインチューニングが行われている「Instruct」モデルで、チャットAIとしてのタスクをこなすことができます。
同等のパラメーターを持つモデルとの比較結果は下図の通り。オープンなモデルの中ではほとんどの指標で最高のスコアを記録しています。トレーニング後の手順を改善することで誤った拒否の発生率を減らし、応答の多様性を向上させたほか、推論・コード生成・命令などの機能が大きく向上していると述べられています。
Llama 3の開発では標準ベンチマークのほか、実際の使用シナリオに沿ってパフォーマンスを最適化する試みも行われており、そのために新たな高品質の人間評価セットを導入したとのこと。この評価セットでは12個の主要なユースケースに対応する1800個のプロンプトが含まれており、それぞれのプロンプトに対する応答結果を人間が評価しました。
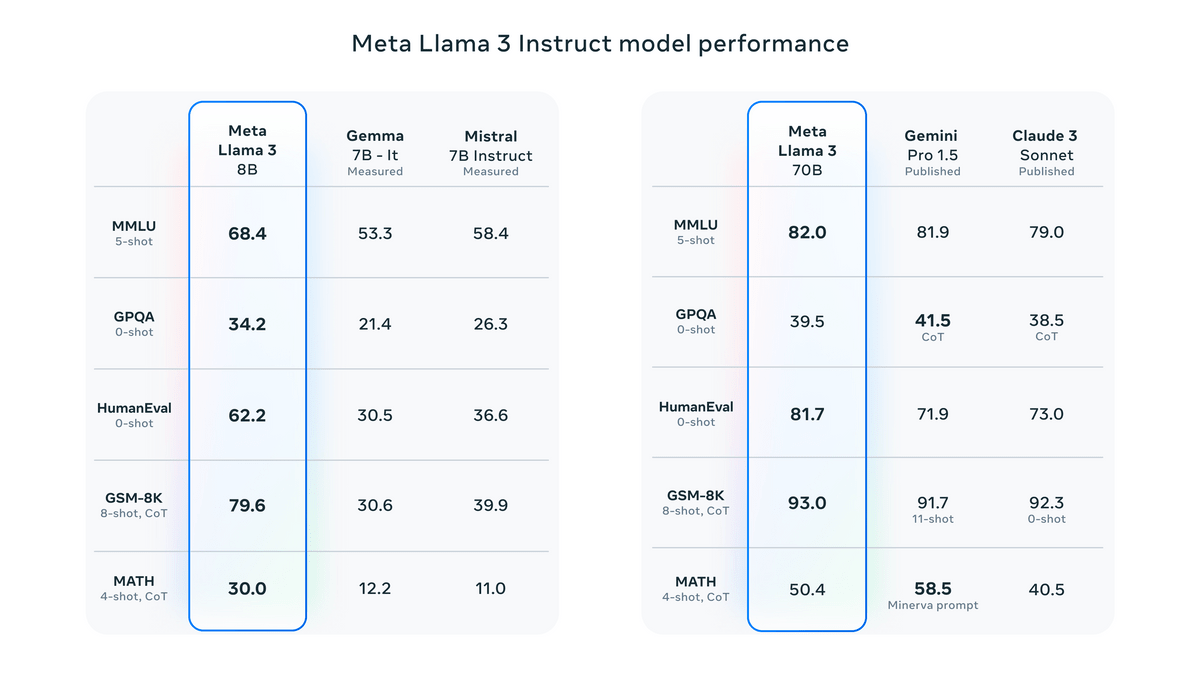
