ChatGPTなど数々の高性能AIを生み出した仕組み「Attention」についての丁寧な解説ムービーが公開される
さまざまな数学的トピックをムービー形式で解説するサイト「3Blue1Brown」において、ChatGPTに代表されるAIを形作っている「Transformer」構造の心臓部「Attention(アテンション)」についての解説が行われています。
3Blue1Brown - Visualizing Attention, a Transformer's Heart | Chapter 6, Deep Learning
https://www.3blue1brown.com/lessons/attention
AIの中身と言える大規模言語モデルのベースとなる仕事は「文章を読んで次に続く単語を予測する」というものです。
文章は「トークン」という単位に分解され、大規模言語モデルではこのトークン単位で処理を行います。実際には単語ごとに1トークンという訳ではありませんが、3Blue1Brownは単純化して「1単語で1トークン」として解説しています。

大規模言語モデルはまず最初に、それぞれのトークンを高次元ベクトルへと関連付けます。
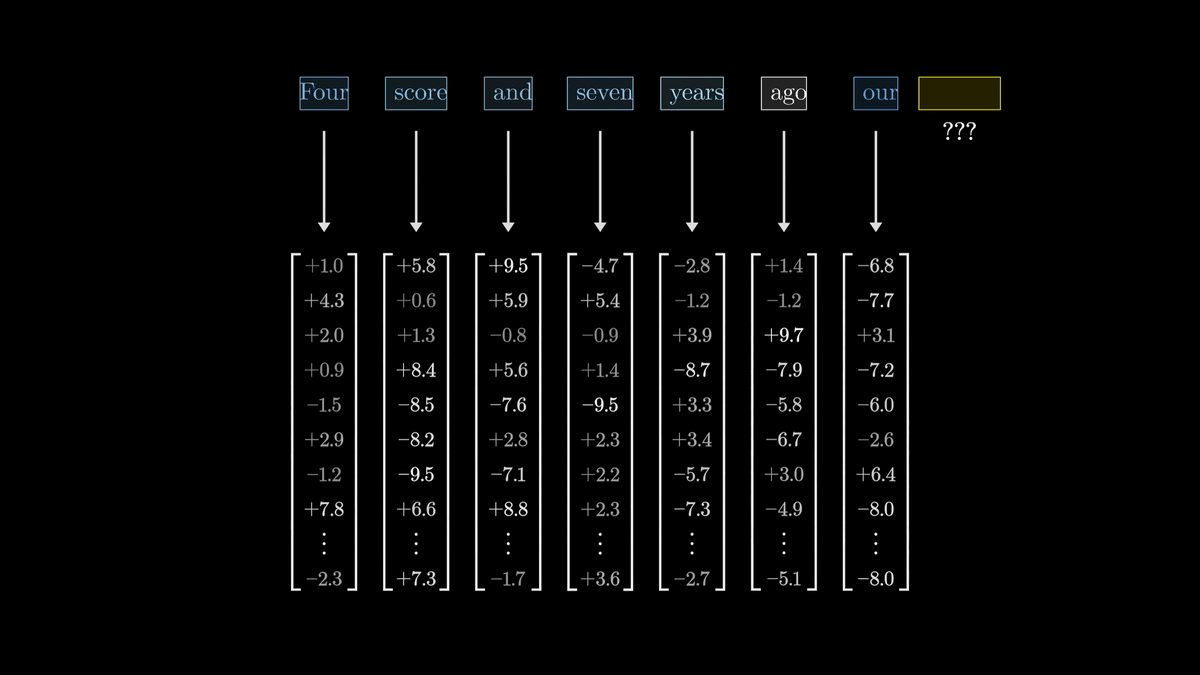
この行為は埋め込み(Embedding)と呼ばれています。
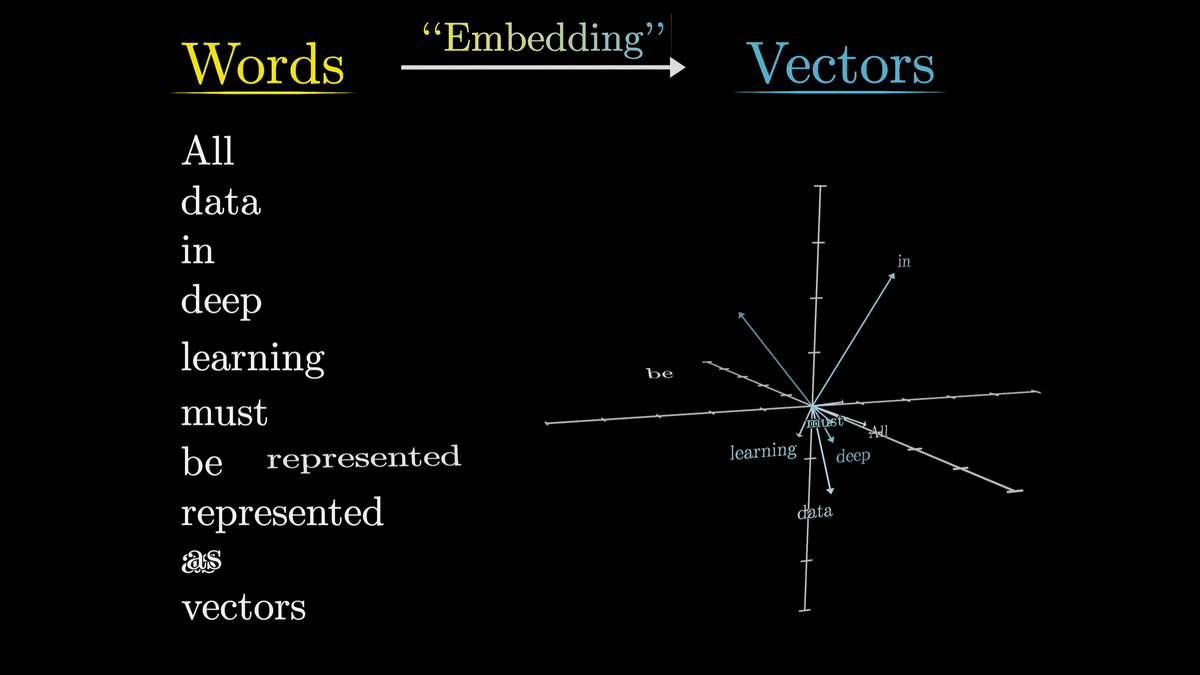
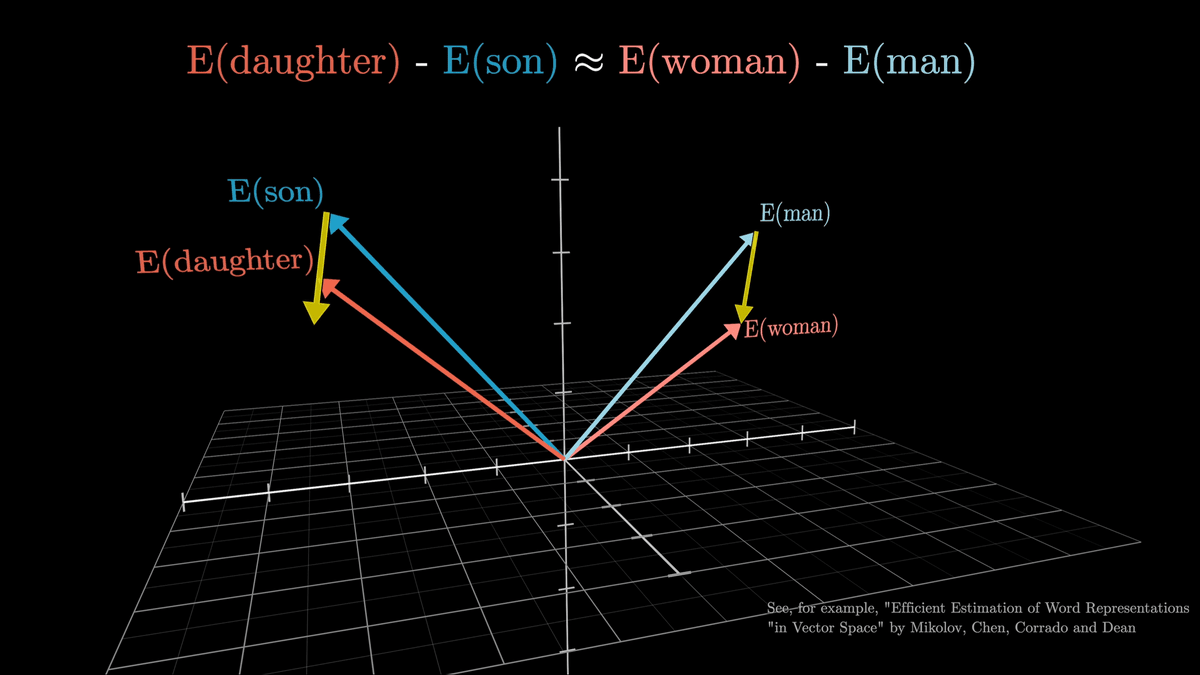
高次元ベクトル空間の一面を見てみると、「娘ー息子」と「女性ー男性」が似たようなベクトルを持つように、さまざまな意味の関連付けが行われています。
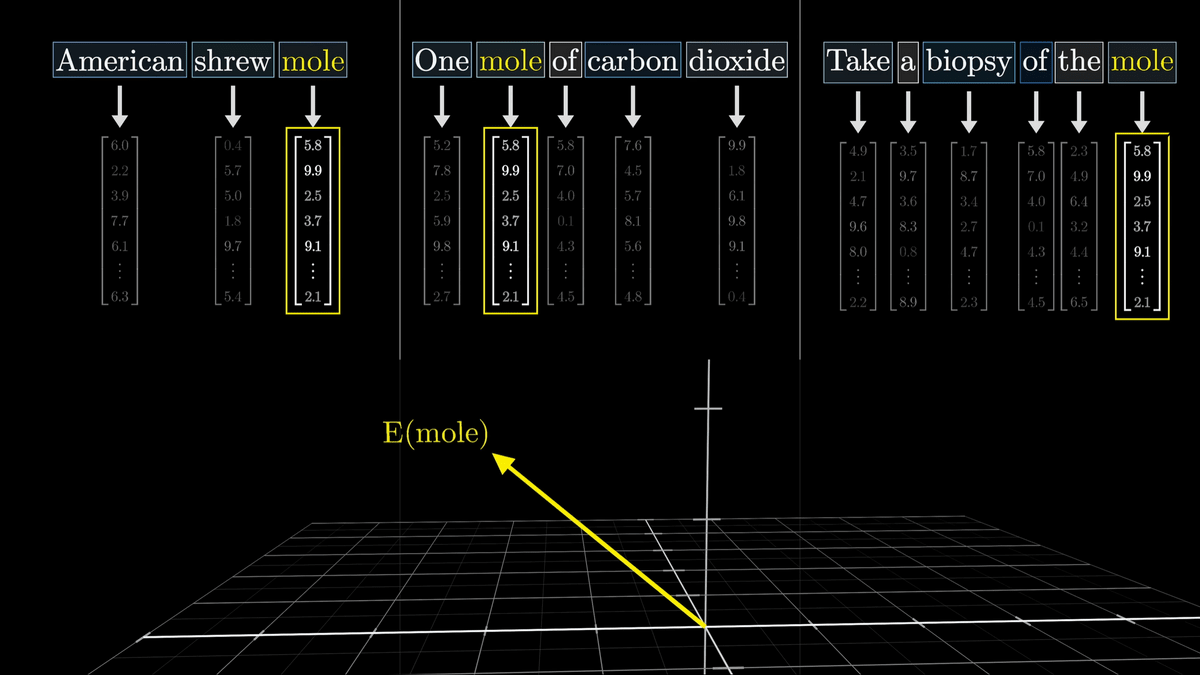
しかし同じ単語でも状況によって異なる意味を表す場合が存在しており、それぞれの単語だけを元に適切に埋め込みを行うのは難しくなっています。Transformerの役割は、周りの文脈を使用して単語の適切な意味を埋め込むことです。

