18 languages by Mozilla · 1361 hours of public domain voice data set 'Common Voice'
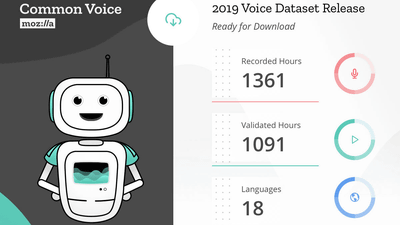
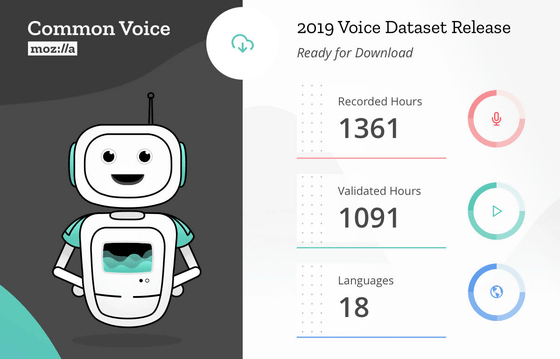
The project " Common Voice " which provides public domain speech dataset announced by Mozilla is a collection of speech datasets of 18 languages and 1361 hours collected from over 42,000 data providers, We will reveal that we will publish.
Sharing our Common Voices - Mozilla releases the largest to-date public domain transcribed voice dataset - The Mozilla Blog
https://blog.mozilla.org/blog/2019/02/28/sharing-our-common-voices-mozilla-releases-the-largest-to-date-public-domain-transcribed-voice-dataset/
Mozilla launched the Common Voice project to build the world's largest speech dataset optimized for developing speech technologies including speech recognition assistants such as Siri, Google Assistant and Alexa. When clarifying the outline of the Common Voice project, Mozilla promises to keep the data set open and to make it possible for everyone interested in startup, researcher, and speech technology to use high quality speech data sets was doing.
And on February 28, 2019, Mozilla is in English, German, French, Welsh, Breton, Chuvash, Turkish, Turkish, Kyrgyz, Irish, Kabyl, Catalan, Chinese (Taiwan) It is the first multilingual data set to be released as Common Voice project corresponding to 18 languages of Slovenian, Italian, Dutch, Hakachin and Esperanto. This data set is made up of audio data provided by over 42,000 collaborators and the total playing time is as long as 1368 hours.
"The continuously growing Common Voice dataset is now becoming the largest dataset of this kind, and tens of thousands of people post voices and original texts in the public domain In future we will be able to download all the voice data sets from Common Voice's site ".
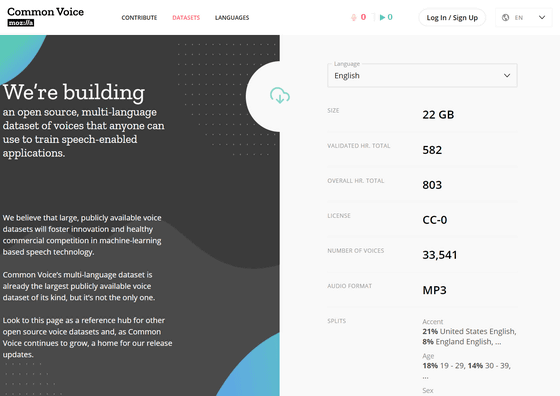
The data set is downloadable by language, and the format of the audio data is MP3. For example, in the case of English, the data size is 22 GB, the audio time is 803 hours, the number of audio data is 33,541, the English in the United States is 21%, the English in the UK is 8%, the age of the data provider is 19 to 29 18 %, 30% to 39 years old are 14%, gender is 41% for males, 10% for females and can be downloaded from the following.
Common Voice
The Common Voice data set is not only characterized by its large size and open access. The diversity of data is also very unique. Data providers can provide metadata about their age, gender, accent, etc., so that information useful for development using voice data can be tagged.
Since Common Voice announced multilingual support in June 2018, the project has grown into a more global and comprehensive one. This seems to be beyond the expectations of Mozilla, "In the past eight months, the community enthusiastically gathered in the project, and among the more than 70 Common Voice related sites, data gathering efforts in 22 languages began "I write down. Speech data collection is done community-led, and linguists, engineers and volunteers who are interested in creating speech data sets in their own languages are doing their respective activities. Mozilla cites "Dutch, Hacchin , Esperanto, Persian, Basque, Spanish" as a recently added language.

by Panos Sakalakis
Mozilla has declared that it aims to contribute to a more diverse and innovative speech technology ecosystem and aims to release voice-enabled products themselves while supporting researchers and small players It is. Providing data through Common Voice should be helpful in training DeepSpeech promoted by Mozilla's Machine Learning Group and the open source 'voice - text' or 'text - voice' engines.
DeepSpeech has already been used in various projects other than Mozilla. For example, it is also used for open source voice-based assistant " Mycroft ", open source personal assistant " Leon ", and even FusionPBX for telephone exchange system. In the future DeepSpeech will be used for speech technology products targeting small platforms, such as smart phones and automotive systems, which will encourage product innovation inside and outside of Mozilla.
Mozilla wrote, "Our overall goal is to provide more and better data to everyone in the world who is trying to build and use voice technology."
Related Posts:







in Software, Posted by logu_ii