Develops technology that enables Samsung to create realistic conversational animation from a single photo or picture

Technicians at Samsung's Artificial Intelligence (AI) Center in Moscow and the Skorkovo Science and Technology Institute in Russia can generate animations of human talking from images without using techniques like traditional 3D modeling I developed a model. This technology is expected to be applied to digital avatars used in games and video conferencing in the future.
[1905.08233v1] Few-Shot Adversalial Learning of Realistic Neural Talking Head Models
Samsung's AI animations paintings and photos without 3D modeling | VentureBeat
https://venturebeat.com/2019/05/22/samsungs-ai-animates-paintings-and-photos-without-3d-modeling/
You can see what the technology is in one shot by watching the following movie.
Adversal Learning of Realistic Neural Talking Head Models-YouTube
The model developed by Samsung that can generate animations of people talking from images is training on the basis of several images to generate a completely new image of human conversation. Can do For example, in the following case, when 8 images (upper) are trained in the model and a movie (Driving Sequence) that is the source of the conversational video is input, only the eyebrows, eyes, nose, mouth and chin lines are composed from the original movie The extracted frames are extracted, and the motion of the frames is adjusted to the learned image to generate 'an entirely new conversational video'.
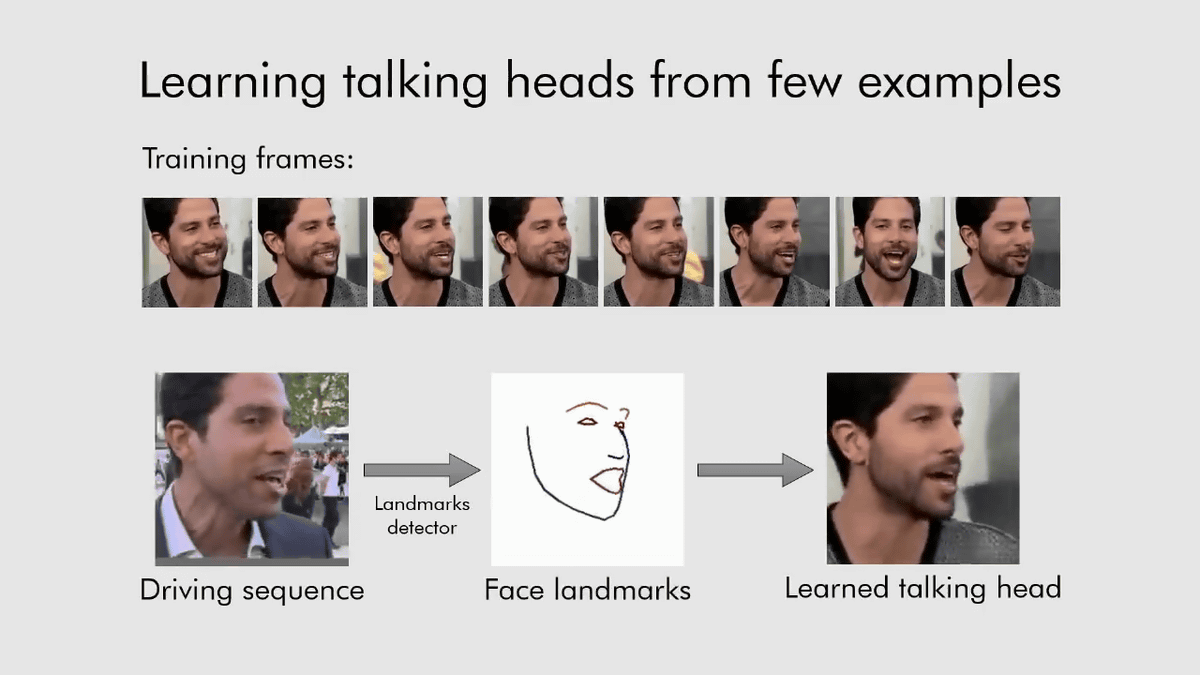
