Basic usage of ``Stable Diffusion web UI (AUTOMATIC 1111 version)'' that can easily use ``GFPGAN'' that can clean the face that tends to collapse with image generation AI ``Stable Diffusion''
'
This article first summarizes the basic usage of 'txt2img', which generates images from text in 'Stable Diffusion web UI (AUTOMATIC111 version)'.
◆ Contents
・ 1: The easiest way to use
2: What does each item in the 'txt2img' tab mean?
Stable Diffusion web UI (AUTOMATIC 1111 version) is one of the UIs for using the image generation AI 'Stable Diffusion'. To use Stable Diffusion, an NVIDIA GPU is required, and Stable Diffusion web UI (AUTOMATIC 1111 version) will be installed on the corresponding PC. By using the hand, it can be used in an environment without NVIDIA GPU. The installation method is detailed in the article below.
Image generation AI ``Stable Diffusion'' works even with 4 GB GPU & various functions such as learning your own pattern can be easily operated on Google Colabo or Windows Definitive edition ``Stable Diffusion web UI (AUTOMATIC 1111 version)'' installation method summary - GIGAZINE
◆1: The easiest way to use
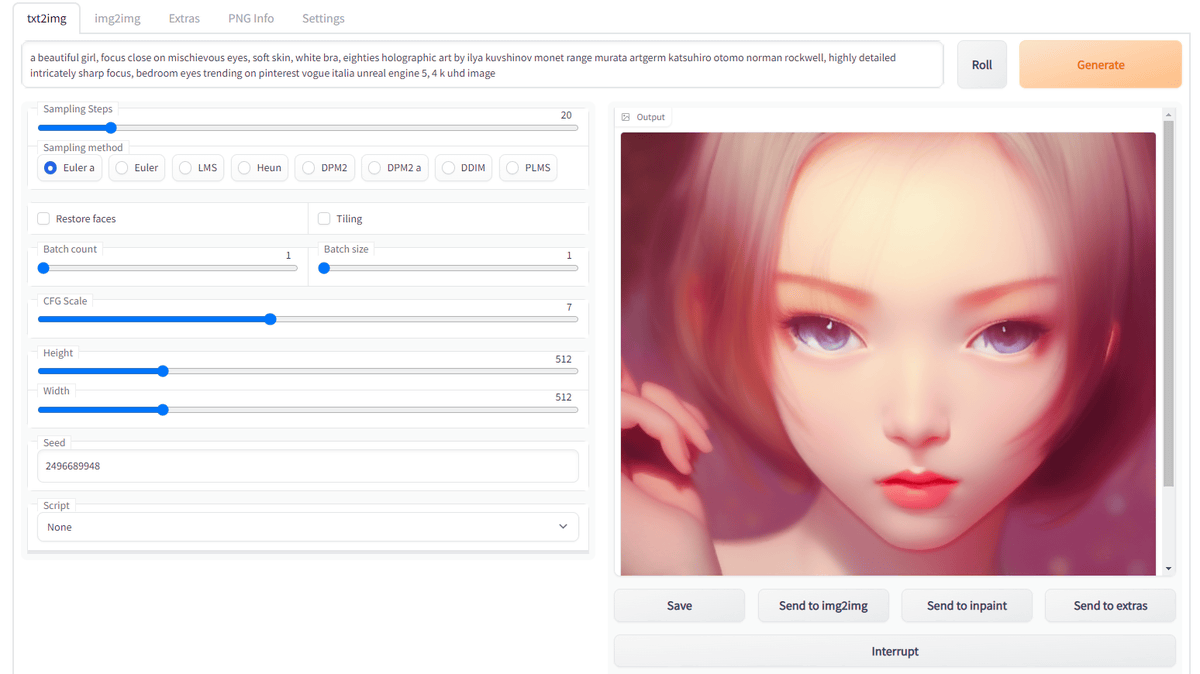
If you want to create an image for the time being, enter a character string related to the image you want to output in the 'Prompt' field and press 'Generate'.
