An overseas engineer seriously explains the Japanese 'garbled characters', and a Japanese enthusiast who is as good as a Japanese person will be shown.
by Whooym
A Field Guide to Japanese Mojibake
https://www.dampfkraft.com/mojibake-field-guide.html
According to Mr. McCann, garbled characters occur by opening a document with a different character code than when it was created. If the text is garbled, it will be a meaningless character string, so it can not be read, but different patterns will appear depending on what kind of character code was used, so when you get used to it, guess the type of character code used. It seems that you can do it.
◆ UTF-8
UTF-8 is the most common character code on the Internet and has become popular in Japan in recent years. If you open the sample text created in UTF-8 in Shift JIS, it will be as follows.
First, let's take the following as a sample sentence.
I am a cat. there is no name yet.
If you make a mistake in the encoding settings, the characters will be garbled.
The height of Tokyo Tower is 333m.
And the above is encoded in UTF-8, then opened in Shift JIS and garbled.

Regarding this garbled character, Mr. McCann said, 'I can see that certain characters appear frequently, but there is an interesting
In the image below, the edge of the tatami mat on which Yoshimitsu Ashikaga sits is the 'Shoen '. 'This used to mean a high rank, but today you can see it in the Hina dolls used in the Hinamatsuri,' explains McCann.
In addition, Mr. McCann found
After seeing a lot of mojibake over the years I realized that different encoding pairs have different visual textures because of the particular kinds of garbage that come out. This scene from Urasekai Picnic has UTF8 rendered as SJIS, a very common combination. Pic.twitter. com / 798nEE8G1I
— Paul O'Leary McCann (@ polm23) October 31, 2021
◆ Shift JIS
Shift JIS is the character code that was most commonly used on Japanese sites before. Most of the sites in recent years have been replaced by UTF-8, but it is said that Shift JIS is used for old feature phones, so-called 'garakei' emails.
If you open the above sample sentence created in Shift JIS in UTF-8, it will be as follows.
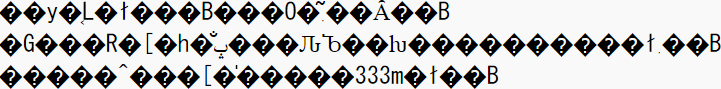
Mr. McCann said, 'It is a rare pattern of general characters that is often seen in garbled sentences in Shift JIS. Especially noticeable is the variant character' taka 'of' high ', which connects the lines. It is called 'Hashigodaka' and is often used for surnames. 'Tatsusaki', in which 'Large' in 'Saki' is changed to 'Standing', is a similar case, but in 'Taka'. It seems that there are few compared to that. '
◆ EUC-JP
When EUC-JP is displayed in UTF-8 mentioned above, it looks like this.

Even if I open it with Shift JIS, it is not displayed well.

Mr. McCann said, 'The interesting thing about the garbled characters that open EUC-JP in Shift JIS is that half-width Katakana often appears. This is because Shift JIS represents half-width Katakana in 1 byte.' I am commenting.
◆ ISO-2022-JP
If you open the sample text created in ISO-2022-JP in UTF-8 / Shift JIS / EUC-JP, the character code will be as follows.
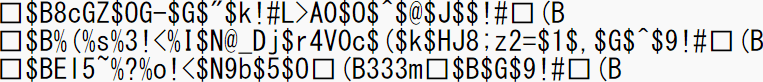
According to Mr. McCann, the garbled characters when opening ISO-2022-JP characters in UTF-8, Shift JIS, and EUC-JP are the same because there are no characters that can be interpreted as escapes in other character codes. That is.
Related Posts:








in Note, Posted by log1l_ks