The conventional model requires a large amount of image data for training, but the model developed by Samsung and Skolkovo Science and Technology Institute can generate animations from just one photo.
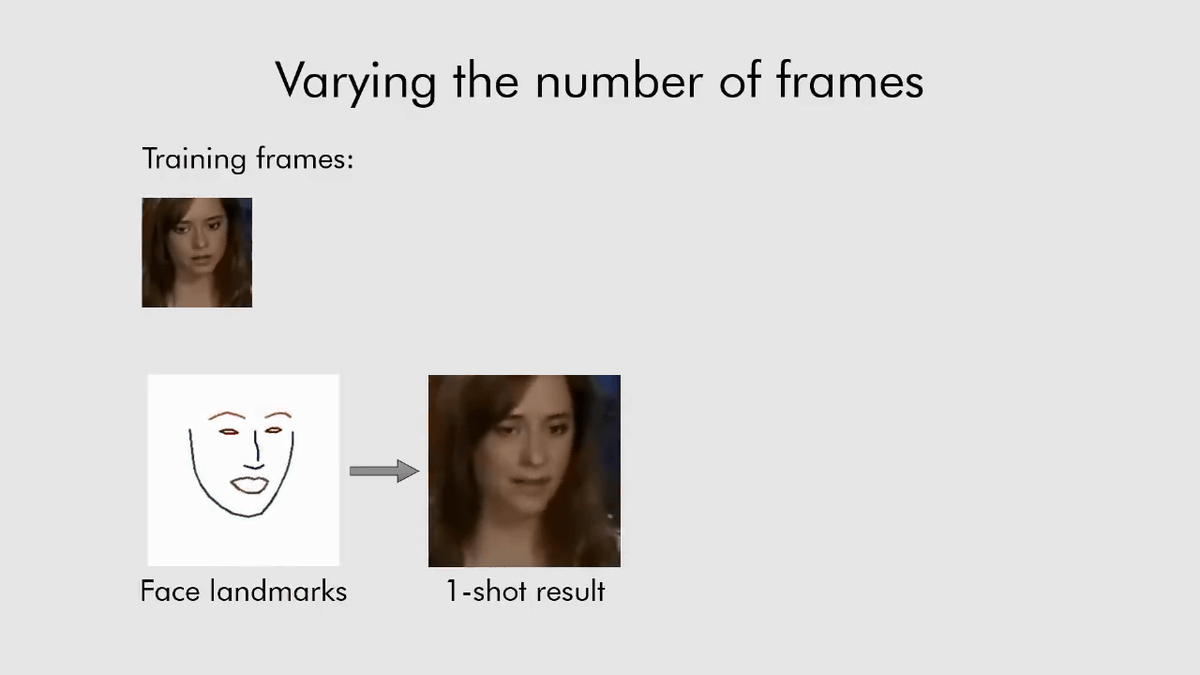
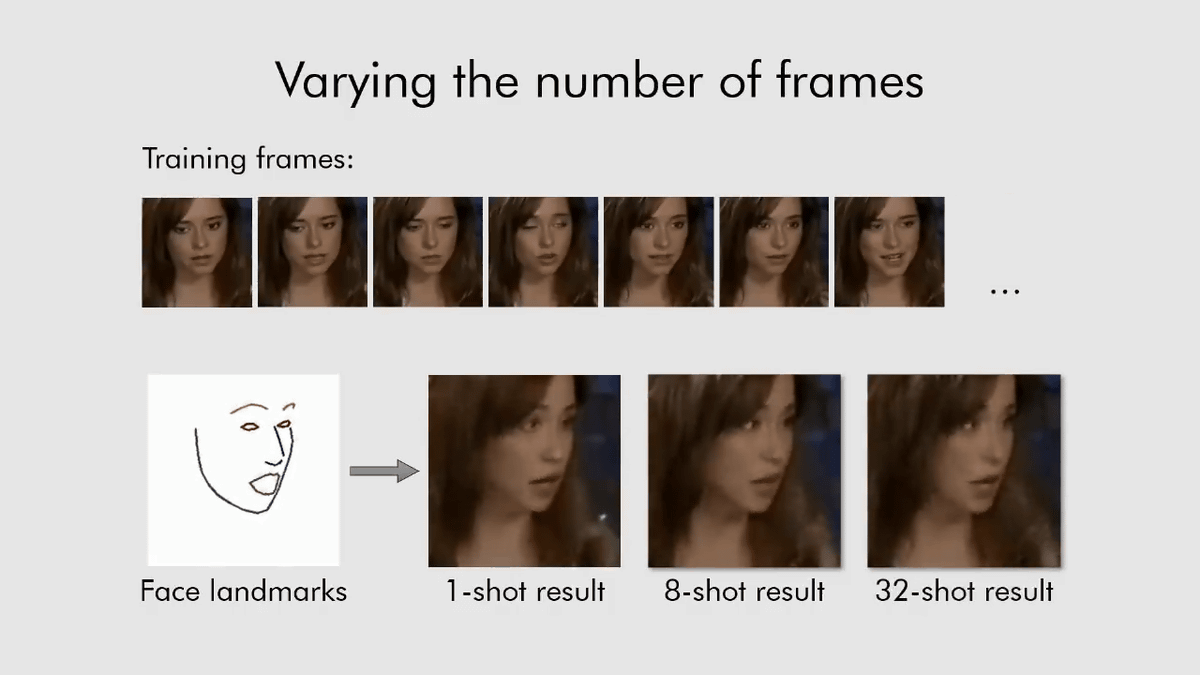
Of course, the more the training data is increased to 8, 32 and so on, the motion of the animation becomes finer, but when you look at the movie, there is no big difference in the motion, and even a natural conversation animation from one You can see that you can generate
In the meta-learning stage, we train three neural networks, “embedded network,” “generated network,” and “discrimination network” based on large video data sets.
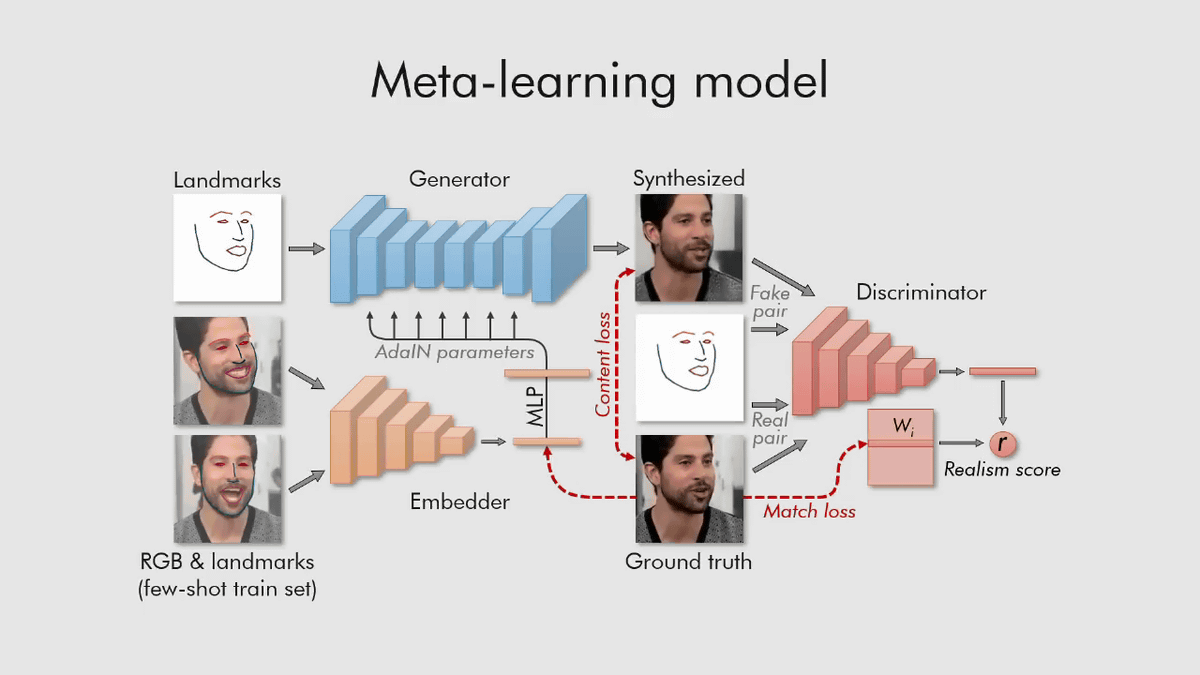
And in the small shot learning, by initializing the parameters of the generation network and the discrimination network in a unique way, the tens of millions of