同じプロンプトに対する他のモデルの出力と「どちらの答えの方が優れていたか」を人間が評価した結果は下図の通り。Claude SonnetやMistral Medium、GPT-3.5よりも高い評価を得たほか、前のモデルであるLlama 2に比べてはるかに回答が改善されていることが分かります。
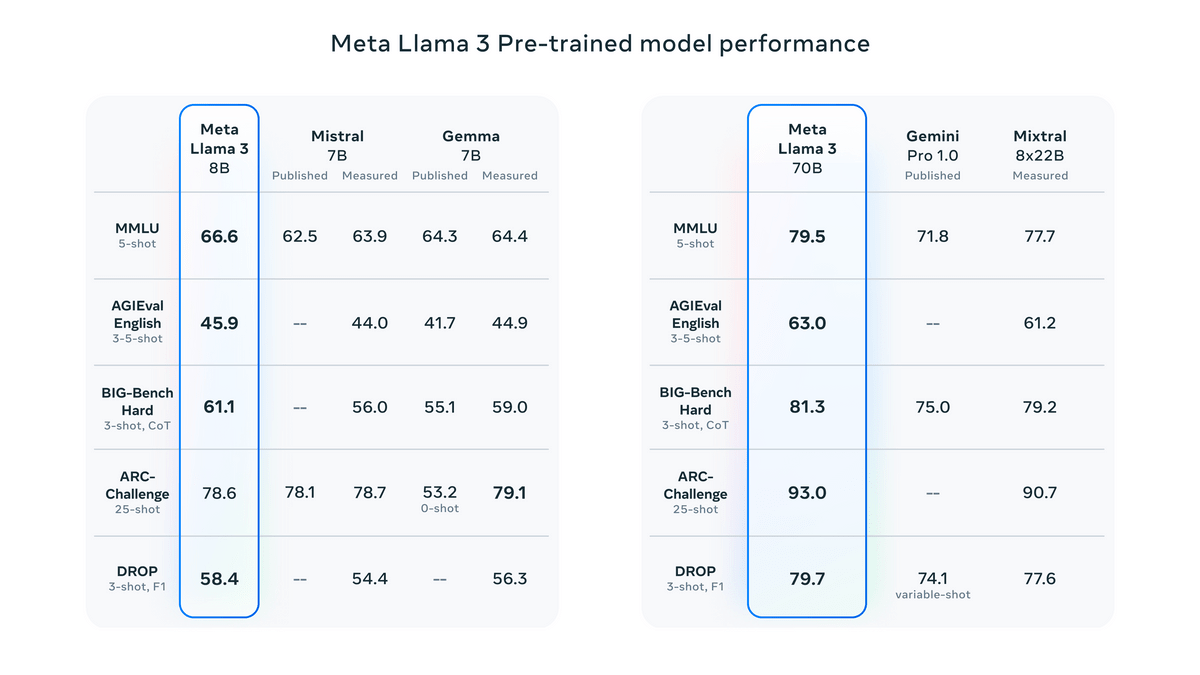
なお、ファインチューニングを行っていない事前トレーニング済みモデルの段階での性能比較は下図の通り。
Llama 3の開発にあたり、Metaは「モデルアーキテクチャ」「事前トレーニングデータ」「事前トレーニングのスケールアップ」「命令のファインチューニング」という4つの要素に重点を置いたとのこと。
Llama 3ではモデルアーキテクチャとして比較的標準的なデコーダーのみのトランスフォーマーアーキテクチャを採用しています。Llama 2と比較するとトークンの語彙(ごい)数を12万8000トークンに増加させたことで言語をより効率的にエンコードでき、パフォーマンスを大幅に向上させることができました。また、Llama 3の推論効率向上のため、グループ化クエリアテンション(GQA)を採用し、8192トークンのシーケンスでモデルをトレーニングしたと述べられています。
