OpenAI has released a voice transcription model and text-to-speech model that also supports Japanese, and a demo that allows you to try out the reading model for free has also been released, so I tried using it
OpenAI released the AI models 'gpt-4o-transcribe' and 'gpt-4o-mini-transcribe' that can transcribe voice, and at the same time released the voice generation model 'gpt-4o-mini-tts' that reads text aloud. A demo is available for free to try gpt-4o-mini-tts, so I tried it.
Introducing next-generation audio models in the API | OpenAI
https://openai.com/index/introducing-our-next-generation-audio-models/
OpenAI.fm
https://www.openai.fm/
The 'gpt-4o-transcribe' and 'gpt-4o-mini-transcribe' models, which convert speech to text, are based on GPT-4o and GPT-4o-mini, respectively, and have succeeded in raising recognition accuracy to state-of-the-art levels by utilizing reinforcement learning as well as pre-training using a dataset during training. Compared to comparable models, they are said to be particularly strong in complex speech recognition scenarios.
In addition, the voice generation model 'gpt-4o-mini-tts' released at the same time allows you to instruct the model 'what kind of atmosphere to generate.' For example, you can instruct it to be 'dramatic' or 'medieval knight-like.'
OpenAI has prepared a demo site called ' OpenAI.fm ' that allows you to easily test the capabilities of 'gpt-4o-mini-tts'. When you access the site, it looks like this. Click 'PLAY' at the bottom to generate audio.
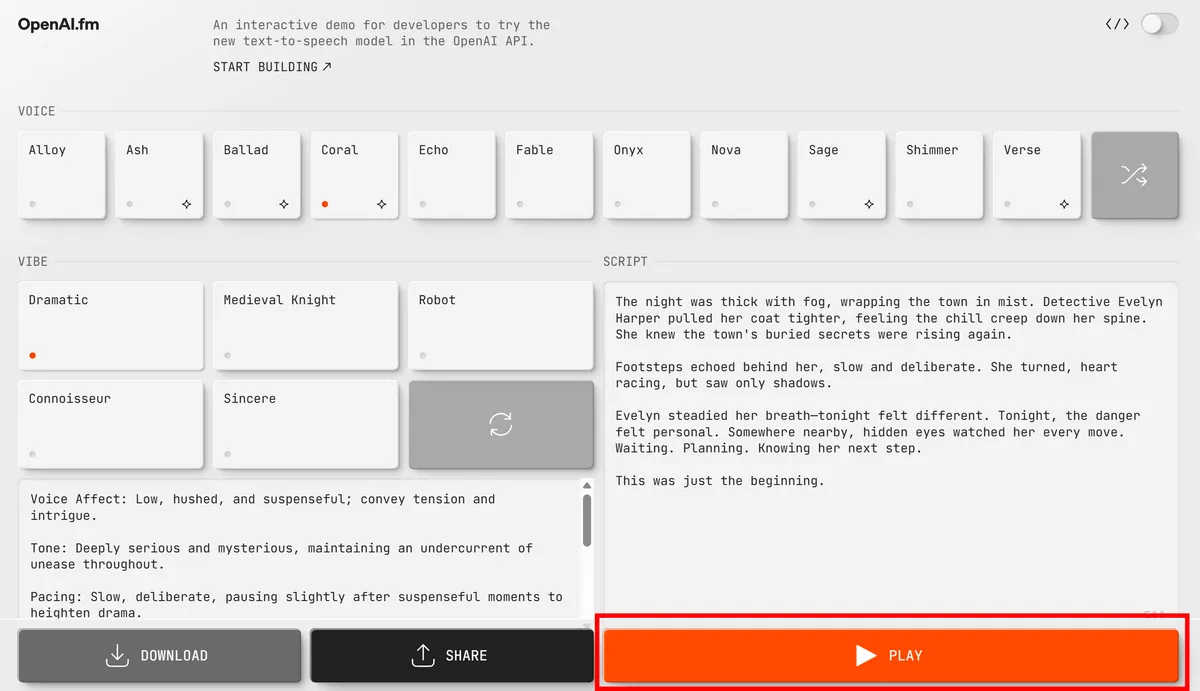
The initial settings when accessing the app were 'Coral' for the voice and 'Dramatic' for the atmosphere. When generated with these settings, the following voice was generated.
Change the voice to 'Ash' and try playing it again.