parameters are adjusted based on only a few images or a single image, and speedy enemyization is achieved. That they can do basic training.
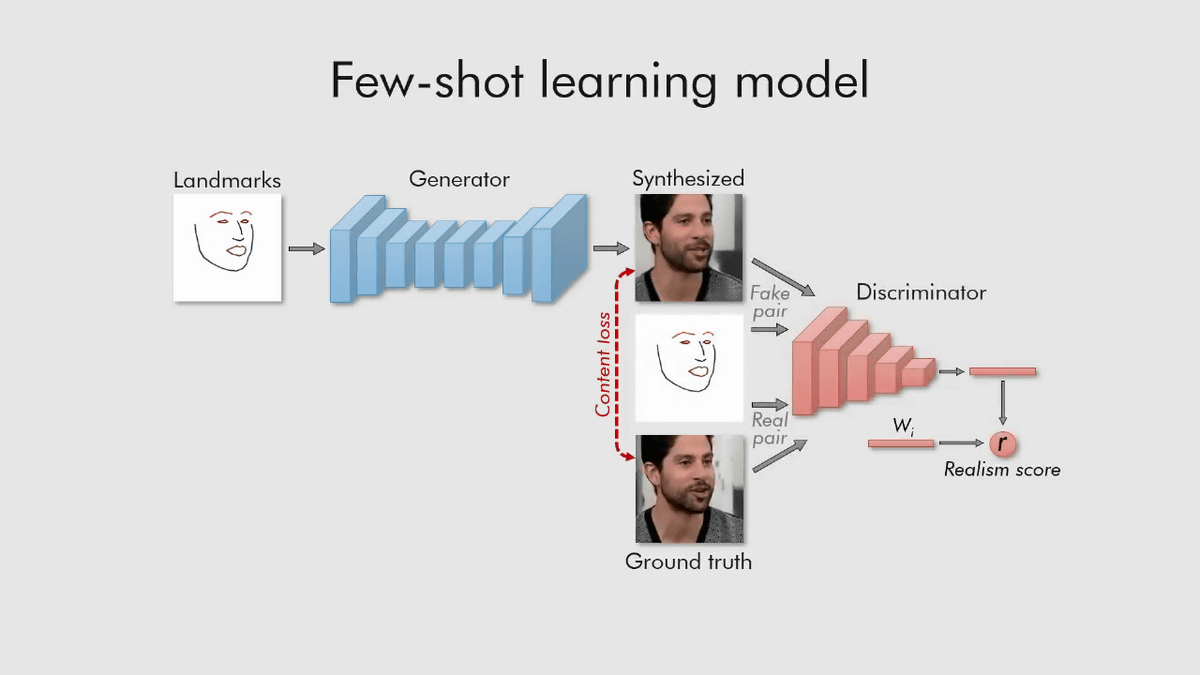
If you have only a few images, you can generate smooth conversation animations that match the frame of the face part, so it is also possible to generate new conversation animations based on the frames obtained from self-portrait.

In addition, because animation can be generated from a single image data, for example, Marilyn Monroe ...

Salvator Dali

Fedor Dostoevsky

It is also possible to freely generate conversational animations from portraits of great people such as Albert Einstein.

Also in the movie,

Animations were generated not only from photographs but also from portraits, such as Leonardo da Vinci's 'Mona Lisa'.

Related Posts: