The latest information on Google's translation AI ``Universal Speech Model (USM)'' trained in more than 300 languages is released, planning to enable translation of more than 1000 languages in the future

Machine learning has dramatically improved the performance of translation software, but some languages on earth have few speakers and lack the data necessary for learning. Google has newly trained the large-scale language model `` Universal Speech Model (USM) '' used for YouTube subtitle generation in more than 300 languages, and has excellent performance in translation tasks including relatively minor languages. reported that it worked.
Universal Speech Model
Universal Speech Model (USM): State-of-the-art speech AI for 100+ languages – Google AI Blog
https://ai.googleblog.com/2023/03/universal-speech-model-usm-state-of-art.html
Google's one step closer to building its 1,000-language AI model - The Verge
https://www.theverge.com/2023/3/6/23627788/google-1000-language-ai-universal-speech-model
In November 2022, Google announced the ambitious `` 1000 Languages Initiative '' to build an AI model that supports 1000 languages. A challenge in this effort is how to support languages with few speakers and few datasets available for machine learning training.
Traditional supervised learning requires the time and cost of manually labeling datasets or collecting existing transcription data. However, it is difficult to collect high-quality data in languages with relatively few speakers, and it lacks scalability.
Therefore, Google reported that it trained USM, which is used to generate closed captions (subtitles that users can switch between displaying and hiding) on YouTube, using a method called self-supervised learning . Self-supervised learning is a method of automatically generating pseudo-labels from unlabeled data by humans, and it is possible to use untranscribed audio-only data for training.
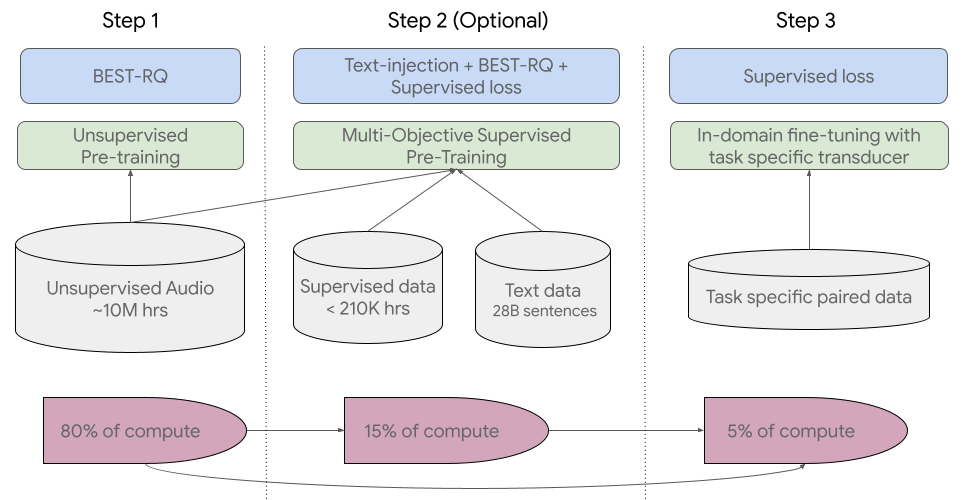
In USM, the first step, which accounts for 80% of the training, is self-supervised learning called 'BEST-RQ', and the second step, which accounts for 15%, improves the quality of the model through pre-training with additional text data. In the third step, which accounts for 10%, the model was fine-tuned by performing a downstream task (target task). Google 'pre-trained the model's encoder using a large unlabeled multilingual dataset and fine-tuned it on a smaller labeled dataset, demonstrating that it can recognize these minor languages. Furthermore, the model's learning process is also effective in adapting to new languages and data.'
Google says USM is a state-of-the-art speech recognition AI with 2 billion parameters, trained on 12 million hours of speech data and 28 billion sentences of text across more than 300 languages. In addition to widely-spoken languages such as English and Mandarin, USM is automatic in languages where training data is difficult to collect, such as Malagasy , Luo , Soga , Assamese , Santal , Balinese , Shona and Nyankole . Voice recognition is possible.
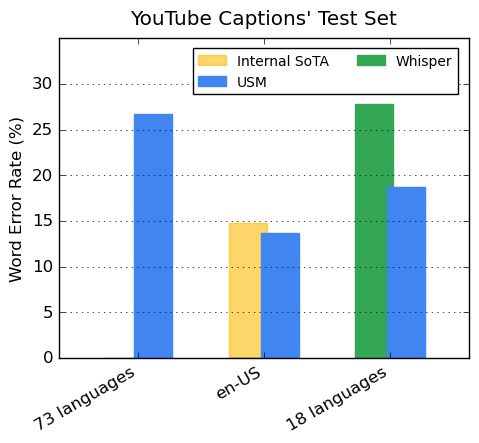
In a verification using multilingual audio data of YouTube subtitles, USM achieved a word error rate of less than 30% on average for 73 languages, and Google said, ``A milestone that has never been achieved before. It is.' In addition, in American English translation, the performance exceeded the state-of-the-art model, and in a comparison of 18 languages with a word error rate of less than 40% by OpenAI's high-performance transcription AI ' Whisper ', USM was on average and recorded a 32.7% lower word error rate.
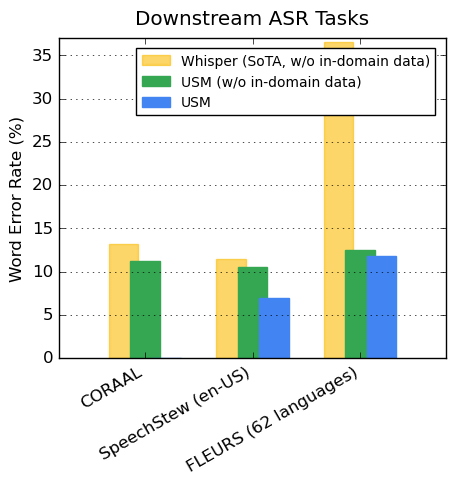
Below is a graph comparing word error rates between USM and Whisper using CORAAL , an African-American English dataset, SpeechStew , an English dataset, and FLEURS , a dataset containing 102 languages. The yellow bar indicates the word error rate for Whisper without in-domain data, the green bar for USM without in-domain data, and the blue bar for USM with in-domain data, and the blue bars indicate the word error rate for USM without in-domain data. USM records lower word error rates with and without data.
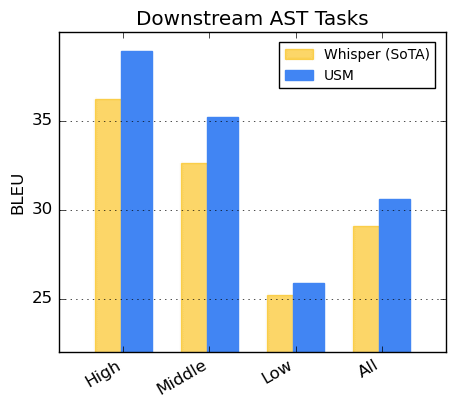
Below is a graph showing the BLEU score , which indicates the accuracy of machine translation, for each language group, classifying languages into High, Middle, and Low based on resource availability. A higher BLEU score indicates better translation accuracy, and it can be seen that USM outperforms Whisper in all groups.
Google said, 'The development of USM is an important step towards realizing Google's mission to organize the world's information and make it universally accessible. USM's base model architecture and training pipeline are: I believe that it will be the foundation that enables expansion to 1000 language-compatible speech models, ”he said, accepting requests for access to the API from researchers.
Related Posts:





in Software, Web Service, Posted by log1h_ik