It is pointed out that the whole book can be reproduced 99% by abusing Amazon's 'Nakami! Search'

by
See what you can use on Amazon's book sales page! Search is a service that allows you to try out the book you are interested in, and because you can search for phrases in the book, it is an excellent service that makes it easier to reach the book you are looking for. However, Michał Kałużny, who disseminates information related to programming etc., points out that if this function is abused, the entire book can be read.
Abusing Amazon's Look Inside feature to leak unreleased content: hackernews
https://www.reddit.com/r/hackernews/comments/abi4dq/abusing_amazons_look_inside_feature_to_leak/
'Nakami! Search' is not available for all books, and the icon will be displayed above the shadow only if it is supported.
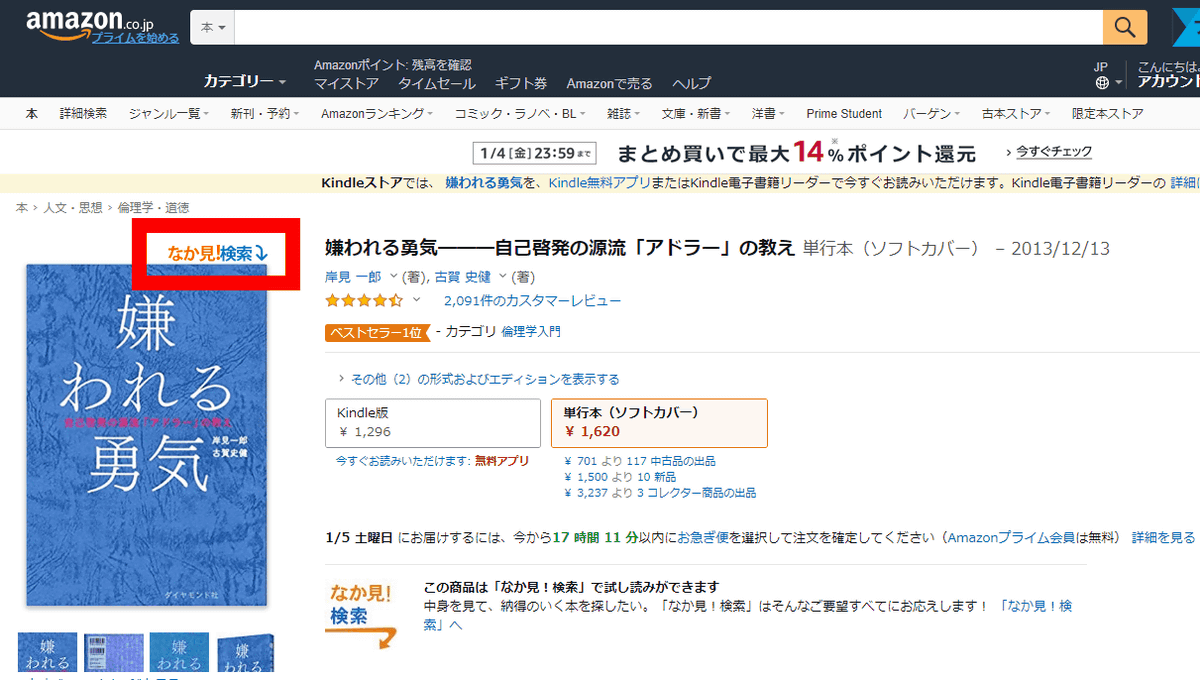
Look inside! In the search, you can thoroughly try out the contents of the book, refer to recommended books, and also search the contents of the book.
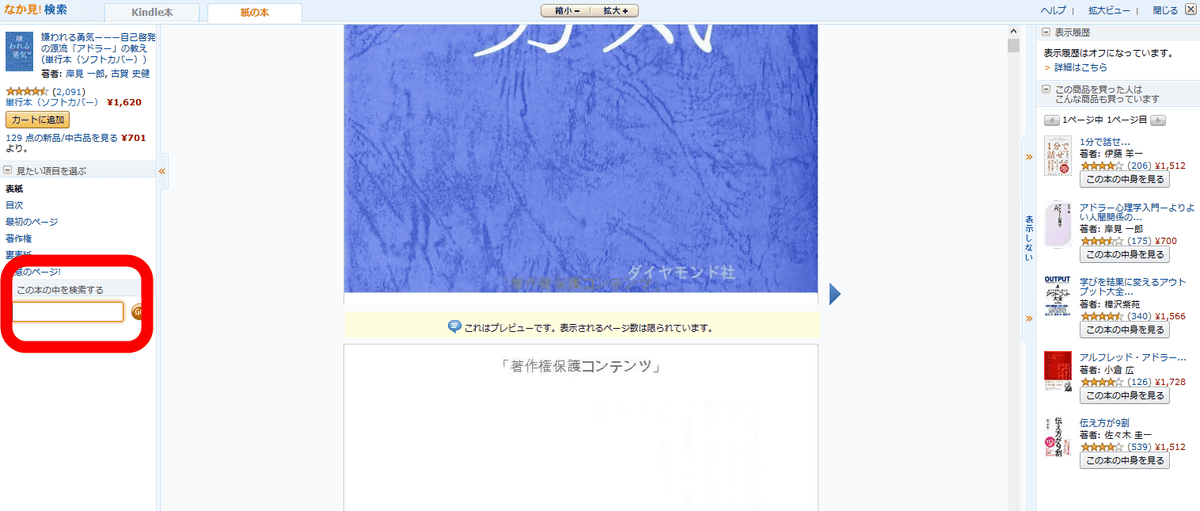
If you enter a keyword in the search window and click 'GO' ...
You can see how many pages the keyword is used in and in what context it is used. This is a convenient function that makes it easy to check in advance whether the topic you want to read is included, and to search for ambiguous information to find a book.