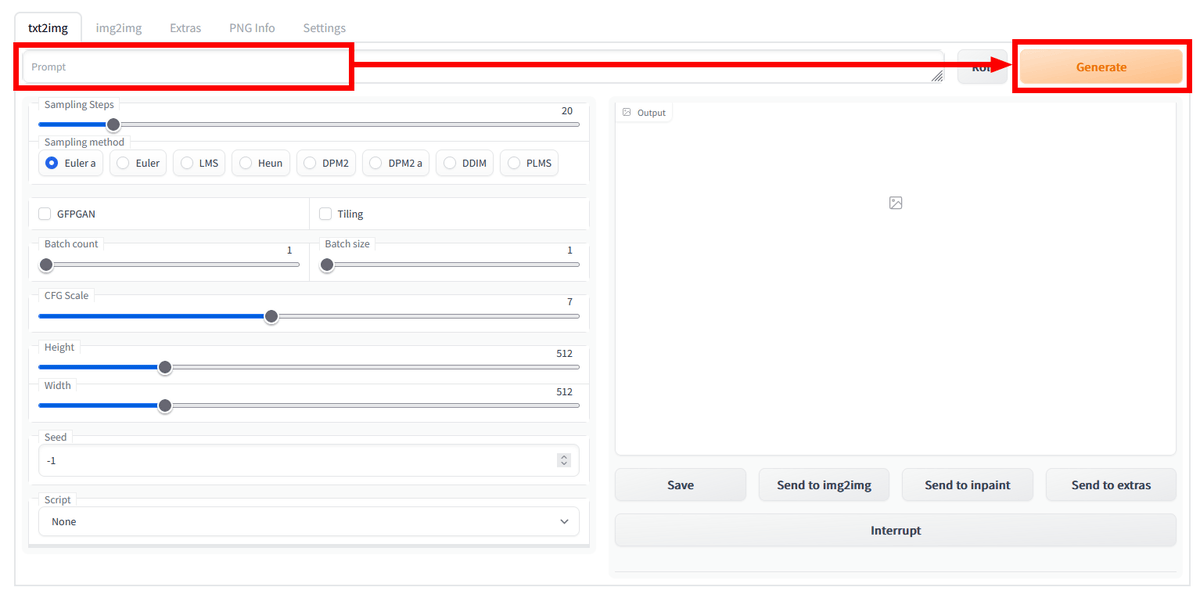
Even if 'Prompt' is empty, an image will be created for the time being, but since there is no pointer at all, the picture will be unclear.
As for what to put in 'Prompt', please refer to 'Lexica' etc. where you can see what kind of prompt the image was generated.
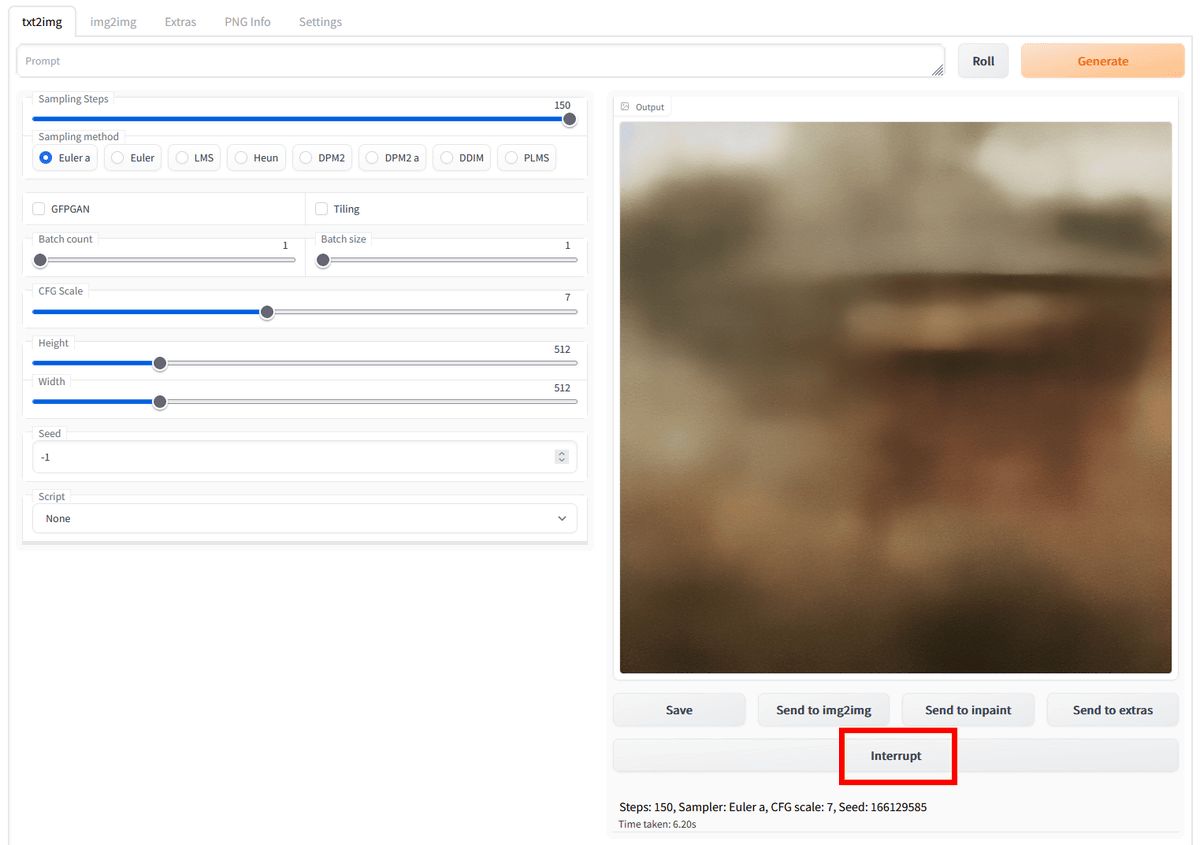
Image generation is about 3 seconds to 10 seconds once with default settings. If you want to stop in the middle of generation, press 'Interrupt'.