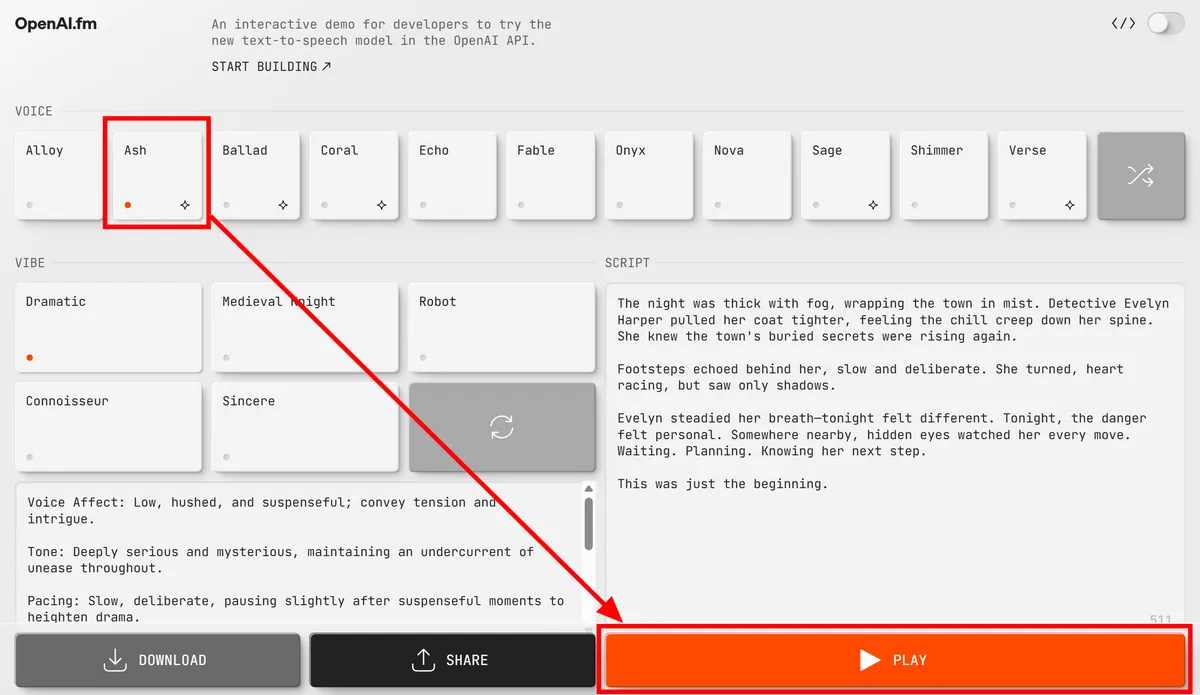
Previously, a female voice was generated, but this time a male voice was generated.
You can also change the prompt. Let's try entering a part of this article.
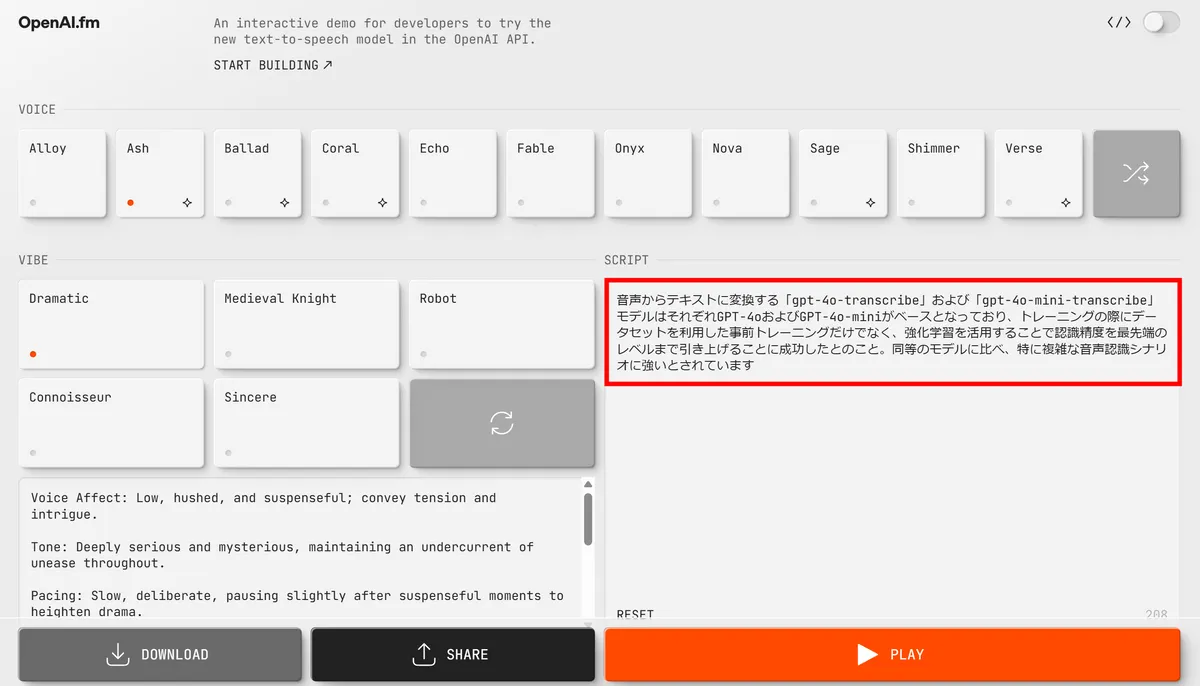
It was a mixture of English and Japanese, but he read it out accurately.