Llama 3のトレーニングには公開されているソースから集めた合計15兆トークン以上のデータが使用されています。このトレーニングデータセットはLlama 2で使用したものより7倍大きく、また4倍多い量のコードが含まれているとのこと。今後の多言語でのユースケースに備えるため、このデータセットの5%は30以上の言語に渡る英語以外のデータとなっているものの、英語と同じパフォーマンスは期待できません。
さらにMetaはデータフィルタリングパイプラインを開発し、ヒューリスティックフィルターやNSFWフィルター、セマンティック重複排除アプローチ、テキスト分類子などを使用してトレーニングデータの品質を高めたとのこと。広範な実験を通して多数のデータを適切に混合する方法を調査し、科学やコーディング、歴史などさまざまなユースケースでLlama 3が適切に動作することを保証するデータミックスを選択できたと述べられています。
Llama 3の開発中にMetaはトレーニングデータのスケールが品質に与える影響も調査したとのこと。8Bモデルと70Bモデルの両方において、15兆トークンでトレーニングした後でも対数線形にパフォーマンスが向上しました。こうした大量のトレーニングをこなすために、Metaはデータ・モデル・パイプラインの3つを並列化し、1万6000台のGPUで同時にトレーニングする場合でも1GPUあたり400TFLOPSのコンピューティング使用率を達成できたと述べられています。また、GPUのエラーの検出や処理、メンテナンスを自動化する新たに開発したトレーニングスタックにより有効トレーニング時間は95%を超え、全体としてLlama 3のトレーニング効率はLlama 2の時と比べて約3倍になったとのこと。
こうした事前トレーニングの後、Llama 3は「教師ありファインチューニング(SFT)」「拒否サンプリング」「近接ポリシー最適化(PPO)」「直接ポリシー最適化(DPO)」を組み合わせた命令追従用の調整を受けています。答えるのが難しい質問に出会った際に、モデルは「正しい答えを生成する方法を知っているもののその方法を選択するやり方を知らない」という状態にあったため、PPOとDPOを介した優先順位ランキングを学習することで答えを生成する方法を適切に選択できるようになり、推論とコーディングタスクのパフォーマンスが大幅に向上しています。
また、MetaはLlamaモデルを「開発者が運転席に座れる広範なシステムの一部」と想定しており、新たなシステムレベルのアプローチを採用することでモデルの安全性を向上させています。
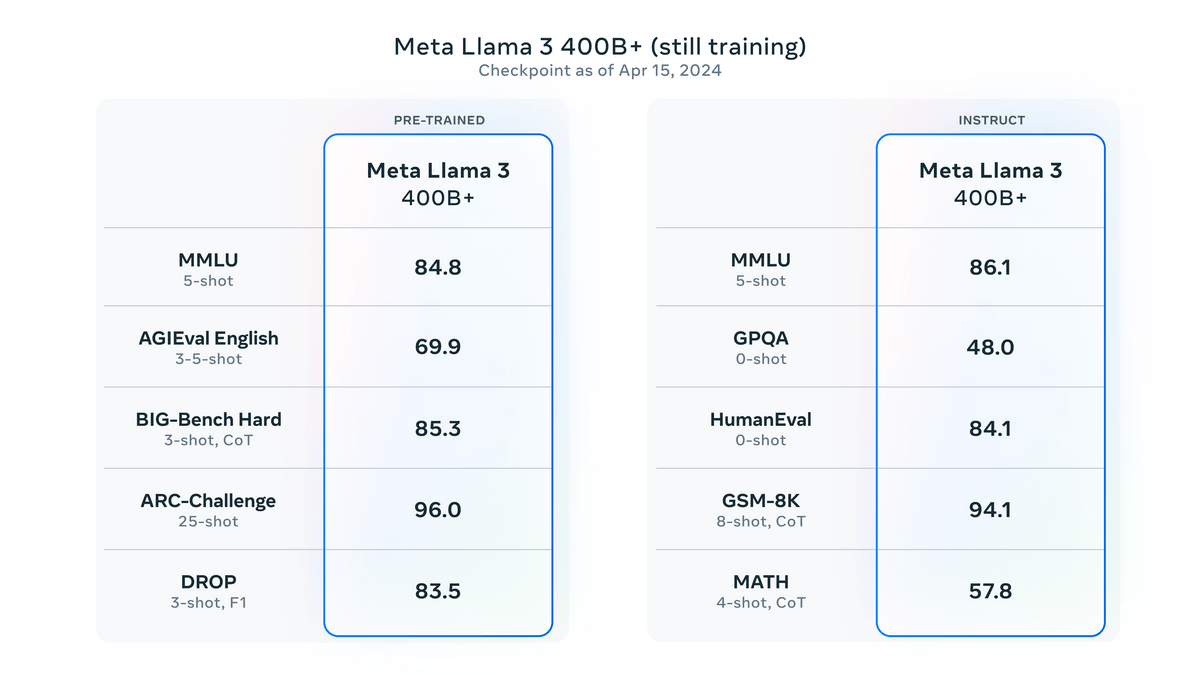
Llama 3においては、今回登場した「Llama 3 8B」「Llama 3 70B」の2つのモデルだけでなく、今後さらにさまざまなモデルが登場する予定と述べられています。そのうち最大のモデルはパラメーター数が4000億(400B)となっており、現在トレーニング中とのこと。400Bモデルの2024年4月15日時点でのベンチマーク結果は下図の通りです。
今後数カ月にわたってマルチモーダルや複数言語で会話する機能、長大なコンテキストウィンドウ、より強力な全体的な機能などの新機能を備えたモデルがリリースされるとのこと。Llama 3のトレーニング完了後には詳細な研究論文を公開するとも述べられています。
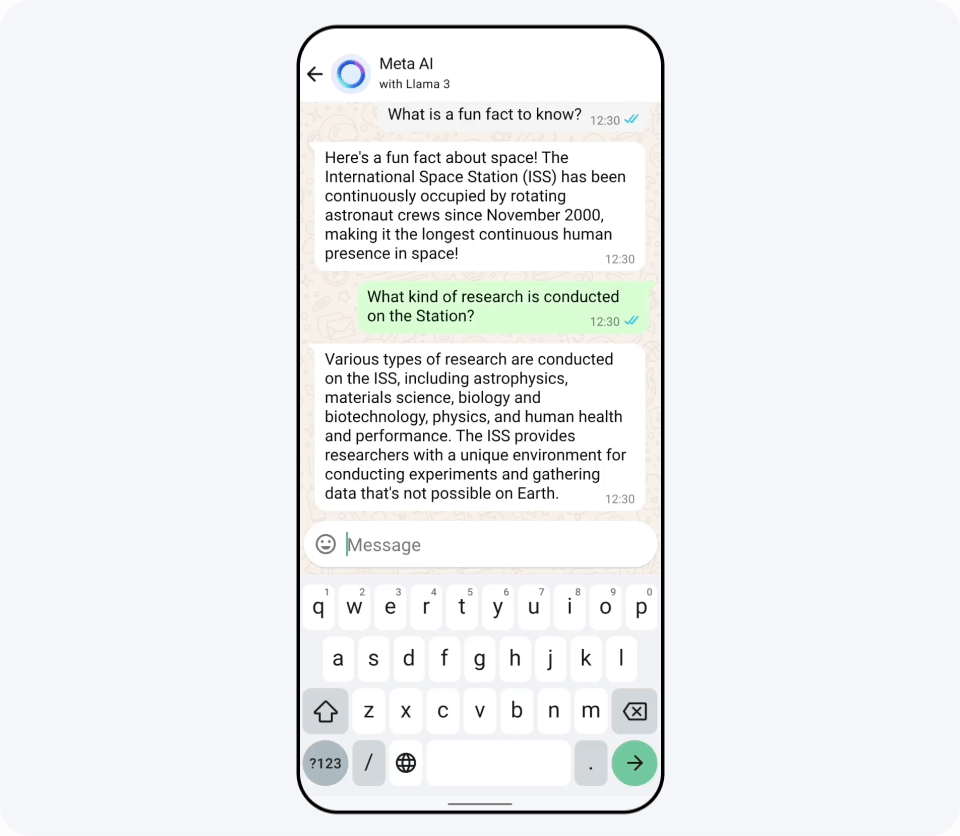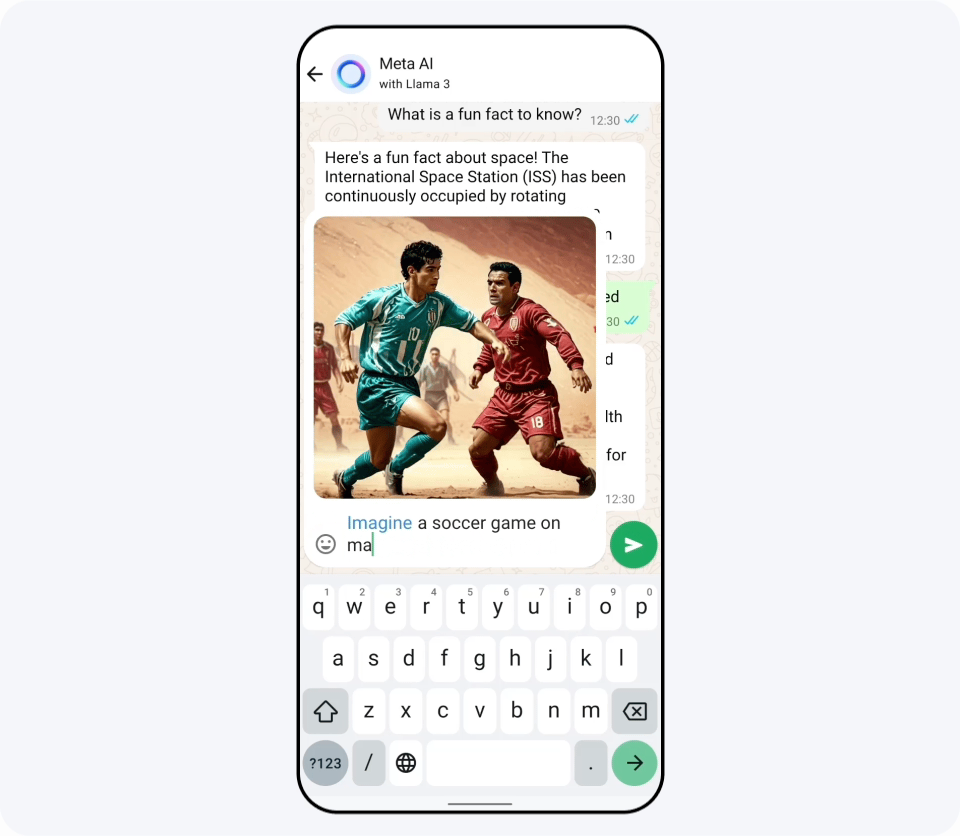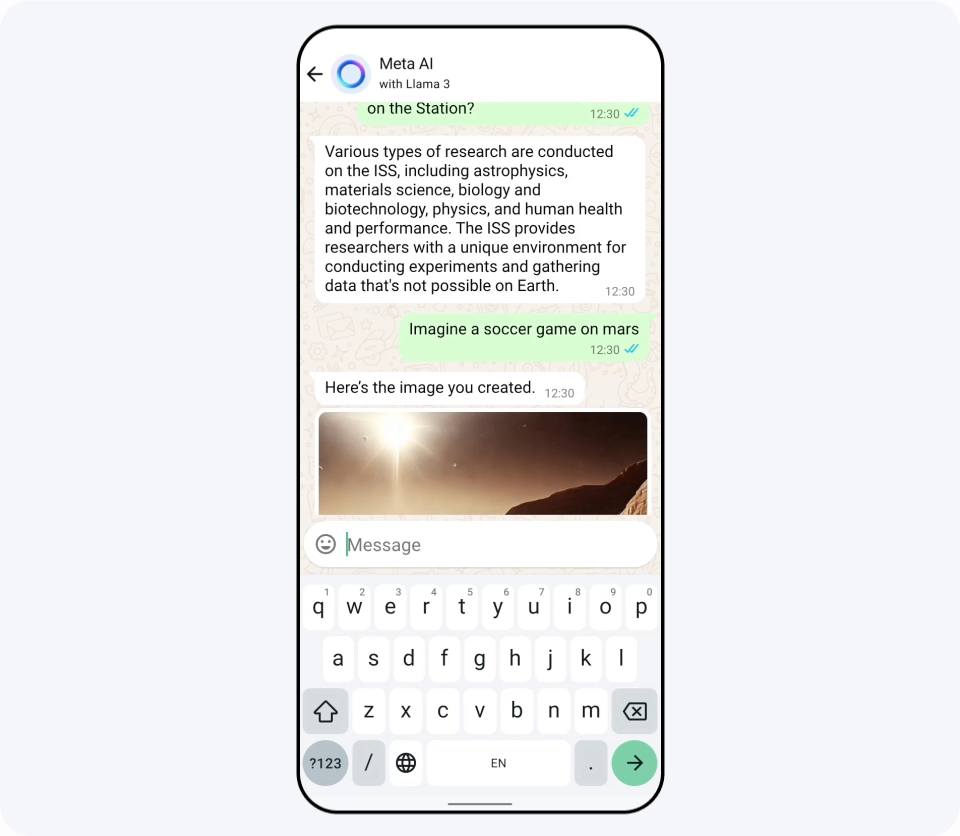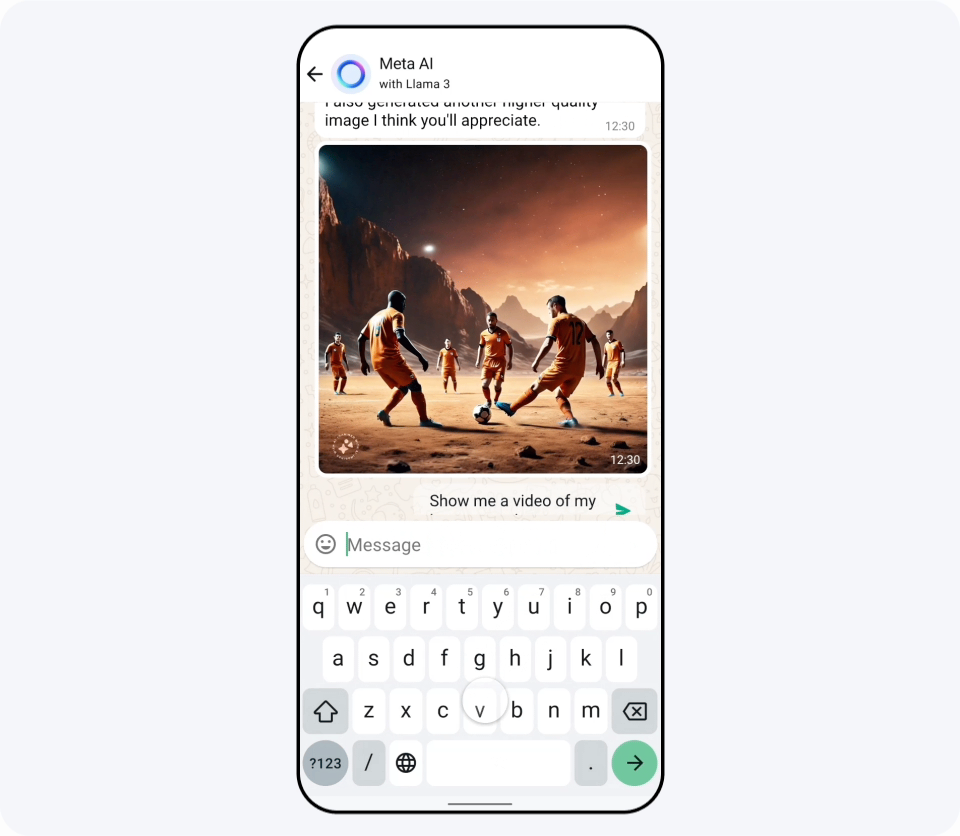
Llama 3のリリースと同時に、FacebookやInstagram、WhatsAppなどにLlama 3で構築された「Meta AI」が登場しました。記事作成時点ではMeta AIは英語専用で、アメリカ合衆国のほか、オーストラリアやカナダなど英語圏の国でリリースされています。下図の通り、非常に高速に動作するため入力中にリアルタイムでどんな画像が生成されるかを確認できるとのこと。
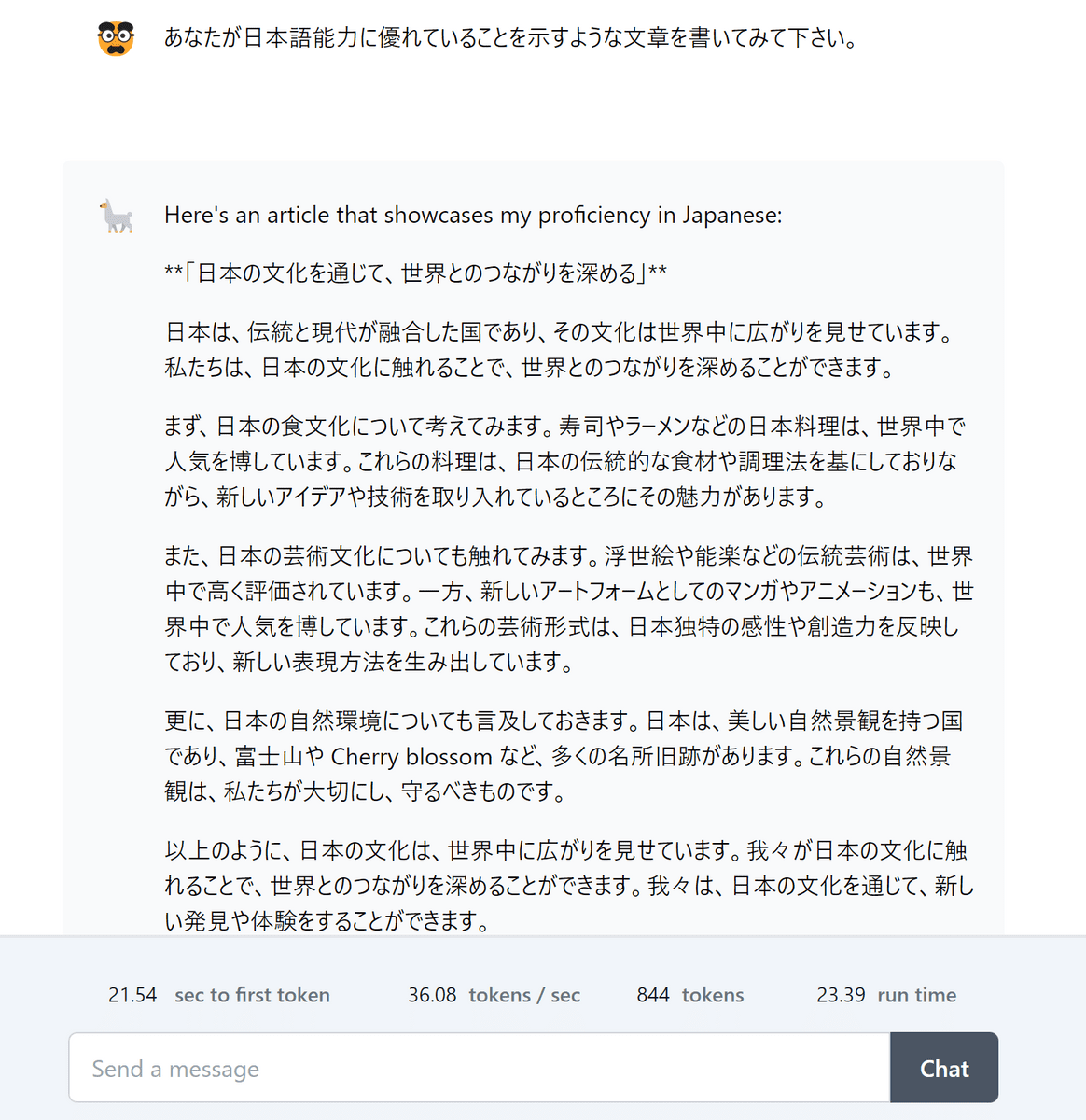
Llama 3はReplicateで実際に試せるほか、NvidiaのNIMやCloudflareのWorkers AIで既に導入済みであることが発表されています。Replicateで日本語能力について質問してみると下図のような回答が返ってきました。「英語ほどのパフォーマンスではない」と公式に言及されているものの、日本語で使用することはできそうです。
・関連記事
無料で商用利用可能なオープンモデル「Mixtral 8x22B」が登場、高いコーディングと数学の能力を持つ - GIGAZINE
OpenAIの次世代大規模言語モデル「GPT-5」が2024年夏に公開されるとの報道 - GIGAZINE
Microsoftが1.58ビットの大規模言語モデルをリリース、行列計算を足し算にできて計算コスト激減へ - GIGAZINE
日本語対応でGPT-4よりも高性能な大規模言語モデル「Command R+」が登場したので使ってみた、無料でダウンロードしてローカル動作も可能 - GIGAZINE
GPT-4を上回る性能で画像と文章を同時に処理できる日本語対応マルチモーダルAI「Claude 3」がリリースされる - GIGAZINE
・関連コンテンツ