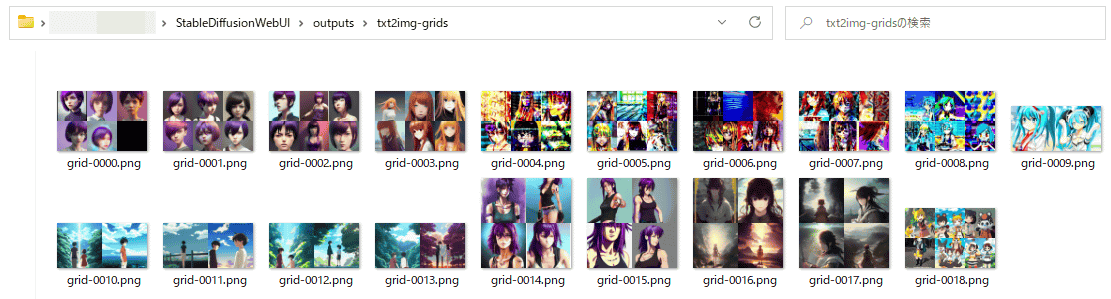
Generated images can be stored in 'txt2img-grids' and 'txt2img-images' in 'output' under the folder where 'Stable Diffusion web UI' is installed without 'Save Image As' in the browser. are stored separately.

'txt2img-grids' saves a list of images when multiple images are generated at once.
'txt2img-images' stores all the images generated in the past.
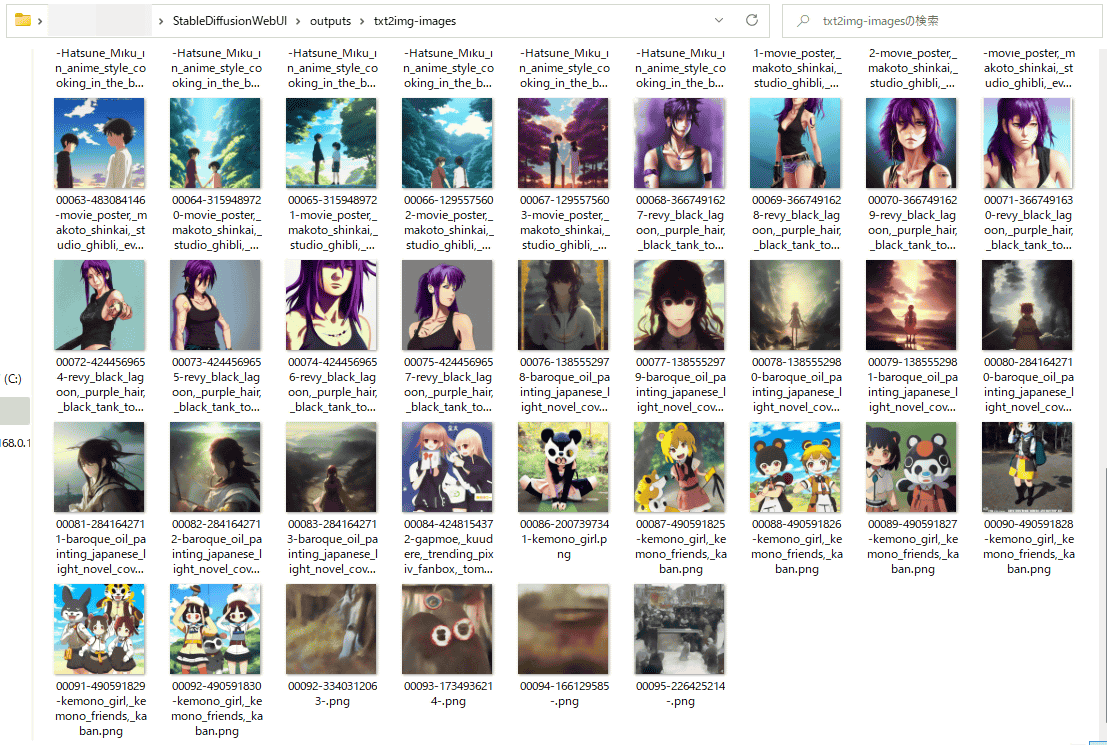
The file saved in this 'txt2img-images' has the prompt at the time of generation automatically inserted in the name, and the seed value and the settings at the time of generation are embedded as metadata, so with the same settings image can be regenerated.
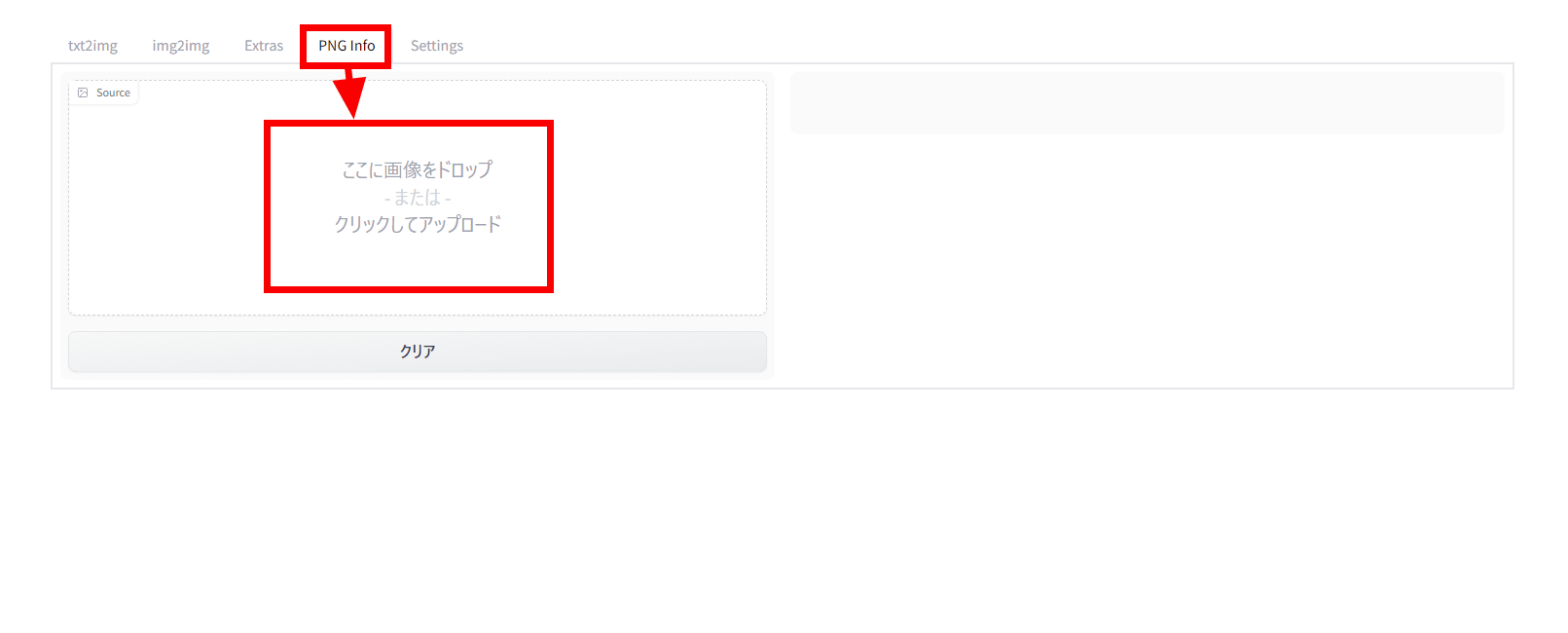
If you want to reuse the metadata embedded in the image again, open the 'PNG info' tab and drag and drop the image.