Setting the mood to 'Robot' will change the mood prompt.
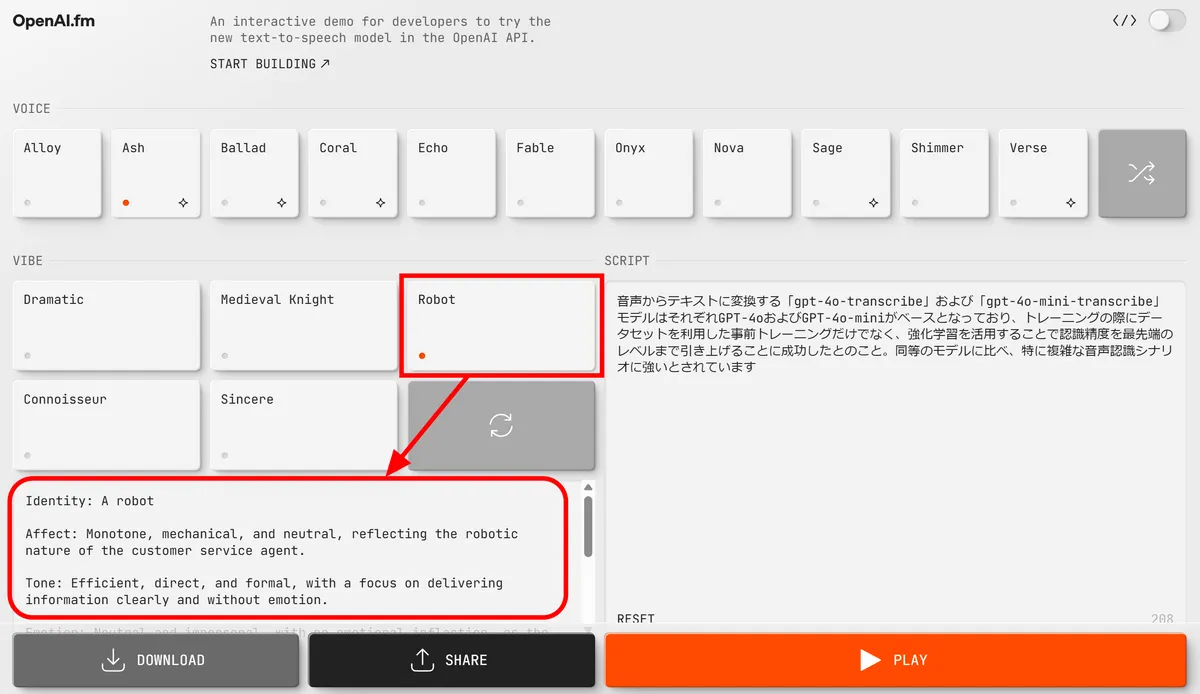
He read it without much intonation. For some reason, his English pronunciation sounded like a native speaker.
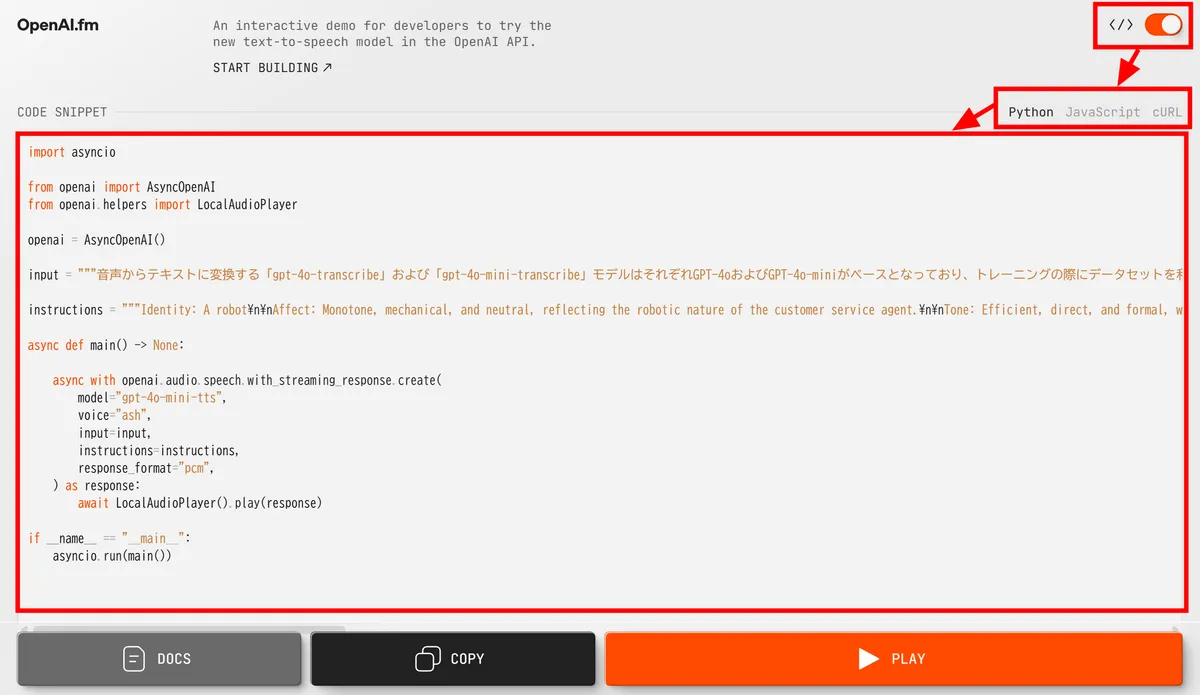
Switching the slider in the upper right corner will display the code for using the OpenAI API in Python, JavaScript, and cURL. If you want to use gpt-4o-mini-tts via the API, it seems easy to copy and paste this code and edit the script and atmosphere.
