Googleが世界最大のデータセット「Open Images Dataset」の最新版を公開

2016年にGoogleは機械学習のためのデータセット「Open Images」を初めてリリースしましたが、この最新版である「Open Images Dataset V5」を2019年5月8日付でGoogleが新たに公開しました。
Google AI Blog: Announcing Open Images V5 and the ICCV 2019 Open Images Challenge
https://ai.googleblog.com/2019/05/announcing-open-images-v5-and-iccv-2019.html
機械学習は学習のもととなる膨大なデータを必要とするため、Googleは2018年に画像データセット「Open Images v4」をリリースしていました。これは900万枚の画像に対してラベルとバウンディングボックスが付与されたもの。Open Images v4は600のカテゴリに分けられたオブジェクトに対し、合計1540万個ものバウンディングボックスが付されており、30万個以上にのぼる画像関連の注釈やロケーションの注釈がついた、世界最大のデータセットでした。
そして2019年5月8日付でGoogleは新たにOpen Images Dataset V5をリリース。
Open Images Dataset V5
https://storage.googleapis.com/openimages/web/index.html
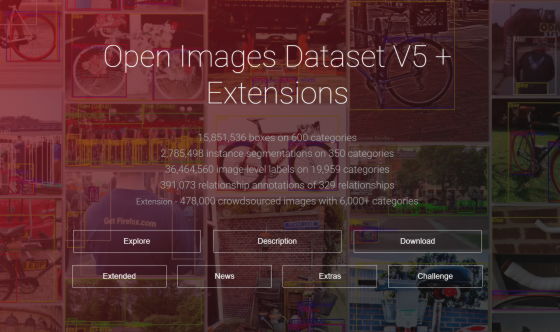
Open Images Dataset V5の特徴はオブジェクトのインスタンスのために350カテゴリにわたる280万個のセグメンテーションマスクを用意していること。バウンディングボックスとは違い、このセグメンテーションマスクはオブジェクトが存在する場所しか認識しません。セグメンテーションマスクはオブジェクトの輪郭をマークし、空間的な広がりを細部に至るまで特徴づけます。Google開発チームはこの精度に非常にこだわったとのことで、例えば猫であればそのしっぽまで認識し、荷物や人を運ぶラクダであれば人や荷物までマスクがかかるようにしました。何よりも、過去のいかなるデータセットよりもさまざまなカテゴリのオブジェクト、そして実例を含んでいるという点が重要だと開発チームは述べています。

(PDFファイル)インタラクティブ・セグメーション・プロセスによって生み出されたマスクは手作業のドローイングよりもずっと効率的で、かつIntersection-over-Union(IoU)で84%を記録するほどの高い正確性をほこっています。Googleはマスクの検証&テストセットも公開しており、2つをあわせるとOpen Images Dataset V5が複雑なものを詳細に至るまでとらえることができる能力は「ほとんど完璧」だと述べています。

マスクのほかにも、Googleは人間が検証した新しい画像レベルのラベルを640万個追加しており、これによって2万近いカテゴリ・3650万個のラベルが提供されることになりました。さらに、検証&テストセットの600のカテゴリにおいて注釈の密度を向上させるなど、オブジェクト検知モデルの正確性をより高めています。
なお、Open Images Dataset V5のリリースにあわせて、Googleは物体検出コンペティション「Open Images Challenge 2019」の開催を発表。これはKaggleがOpen Images V5を使用して開催するもので、2019年6月3日から受け付け開始となっています。
Open Images Challenge 2019
https://storage.googleapis.com/openimages/web/challenge2019.html
・関連記事
機械学習によって解決できるかどうかが証明不可能な学習モデルが発見される - GIGAZINE
「AI」と「機械学習」は何がどのように違うのか?をわかりやすく解説するとこうなる - GIGAZINE
初心者向け「機械学習とディープラーニングの違い」をシンプルに解説 - GIGAZINE
誰でも深層強化学習のスキルを身に付けて活用できるための教育リソース「Spinning Up」をOpenAIが発表 - GIGAZINE
機械学習でコンピューターが音楽を理解することが容易ではない理由 - GIGAZINE
・関連コンテンツ