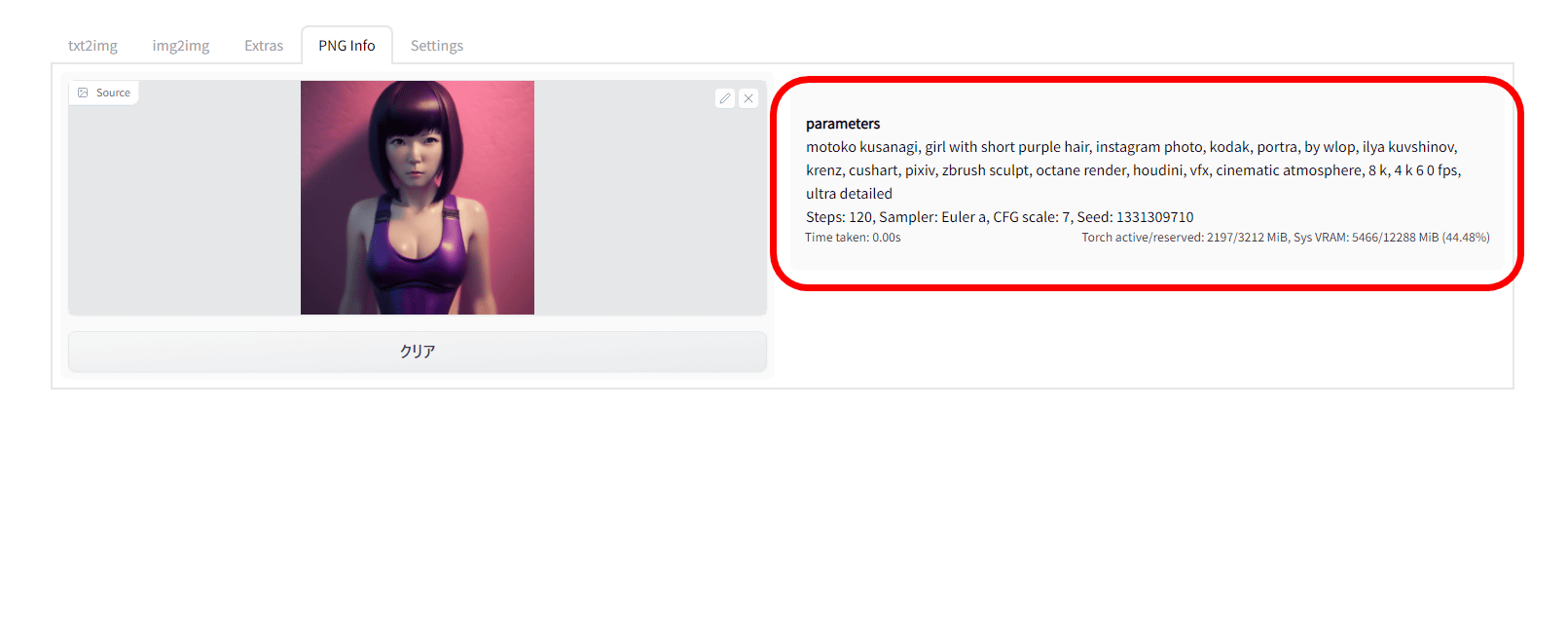
Then, on the right side of the screen, the prompts, parameters, and seed values at the time of generation are displayed.
◆ 2: What does each item in the 'txt2img' tab mean?
Each item in the Stable Diffusion web UI (AUTOMATIC 1111 version) has a pop-up help. Since there were some items that could not be translated by translating by page and could not be translated by translating by page, the information is summarized below.
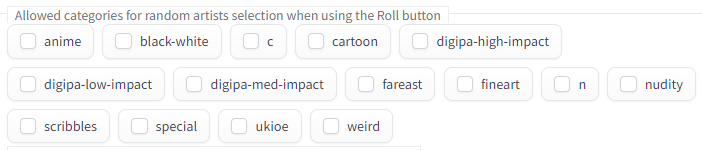
'Roll' on the right side of the 'Prompt' column adds a random artist name to the image generation prompt. One person is added each time you press the button.