All three models released this time are charged by the number of tokens, but
the OpenAI documentation
lists the approximate charges per hour of audio. At the time of writing, gpt-4o-mini-tts was about $0.015 (2.24 yen) per minute of generated audio, gpt-4o-transcribe was about $0.006 (0.89 yen) per minute of processed audio, and gpt-4o-mini-transcribe was about $0.003 (0.45 yen) per minute of processed audio.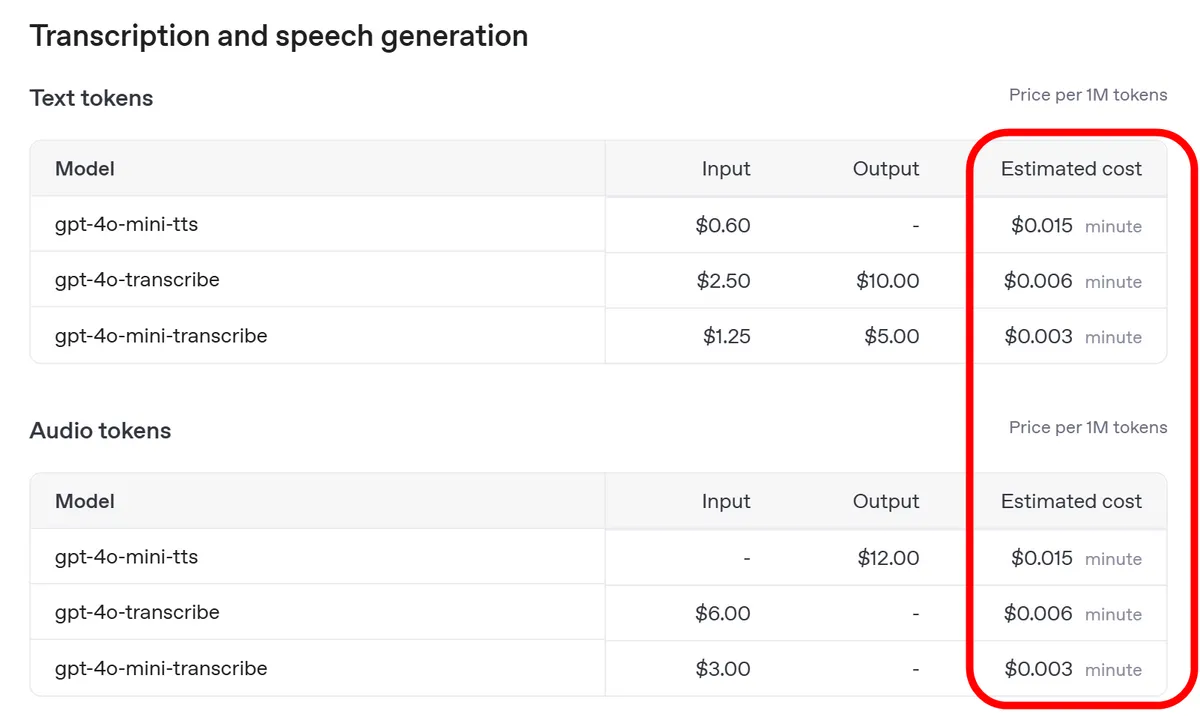
Related Posts:





in AI, Software, Review, Web Application, Posted by log1d_ts