Researchers from overseas are also paying attention to the activation of `` Attempts to change Japanese kanji characters to type with AI ''

by
The process of converting ' Kushikushi ' used in Japanese classics and ancient documents into modern Japanese characters is called ' reprinting '. Many modern Japanese people cannot read koji characters, so conversion is not possible for anyone. Attracting attention is the attempt to reprint using machine learning. Alex Lamb , a machine learning researcher at the University of Montreal Ph.D., summarizes the circumstances surrounding the typographical character.
How Machine Learning Can Help Unlock the World of Ancient Japan
https://thegradient.pub/machine-learning-ancient-japan/
The vast amount of books and documents left by people in the past are very important materials for considering history and culture. However, language and notation change over time, and many old documents are incomprehensible to some experts. For example, the clay plates used to write letters around ancient Mesopotamia are mainly engraved with cuneiform letters, but only some specially trained researchers can decipher them. .
Mr. Lam points out that the same thing is happening in Japanese kanji characters. Kuzushi characters have been used from the 9th century until around the Meiji era, but they are not included in the modern curriculum, and the overwhelming majority of Japanese cannot read them. On the other hand, the volume of books written in kanji characters is enormous, and when including letters and personal diaries, it is estimated that there are actually over 1 billion pages of text.
Since few people understand kanji characters, it takes a very long time and a lot of money to read and understand the vast amount of information written in kanji characters. Considering the importance of Koji characters in Japanese culture, it is important to use a computer to recognize Koji characters.
by
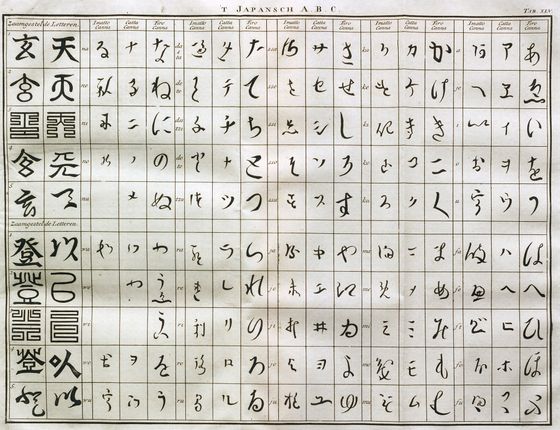
The development of the AI for recognizing Kanji characters using machine learning has been sought for a long time, but due to the lack of a high quality Kanji character database, it was difficult to achieve high performance. Therefore, the National Literature Research Museum has created a comb-shaped data set that has been carefully selected by the Humanities Open Data Joint Usage Center and released it in November 2016 . The dataset has been updated, and as of November 11, 2019, 4328 character types and over 1 million character images are available.
The provision of a comprehensive high-quality data set greatly contributed to the development of AI for character recognition. Nonetheless, Mr. Lam pointed out that it is difficult for computers to recognize junk characters. “Some characters are described in a context-dependent manner.” “Because there are more than 4000 types of characters, there are many characters that appear only once or once in the data set.” In modern times, even a single hiragana character has multiple character types depending on the variant kana .

'Kojikushi text is sometimes written with illustrations and backgrounds, and it may be difficult to distinguish text from illustrations.' 'In personal letters and phrases, a notation that does not unify the size of lines and characters, such as

Meanwhile, Lamb Mr. Tarin Clanuwat Mr. and is a researcher of the Humanities open data joint-use center
KuroNet seems to be able to change the whole to a typographical speed at a speed of 1.2 seconds per page, especially in the letterpress printing books of the 17th to 19th centuries. However, there seems to be a big difference in performance between books, and the results were particularly low in dictionaries with many special characters and cookbooks with many illustrations and special layouts.
With KuroNet, it is possible to change each of the kanji characters into modern type as follows. However, at the time of writing the article, it is only necessary to change the kanji to modern type, and it is necessary for humans to translate it into modern language.

KuroNet achieved cutting-edge results at the time of its development, but in order to further stimulate the field of AI development that makes typographical characters a typo , Kaggle's platform “ A competition was held to compete how accurately they can be recognized. Finally, 293 teams participated in the competition, and some teams achieved 95% accuracy. As a result of investigating KuroNet with the same settings, the accuracy was 90%, ranking 12th overall, so many AIs with higher accuracy than KuroNet were developed.
From the results, Mr Lam said, he learned some important lessons, such as confirming that some of the existing object detection algorithms still work well in comb character recognition.
AI tries to decipher “Kushishi” | NHK News
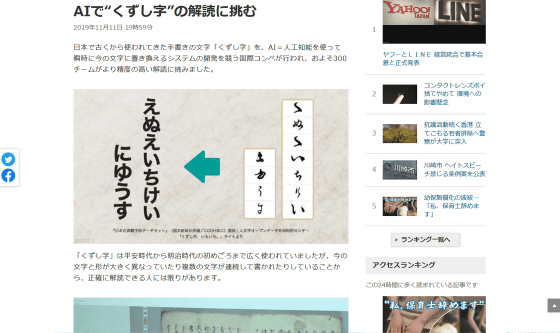
Dr. Lam pointed out that the creation of a data set made by the Humanities Open Data Joint Usage Center has made great progress in the development of AI that turns trash characters, but there are still many unresolved issues. For example, most of the training data is selected from books from the 17th to 19th centuries, but the history of the kanji is much longer, with some handwritten documents and some printed. In addition, very rare styles are often used for some styles such as the titles of books, and there are cases where the shape of the sculptures carved into the stone may be different.
An even more attractive unresolved issue is the development of AI that translates printed text into modern languages. Even if the kanji characters are in the state of ancient sentences, it is certain that modern humans will greatly improve the readability, but there are still significant differences in words and grammar. If AI can be translated as well as deciphered, it will be a major advance in classical studies. Lam argued that in order to solve these problems, interdisciplinary efforts were needed in which researchers studying historical documents and machine learning researchers combined their knowledge.
Related Posts:








in Software, Posted by log1h_ik