シンプルな埋め込みは単なる変換テーブルのため、「mole」という同じ単語なら同じ高次元ベクトルへと関連付けられます。
ここで、アテンションには周囲の単語との関連度合いを計算して適切にベクトルを調整してもらいたいわけです。
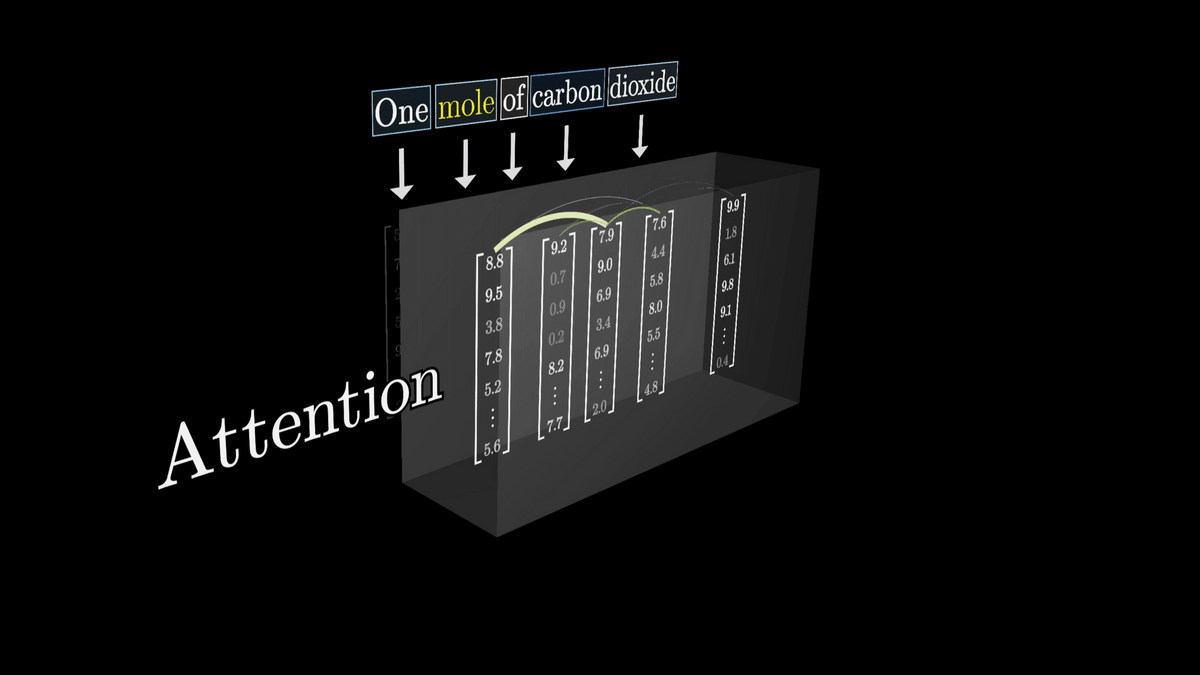
そうすることで同じ1つの単語でも、周囲の文脈を元に適切なベクトルが生成できます。

はっきりと意味が分かれている単語のベクトルを調整するほか、「塔」と「エッフェル塔」のように曖昧な意味のベクトルをより具体的な意味のベクトルに調整するのもアテンションの仕事です。

アテンションは別の単語の埋め込みとしてエンコードされた情報を引っ張ってきて単語の埋め込みを調整できるわけです。
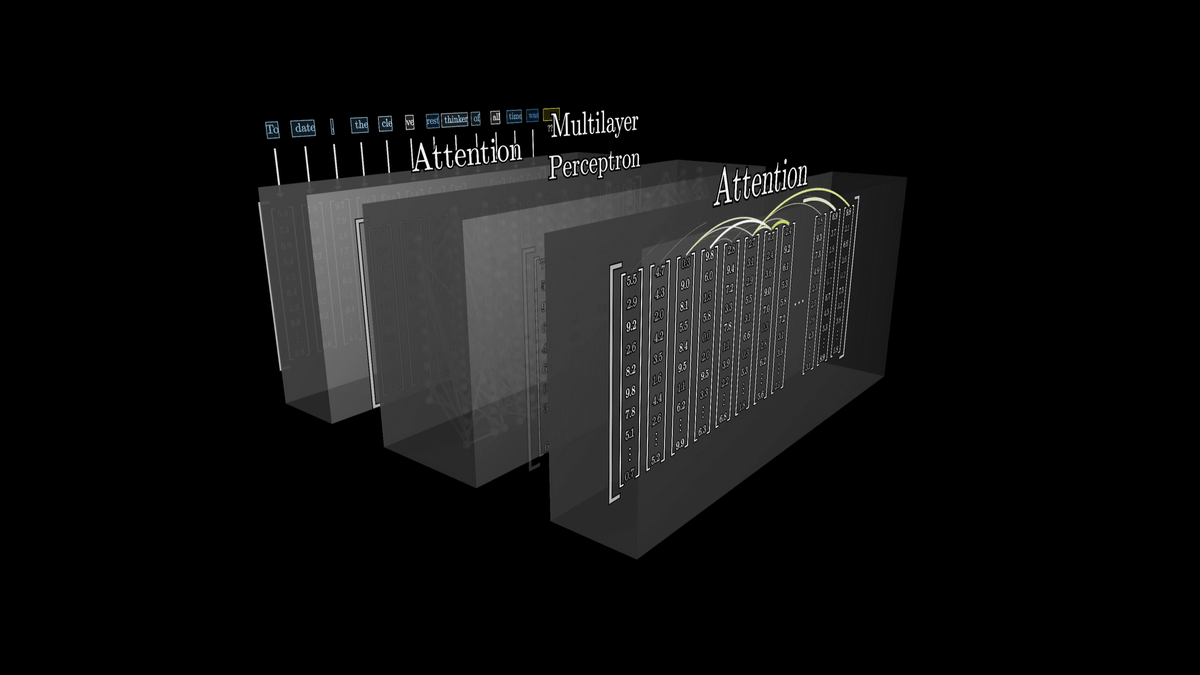
場合によっては非常に遠い位置の単語から意味を引っ張ってきたり、また1つの単語としてはかなり多くの情報を詰め込んだりすることもあります。

多くの異なるアテンションブロックを含むネットワークを大量のベクトルが流れた後、「次の単語を予測する」という仕事を行うのはシーケンスの最後のベクトルの関数です。
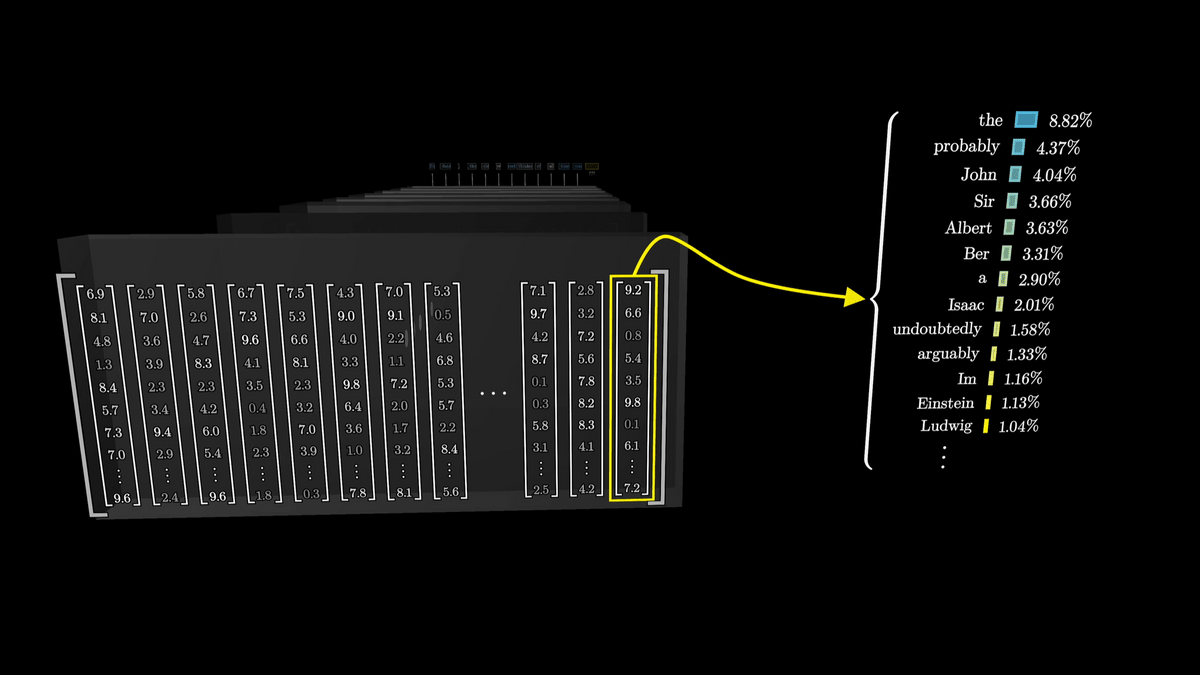
例えば、推理小説のほぼ全文を入力して最後の「therefore, the murderer was(従って、犯人は)」の次を予測するタスクの場合には、最後のトークンである「was」を埋め込んでいたベクトルが全てのアテンションブロックによって更新されて非常に多くの情報を持つようにする必要があるわけです。

このとき、1回の入力であるコンテキストウィンドウ内の関連する全ての情報をなんとかして埋め込む必要があります。

アテンションが行うべき仕事について把握したところで、単純な例を元にどう計算するのかを考えていきます。ここでは、「形容詞+名詞」という形の時に名詞のベクトルを形容詞の内容をベースに更新する方法を考えます。

この単純な例では「Multi-headed attention」ではなく、その1枚分である「Single head of attention」の計算を確認します。