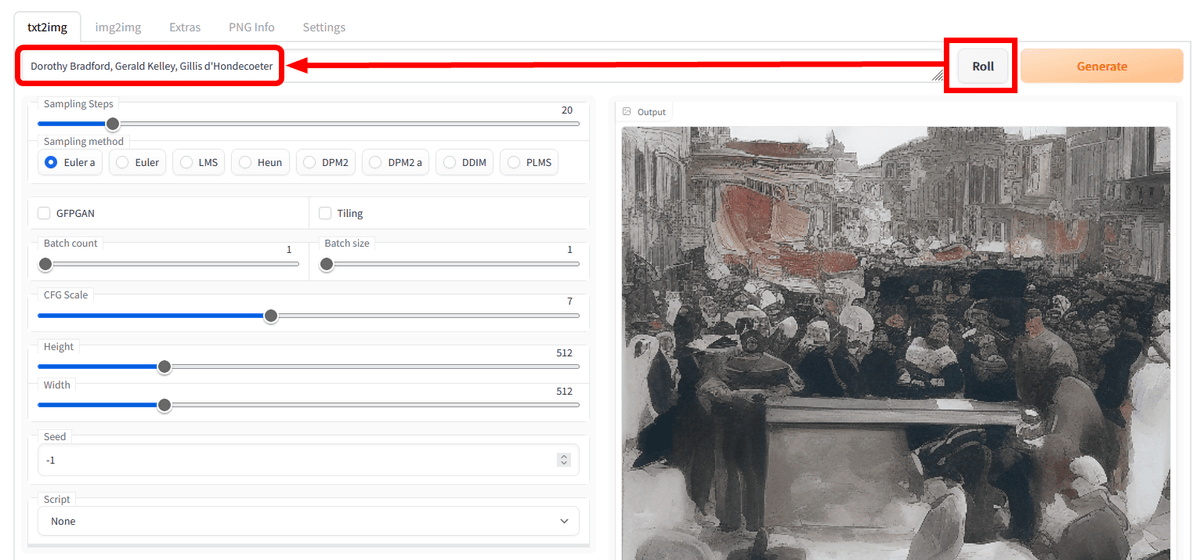
Artists can make people from specific categories appear by checking the category list at the bottom of the 'Setting' tab. For example, for “amime”, names such as Katsuhiro Otomo, Satoshi Kon, and Posuka Demizu appeared. However, names such as the ukiyo-e artist Gatoken Shunshiba and the Western-style painter Fujishima Takeji also appear, so it seems that it is not necessarily limited to anime and manga. There are also mysterious categories such as 'c' and 'n'.
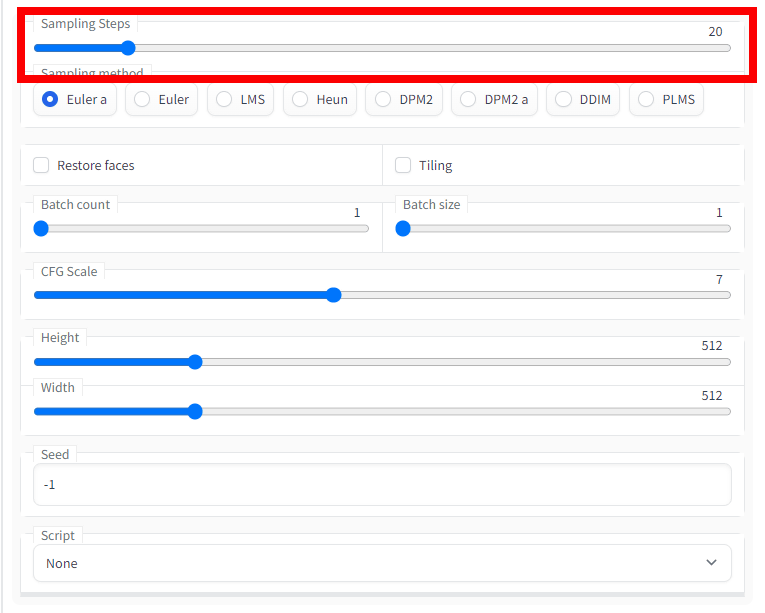
The following is the part to be adjusted before image generation on the left side of the Stable Diffusion web UI (AUTOMATIC1111 version) screen.
'Sampling Steps' means how many times to perform the feedback process for image generation. The more you increase the number, the more detailed the picture will be, but of course, the more you increase, the more time it will take. Also, it is difficult to say that increasing the number does not make it a good picture. The default setting of 20 will give you a decent finish, but if you want to increase it, the guideline is up to about 110.