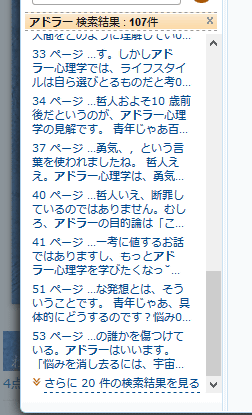
As expected, if all the pages can be read by trial reading, no one will buy the book, so each book has a non-viewable page specified, this part can not be read by trial, and it can also be used for keyword search. It is designed not to hit. However, Mr. Mikau looks inside! By reverse engineering the search API, it analyzed the trial reading program and succeeded in searching for the keyword of the part that was originally set to be unsearchable.
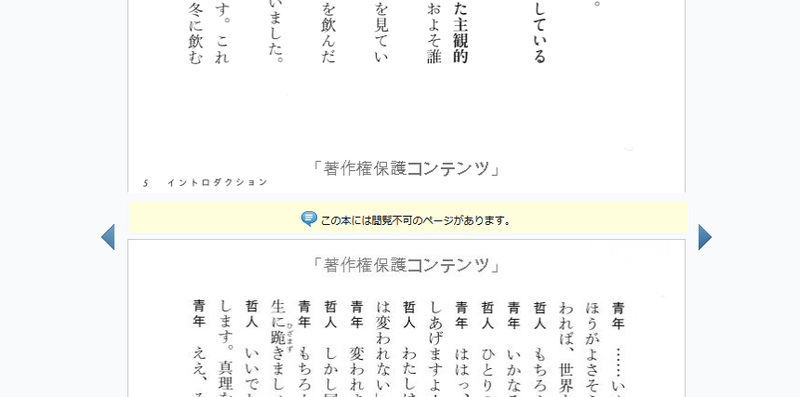
Look inside! The search outputs not only where the searched keyword is used, but also the context of how the keyword is used. Using that feature, Mikau generated a script that crawls the entire book starting from keywords that are known to be included in the book, allowing unpublished parts to be hit in the search.

Since the search result outputs information about what kind of text is on which page, we will use an algorithm to correctly connect the extracted text and make it closer to the shape of a complete book. In the end, it seems that the accuracy when compared with the original has reached 90%.

Mikau says he is confident that 99% of all books, excluding images, can be reproduced with improved tools and proper manual reviews.
Related Posts:


in Software, Web Service, Posted by log1e_dh