最初に確認したとおり、それぞれの単語はまず文脈に関係のない対応表に基づいてベクトル化されます。
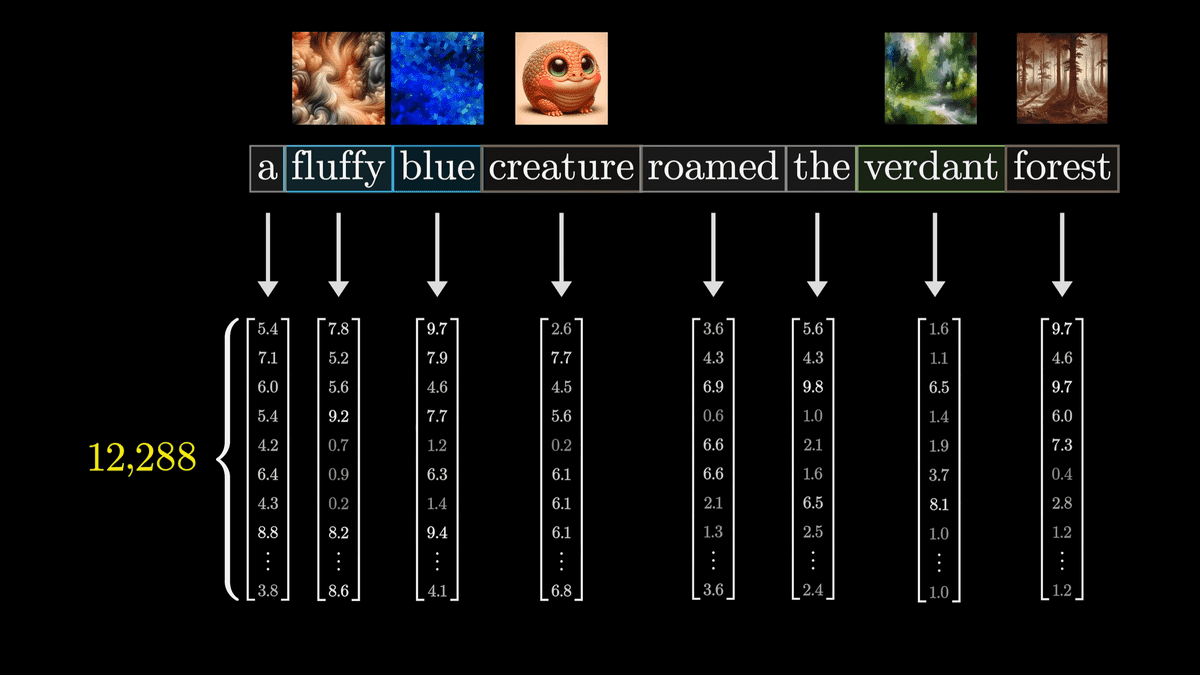
ただ、この表現は正確ではなく、実際には単語だけでなく位置情報も含めてベクトル化されるとのこと。
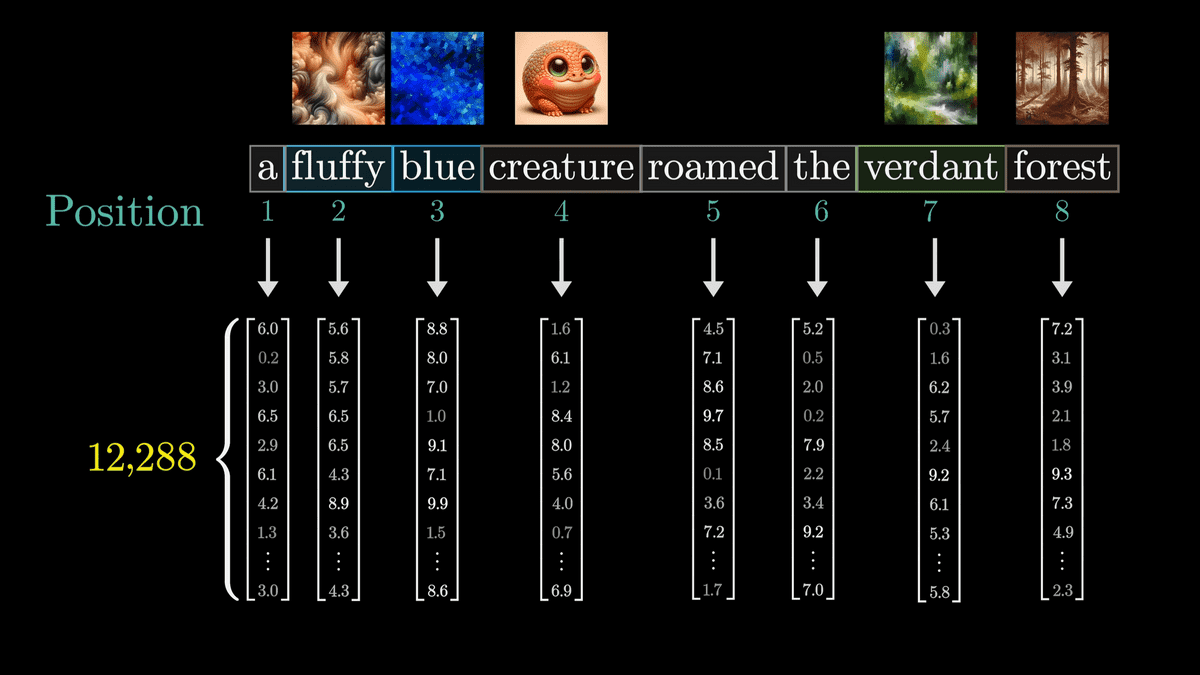
ここで生成されたベクトルを「E」で表すことにします。今回の例では「E2」や「E3」などの形容詞の意味を取り込んだ新たな「E4'」を生成するのが目標です。
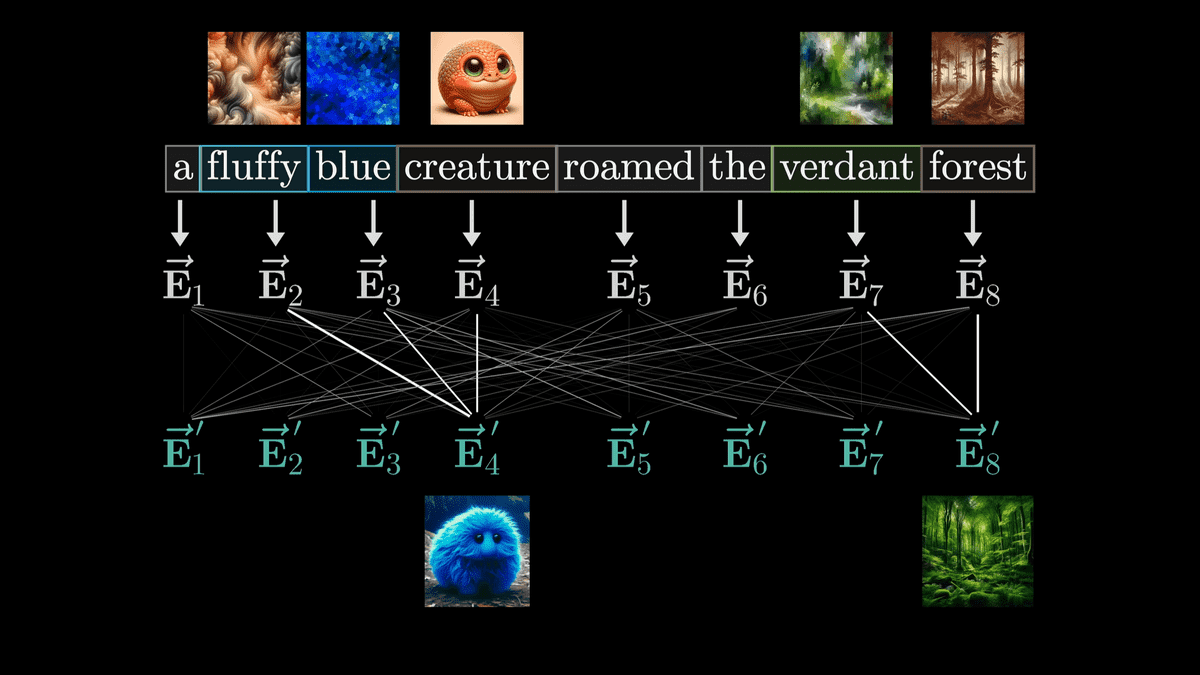
またE4'の計算においては「行列とベクトルの積」という形で計算を行いたいものです。というのもディープラーニングの世界では行列のパラメーターはデータを元にトレーニング可能だからです。

なお、実際のディープラーニングの動きは複雑で解析するのが難しいため、3Blue1Brownはわかりやすさを優先して「形容詞のベクトルを元に名詞のベクトルを更新する」という例を使っているとのこと。
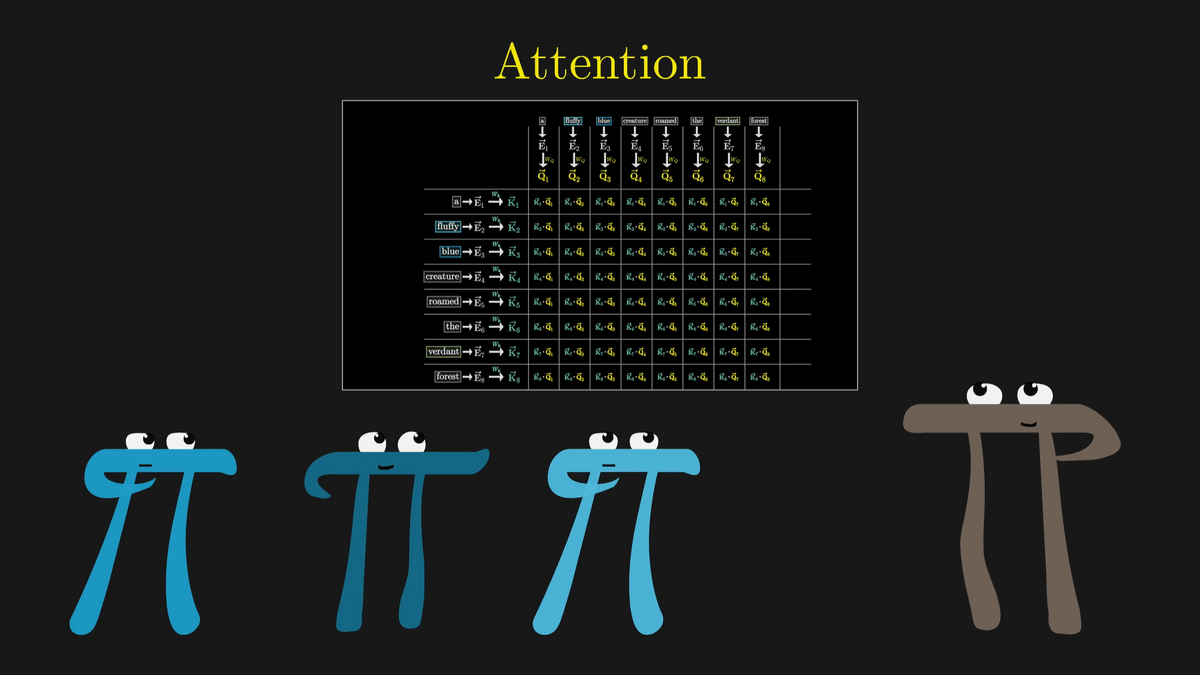
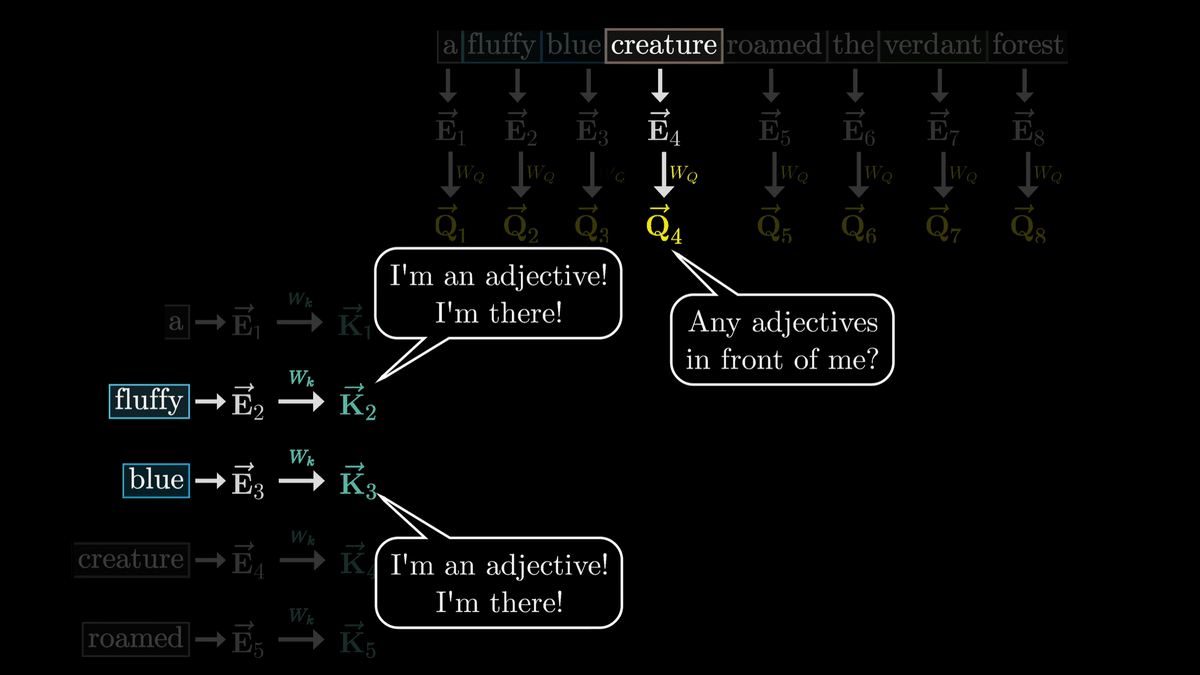
さて、最初のステップでは名詞が「私の前に形容詞は居る?」と問いかけ、形容詞たちが「居るよ!」と返答する仕組みを見ていきます。
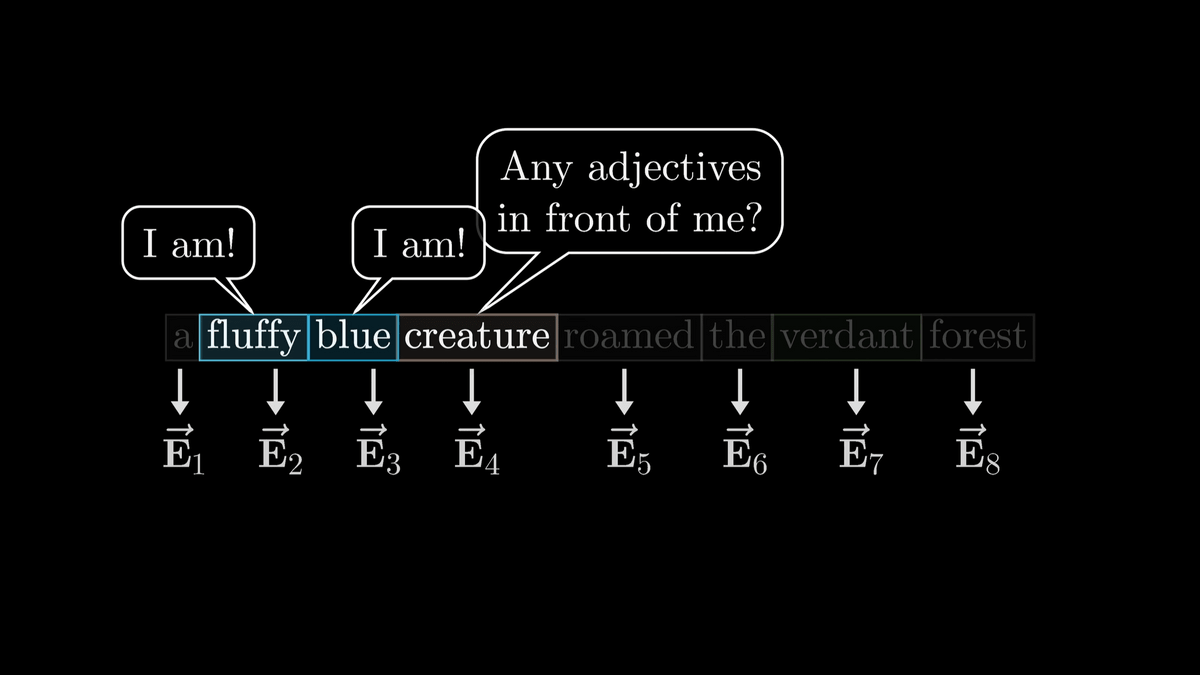
名詞の質問は「Query(クエリ)」というベクトルにエンコードされます。このクエリは128次元のように単語の埋め込みベクトルと比べるとかなり少ない次元数とのこと。
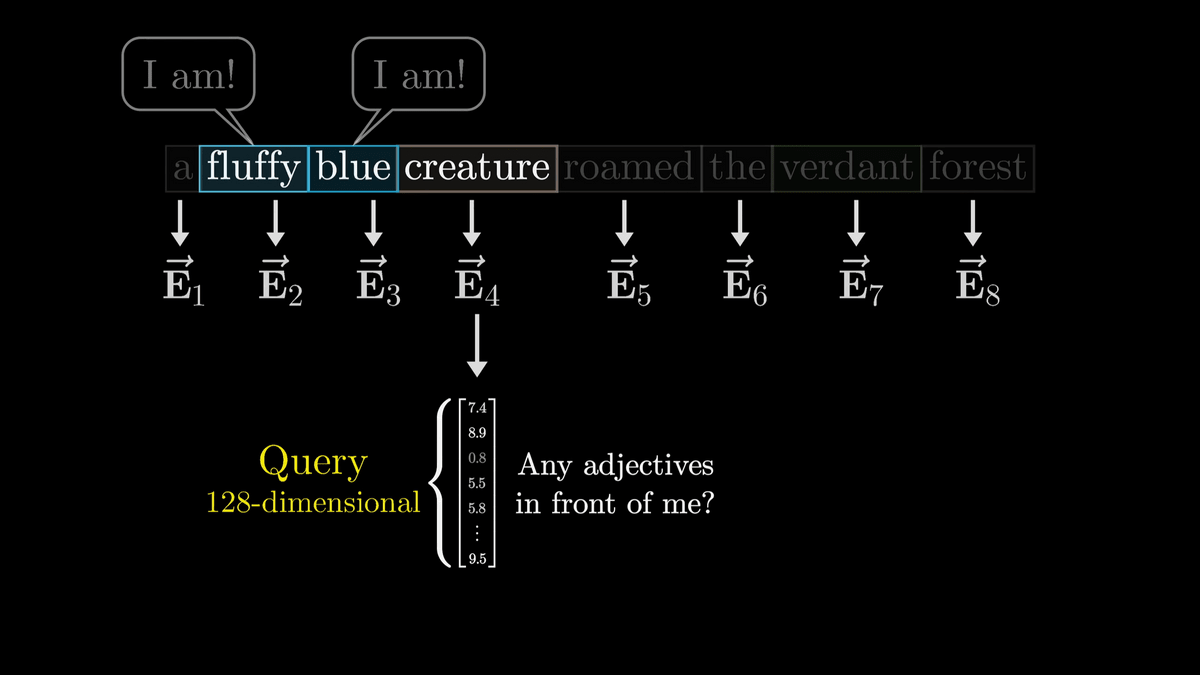
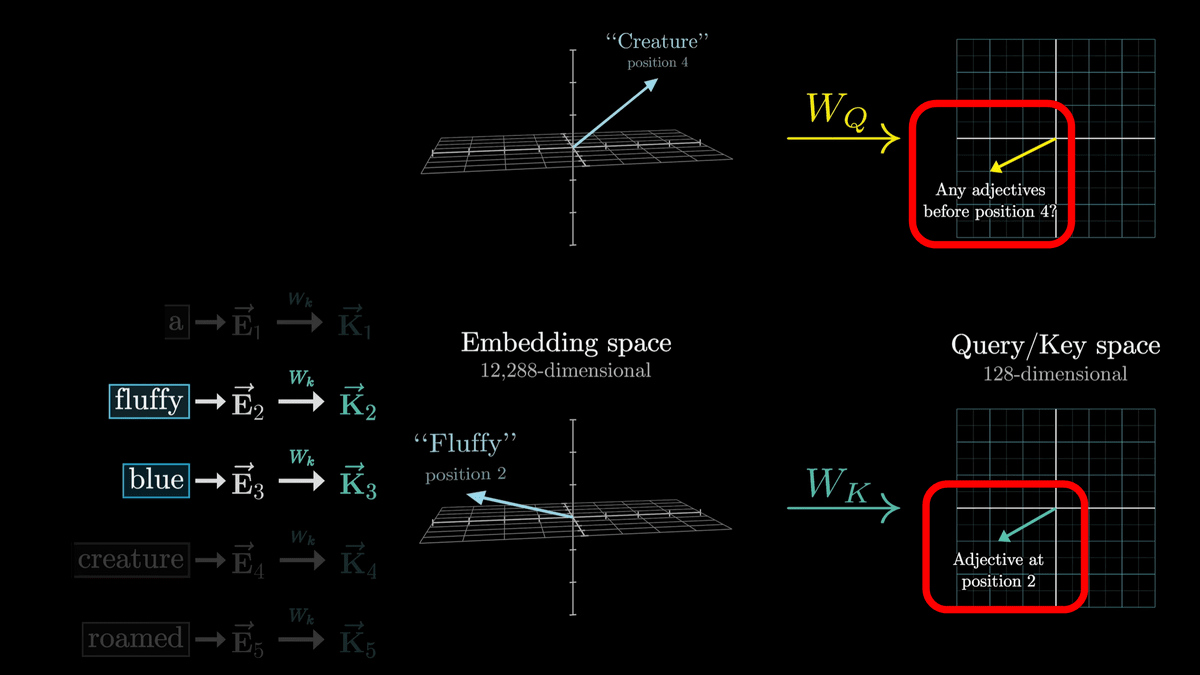
クエリの計算は下図のように「W_Q」で表されている行列と「E4」の積を取ることで行われます。
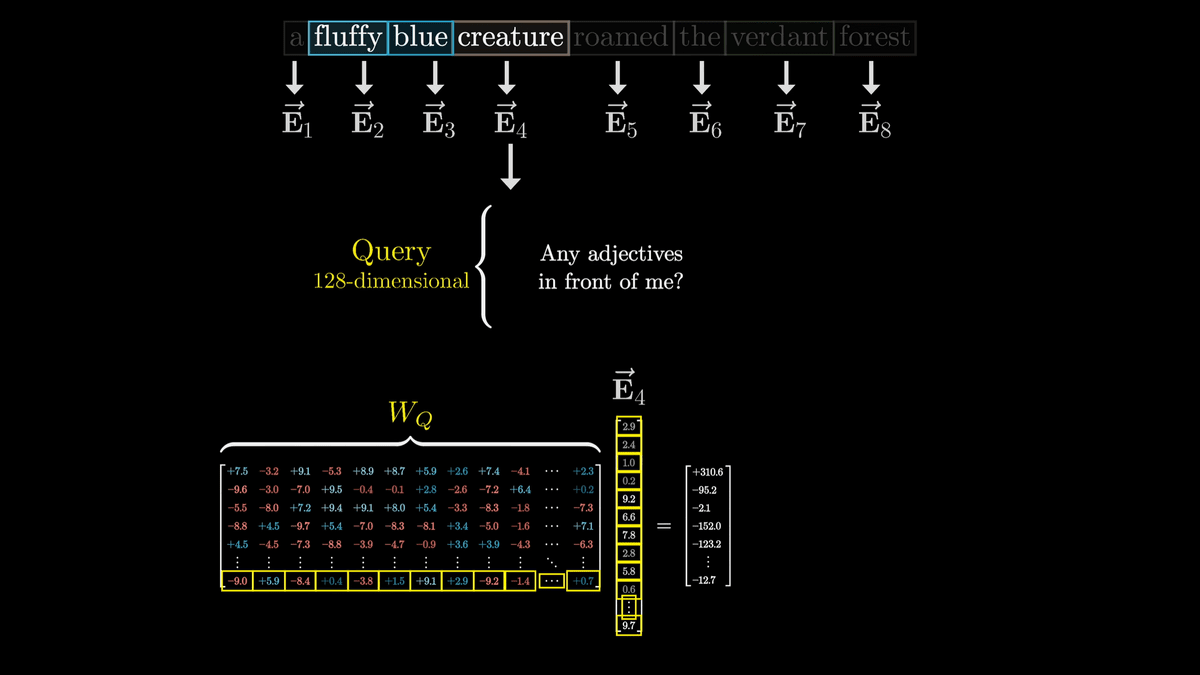
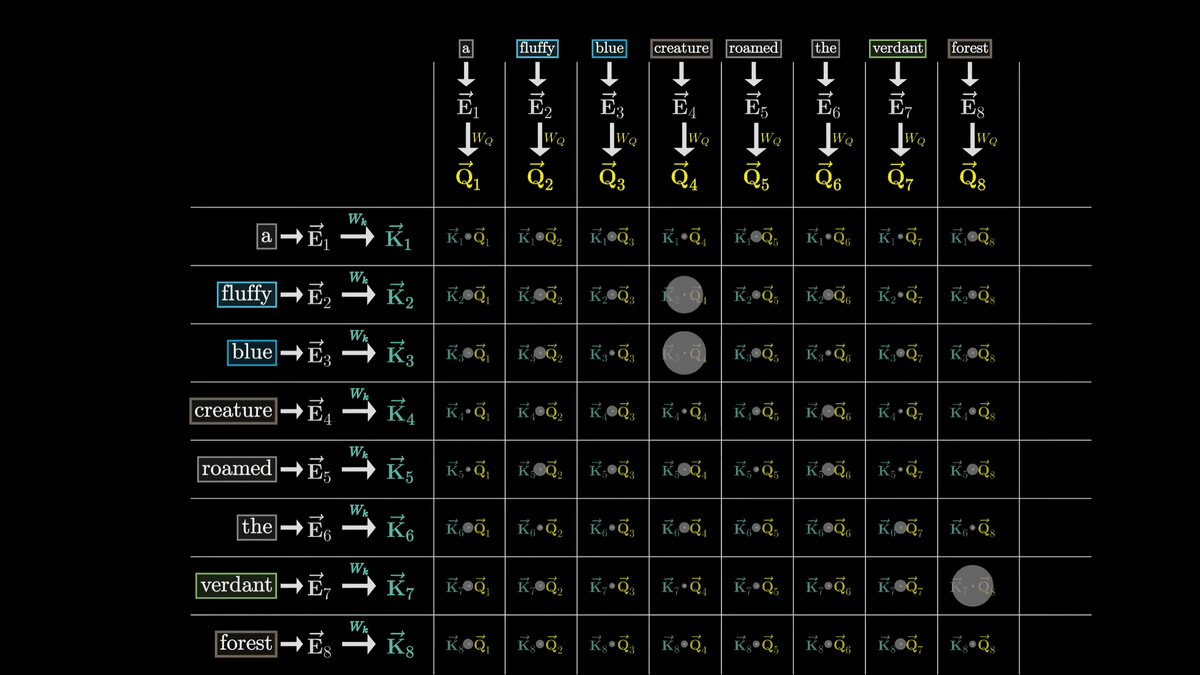
このように、行列との積を取ってベクトルを更新する操作を矢印で表現すると下図のようになります。下図ではそれぞれのトークンが埋め込まれた「E」ベクトルが「W_Q」によってトークンごとに1つの「Q」ベクトルに変換されています。
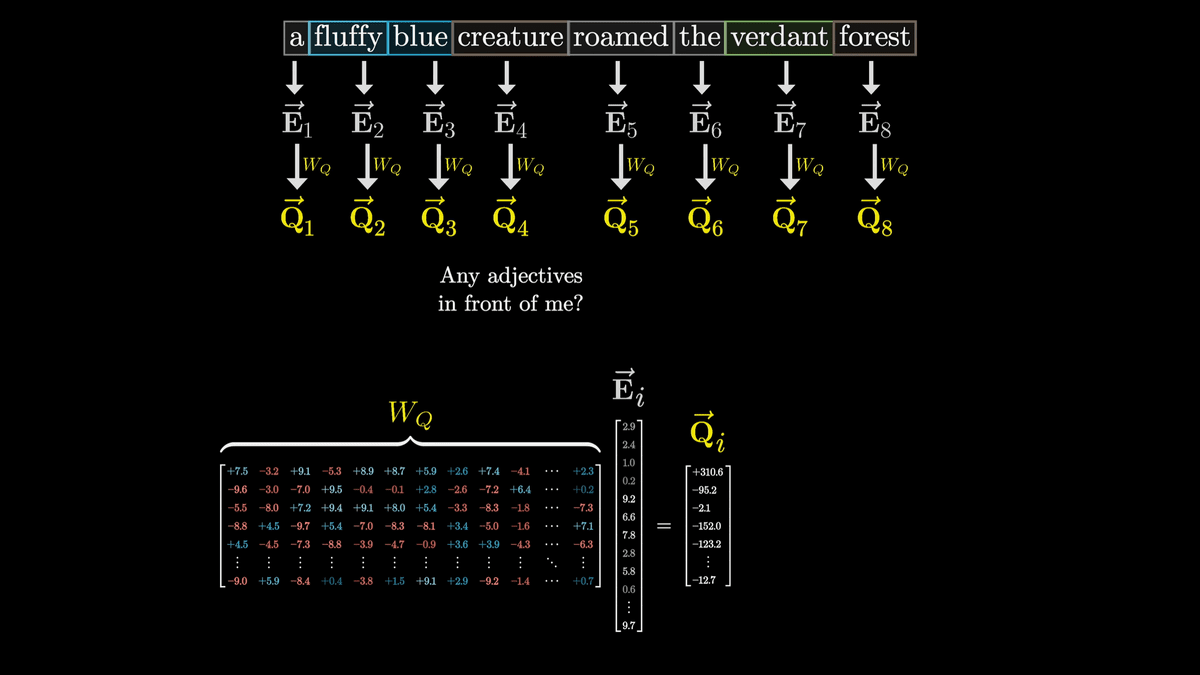
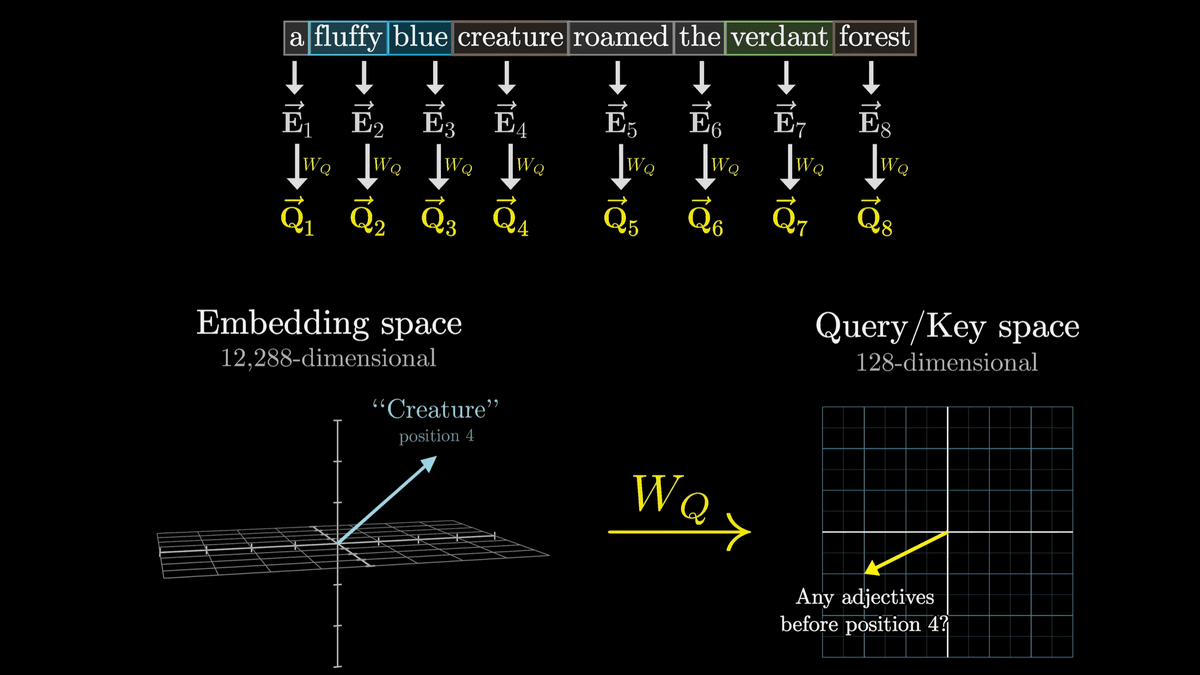
W_Qはトレーニングによって調整されるパラメーターであり、実際の挙動を解析するのは難しいものの、分かりやすくするため名詞のトークンが埋め込まれたベクトルを「私の前に形容詞は居る?」という質問を意味するベクトルに変換していると考えます。
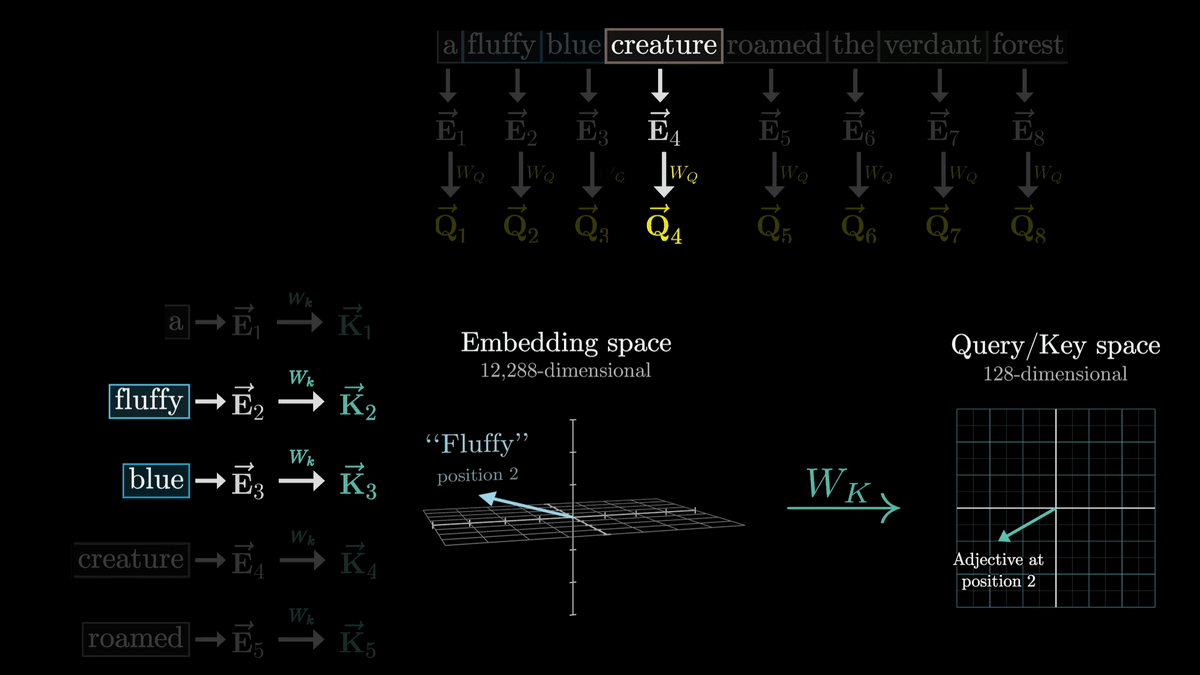
ここで、W_QによってトークンごとにQベクトルを生成したのと同様に、W_kを使用してトークンごとにKベクトルを生成します。KはKeyベクトルと呼ばれています。
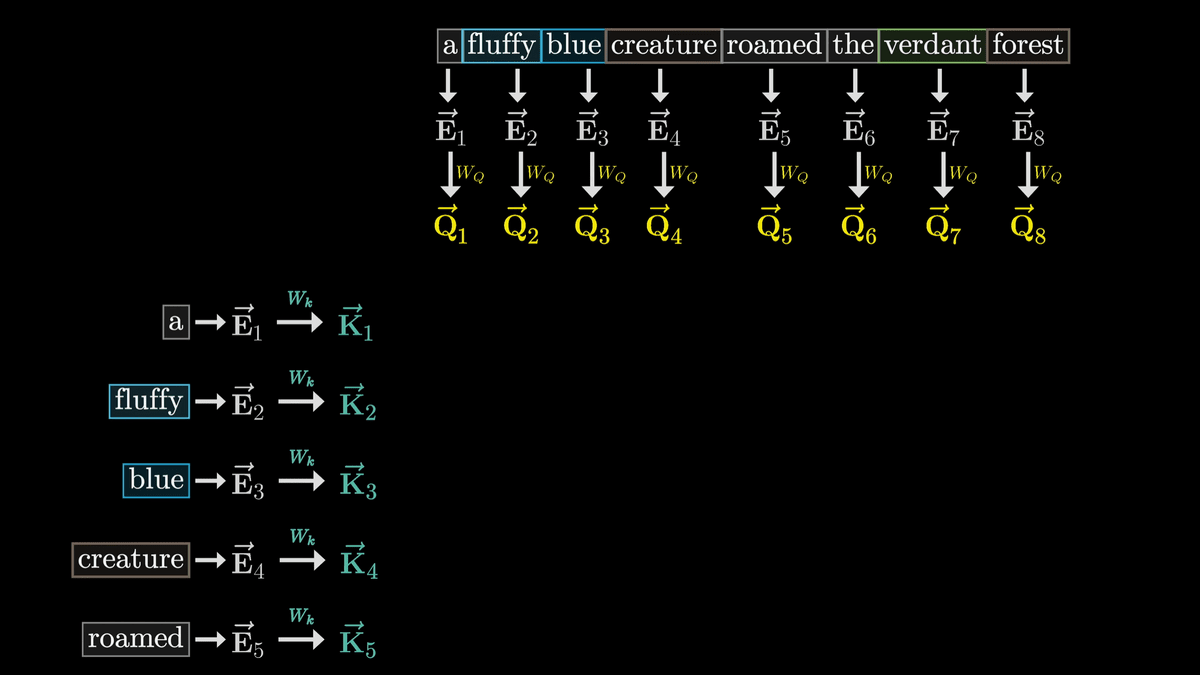
概念的には、それぞれのKベクトルはQベクトルの質問に答えていると考えることができます。
W_kはW_Q同様にトレーニング可能なパラメーターの行列であり、それぞれのトークンの埋め込みベクトルを小さい次元のQuery/Key空間にマッピングしています。
Keyが質問であるクエリに反応しているかどうかはQベクトルとKベクトルが似たようなベクトルになるかどうかで判断します。
この類似度はそれぞれのベクトルのドット積を取ることで計算可能です。
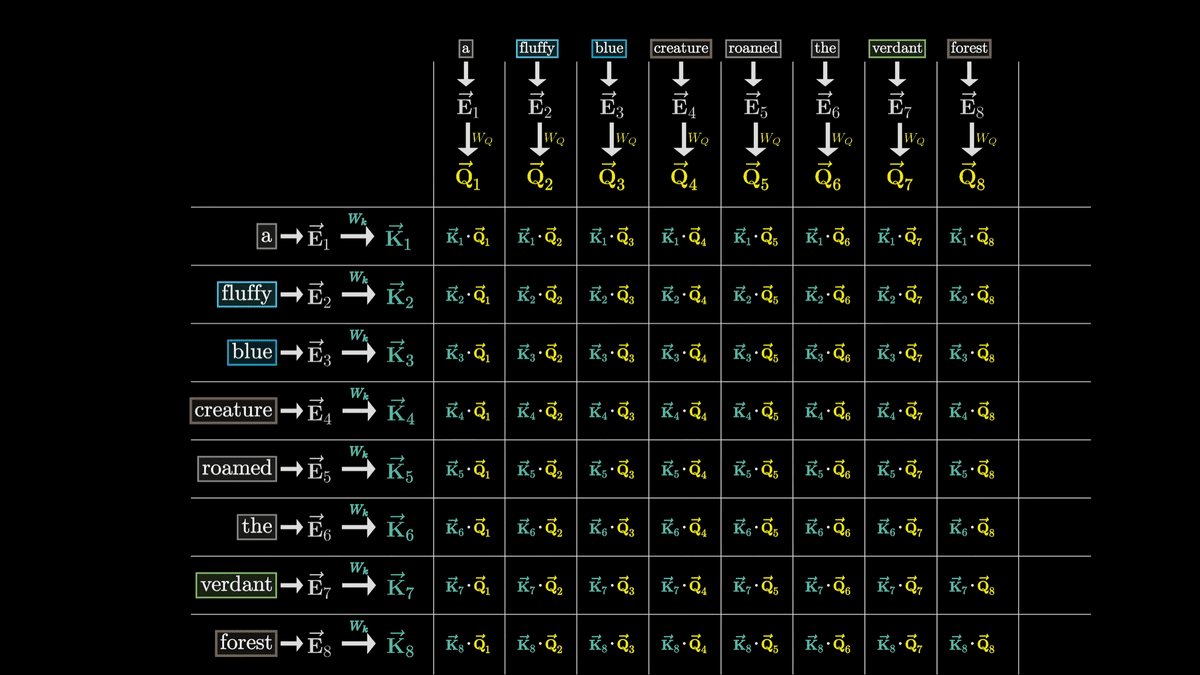
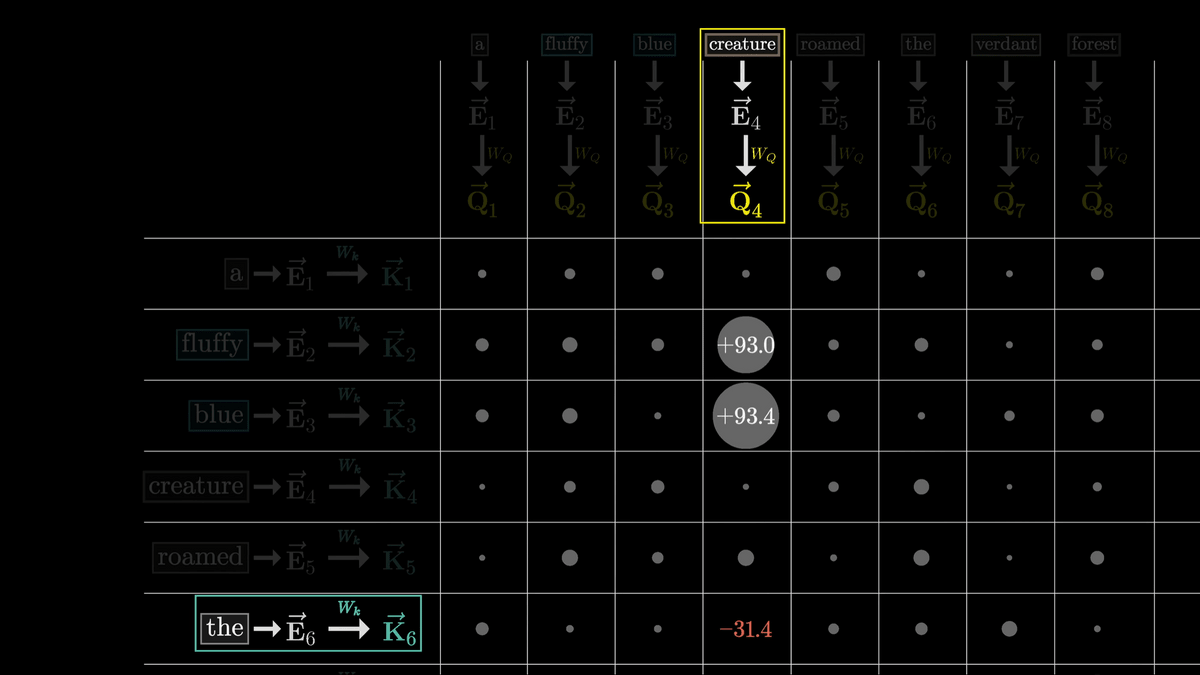
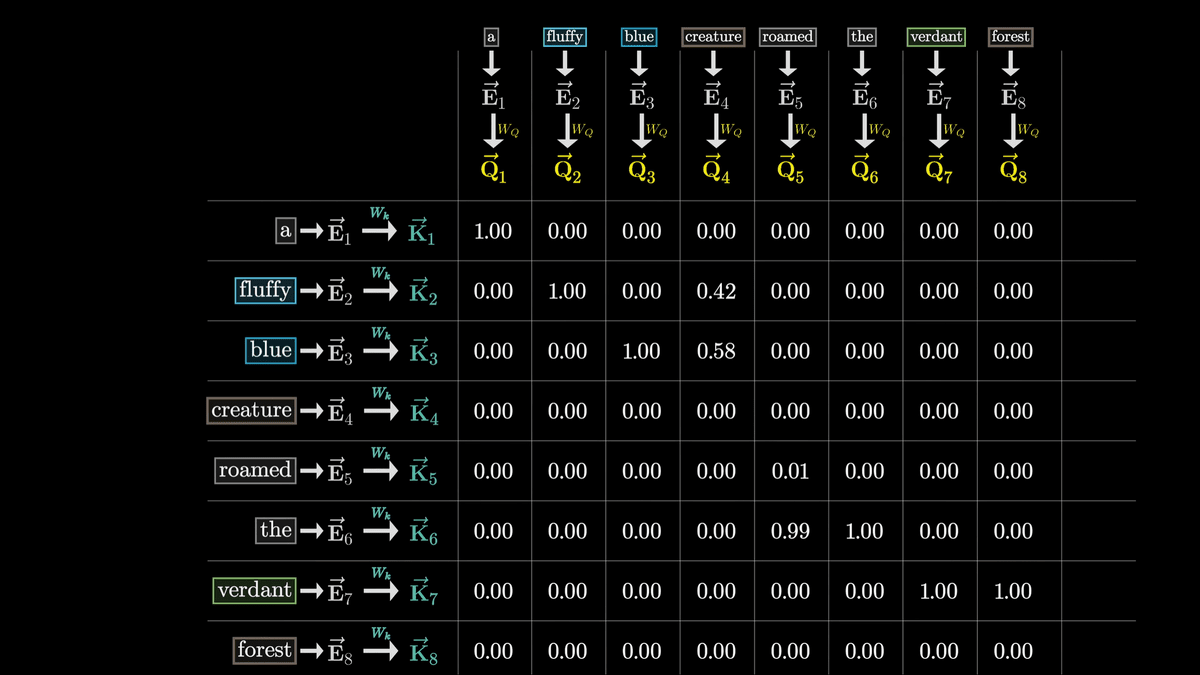
今回の場合、Q4とK2・K3、Q8とK7が似たベクトルになっていることが分かります。
「fluffy」「blue」という形容詞の埋め込みがcreatureという名詞に密接に関連していることを表しているわけです。

一方、全く関連のない「the」のKベクトルと「creature」のQベクトルのドット積は非常に小さくなっています。
グリッドの全ての値を計算することで、それぞれの枠に負の無限大から正の無限大までの数値が入力されます。
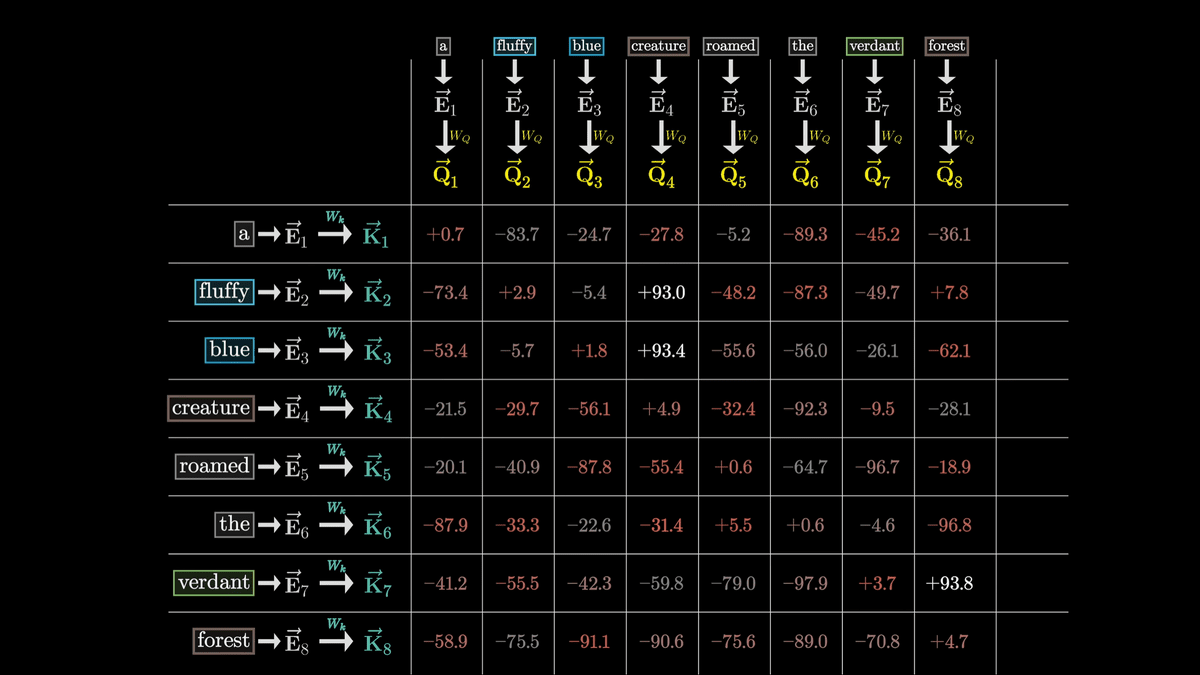
しかし、それぞれの単語との相対的な関連度合いを取得するため、任意の実数ではなく合計が1になるウェイトのような形式に変換したいものです。
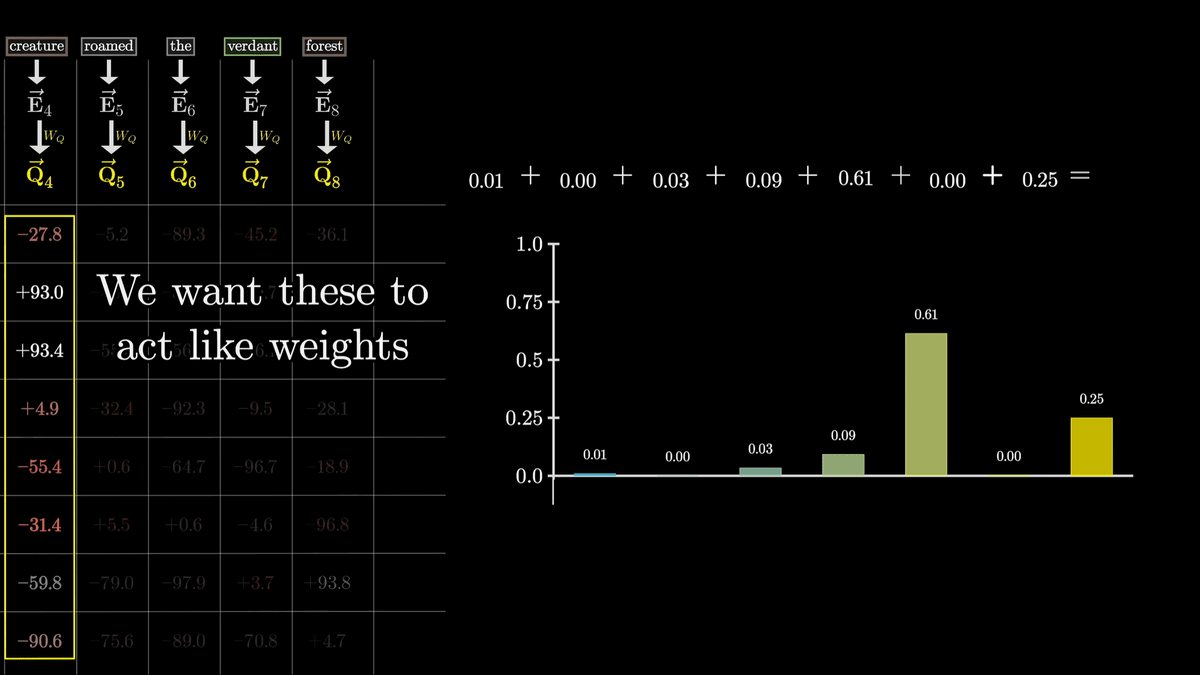
そこで、softmax関数を使用して正規化します。
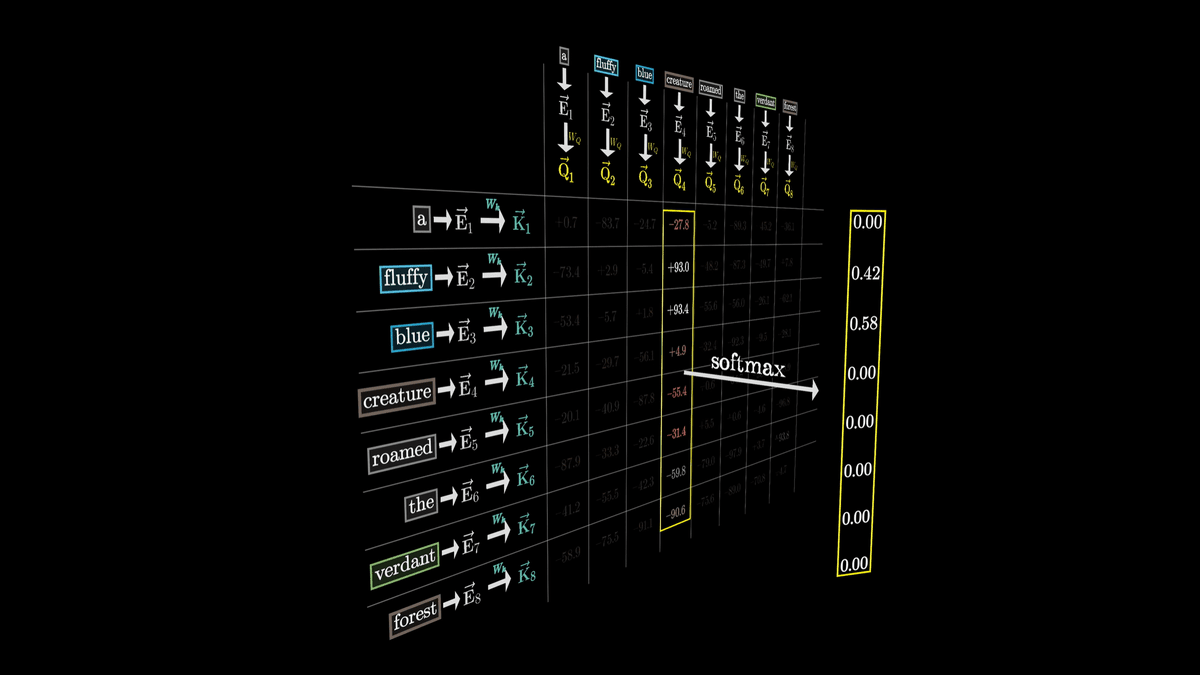
正規化後は下図のような数値になりました。
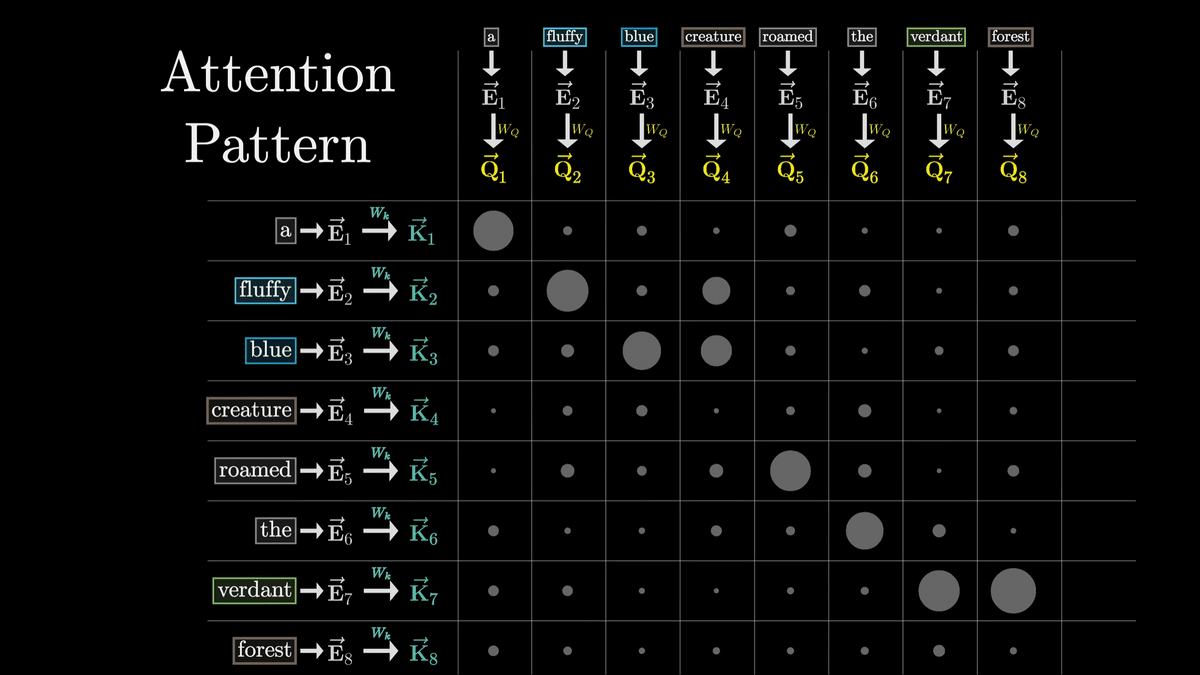
このグリッドのことを「Attention Pattern」と言います。
Attentionの論文である「Attention Is All You Need」ではこの一連の計算を下図の一行で記述しています。

QとKは上述したQベクトルとKベクトルの配列を示しています。
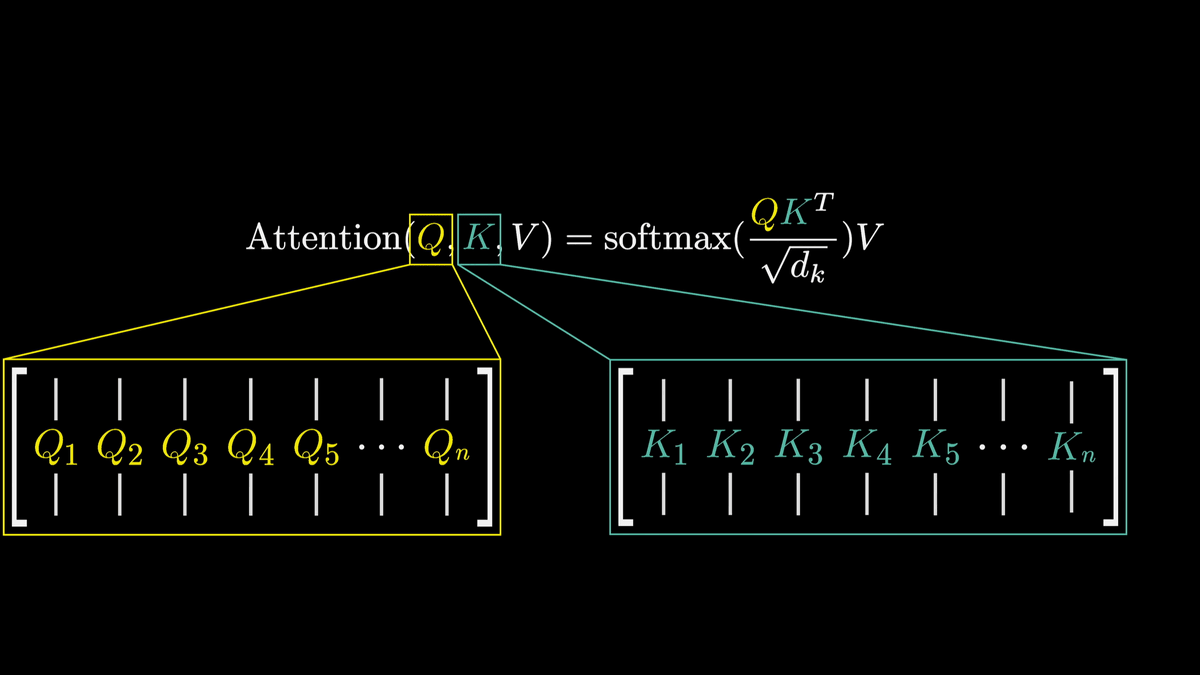
従って、「QK^T」はそれぞれのQベクトルとKベクトルのドット積を取ったものというわけです。