'Sampling method' allows you to choose what kind of algorithm to adopt in the feedback process. Basically, 'Euler a' is OK.
'Restore faces' and 'Tiling' are also one of the features of this AUTOMATIC1111 version. 'Restore faces' uses
There is an image comparing how much correction can be done in the official repository. The left end is the original photo, the middle four are other algorithms, and the right end is GFPGAN.

Stable Diffusion performs image generation in 'batches'. 'Batch count' is how many batches are performed, and 'Batch size' is how many images are generated in one batch. If there are many images generated at one time, the amount of VRAM used will increase, so errors are more likely to occur in an environment with less VRAM. Therefore, in an environment with less VRAM, specify the number you want to generate in 'Batch count' and set 'Batch size' to 1 to generate images stably without errors.
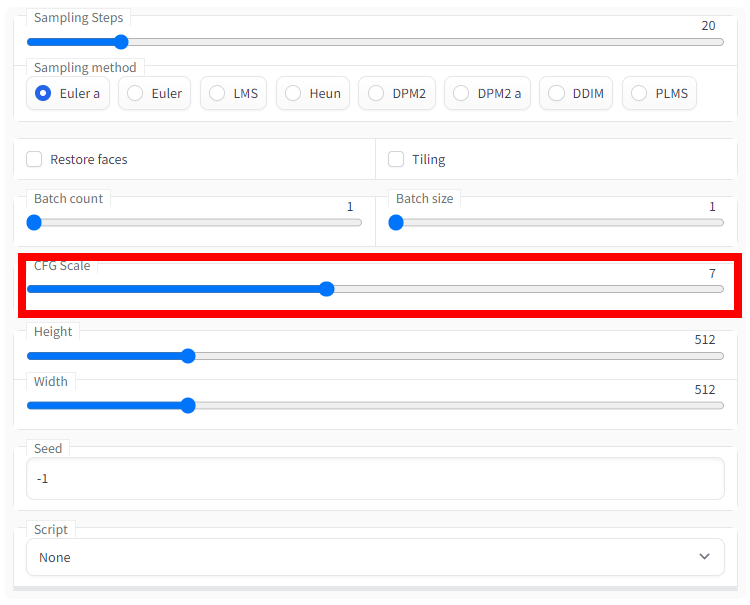
'CFG Scale' is the same as other Stable Diffusion frontends, and it is a value that indicates how much you follow the prompt instructions. Become. 7 to 11 is generally considered good.
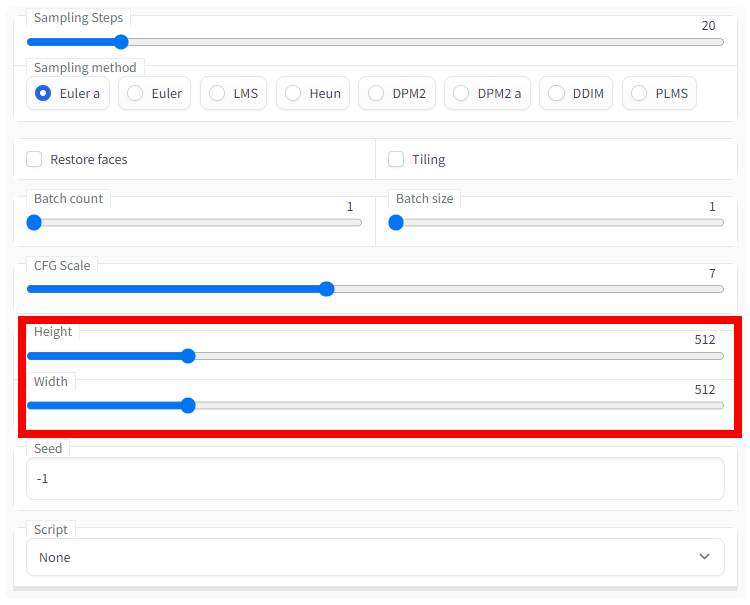
'Height' and 'Width' are the size of the output image. Since the model was optimized for 512x512 in the first place, 512x512 produces the highest quality images. In addition, since the image area is directly reflected in the amount of VRAM used, if you want to create a slightly vertically long image of 512 x 832, if the VRAM is small, an error may occur and the image may not be generated.