また、数値的に安定させるためにそれぞれの計算結果を次元数の平方根で割っているとのこと。
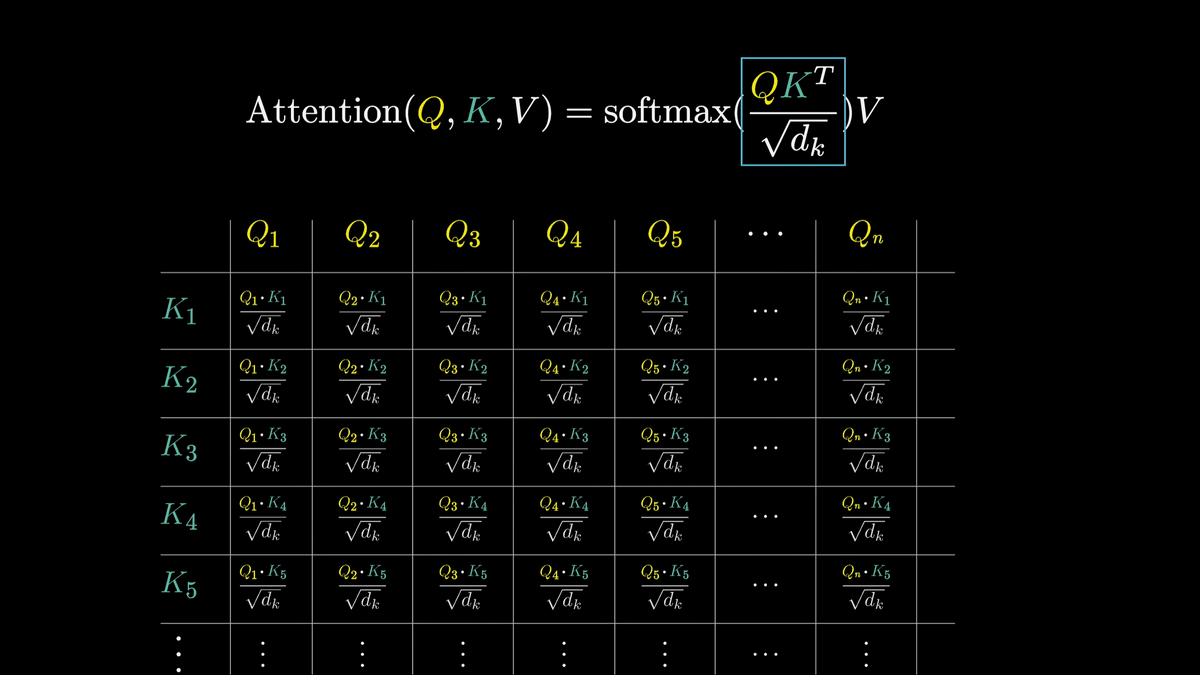
そしてsoftmaxを適用して正規化を行います。

元の解説ムービーでは、最後の「V」が一体何であるのかについてや、アテンションの性能を向上させるさまざまな取り組み、マルチヘッドアテンションなどについても解説されています。

そのほか、3Blue1BrownではTransformerのアテンション以外の解説が行われているムービーなども公開されているので、気になる人は確認してみてください。
・関連記事
AIの仕組みや開発手法についてイラスト付きで分かりやすく解説するAmazonの無料教材「MLU-Explain」 - GIGAZINE
ジェネレーティブAIの進歩に大きな影響を与えた「Transformer」を開発した研究者らはなぜGoogleを去ったのか? - GIGAZINE
ChatGPTなどの大規模言語モデルはどんな理論で成立したのか?重要論文24個まとめ - GIGAZINE
ChatGPTのような高性能言語モデルを生み出した技術はどんな仕組みなのか?をAI企業のエンジニアが多数の図解でゼロから解説 - GIGAZINE
ChatGPTにも使われる機械学習モデル「Transformer」が自然な文章を生成する仕組みとは? - GIGAZINE
・関連コンテンツ