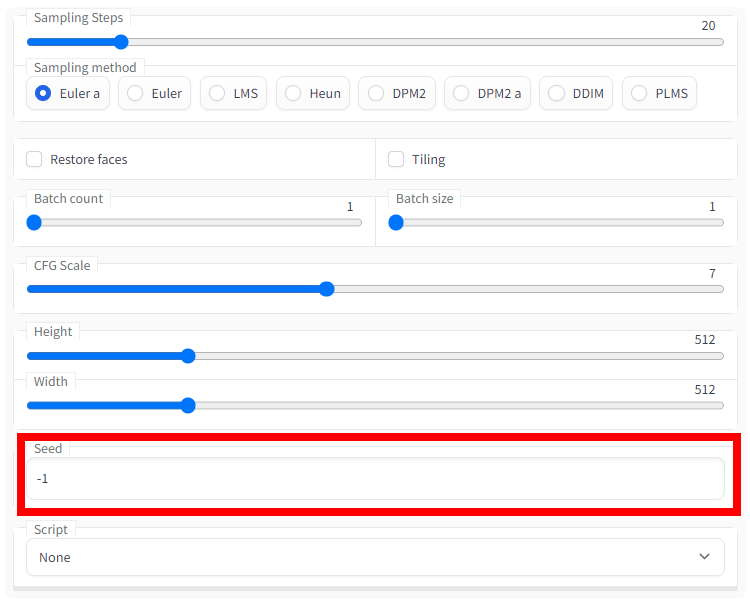
'Seed' is the seed value. If it is '-1', it will be randomly generated every time. If you want to reproduce the composition of that image because it was done well, you can enter the seed value of the image in question to generate an image with a different pattern while maintaining the same composition and atmosphere.
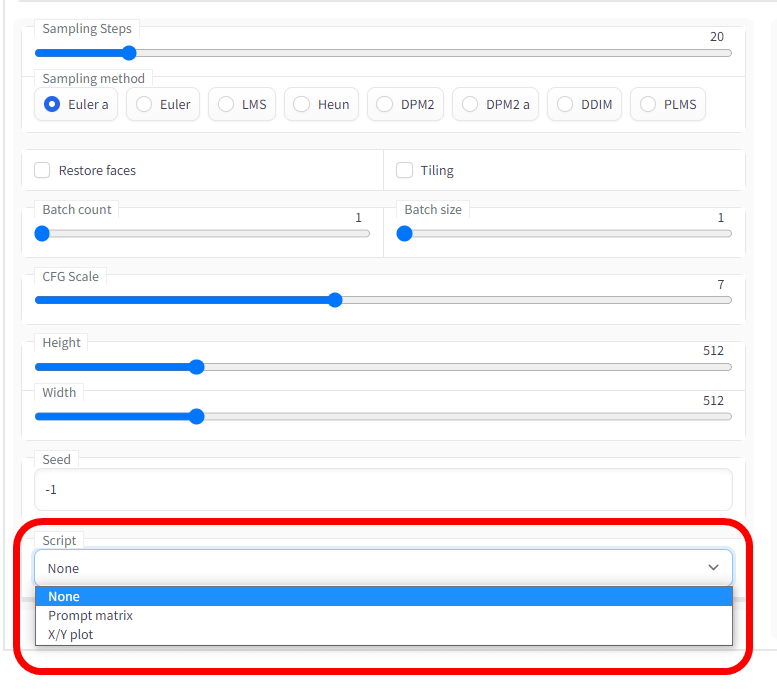
'Script' can use scripts. The default is 'None'. This will be published separately.
At the bottom of the generated image, multiple buttons for handling images are displayed. If it is 'Save', the generated images are collectively saved together with the CSV file in 'log/images'. Select one of the generated images and press 'Send to img2img' to send it to the 'img2img' tab. Similarly, 'Send to inpaint' will be sent to the inpainting function of the 'img2img' tab, so you can mask part of the image. 'Send to extras' will send it to the 'Extras' tab.

We'll take a closer look at the script part in the next article.
・Continued
How to use ``Prompt matrix'' and ``X/Y plot'' in ``Stable Diffusion web UI (AUTOMATIC 1111 version)'' that you can see at a glance what kind of difference you get by changing prompts and parameters in image generation AI ``Stable Diffusion'' Summary-GIGAZINE

Related Posts:


in Review, Software, Web Application, Posted by logc_nt