'TL-GAN' that can generate realistic face photographs by naturally changing sex, age, hairstyle etc. by simply clicking

As the technology of machine learning progresses, image generation models are developed in which computers only generate features to generate perfect images. Shaobo Guan , a neural network researcher, develops an image generation model " TL-GAN " that allows you to freely change facial features without using huge machine power as in the past.
Generating custom photo-realistic faces using AI - Insight Data
https://blog.insightdatascience.com/generating-custom-photo-realistic-faces-using-ai-d170b1b59255
◆ Generation Model and Identification Model "To describe (describe) images" is easy for human beings, even young children can do it naturally. For human beings, the simple "describing images" behavior is done by predicting feature labels from input images in computer machine learning of computers.
On the contrary, the opposite act of "creating a realistic image from the described explanation" is much more difficult, even human beings have to undergo design training over many years. "Making an image from a description" on a computer is a "generative" task in machine learning and it is regarded as a much more difficult task than a "discriminative" task, and even a small input has fine images There is a characteristic that the amount of information to be handled becomes huge, such as being required in large quantities.
◆ Generate model If you can build "generation model" successfully, for example, automatically generate a product image image that fits the content and style of the web page, or enter keywords such as "leisure" "summer" "passion" "Create content" such as creating new designs becomes possible.
Also, by just clicking on a picture several times, you can adjust expression, wrinkles, hairstyle, change the photographed image of a cloudy night to a sunny morning shot image, "edit the contents", or In order to compensate for missing training data sets, we can "reinforce data" by creating specific accident scenes.
The-three models <br> generation model, roughly divided into "autoregressive models ( self-regression model , but there are)," "VAE (Variational Autoencoders)", "GAN (Generative Adversarial Network)" three promising model, this Up until then, he says to Guan that it is GAN that succeeds in creating the most realistic and persuasive diversified image.
The following people's images are " real celebrity celebrities " created by NVIDIA's " pg-GAN ". You can see that it has reached a level where it can no longer distinguish the boundary between reality and fiction.

◆ Output control of GAN model - Original GAN, derived DC-GAN , pg-GAN, etc. are "unsupervised learning" model that learns without learning labels on learning data. After training, the generator network generates "realistic" images that are almost indistinguishable from the training data set with "random noise" as input. However, I can not control the characteristics of the generated image any more.

So, in order to further control the image, improved versions of GAN are created, but they can be roughly divided into two types, "style-transfer networks" and "conditional generators" I will.
· Style transfer network Style transfer network represented by " CycleGAN " and " pix 2 pix " is a model trained so that images can be translated from one area to another such as from horse to zebra, from sketch to color photograph . In a style transfer network, it is not possible to continuously adjust between distant states for a feature. Also, since one network is dedicated to one transfer, ten different neural networks are required to control ten functions.
· Conditional generator
A conditional GAN such as AC-GAN or Stack-GAN is a model that co-learns images together with feature labels in the middle of training, and can be conditioned for image generation. Therefore, when adding new coordination functions to the generation process, it is necessary to retrain the entire GAN model, which has the disadvantage of enormous calculation resources and time.
· TL-GAN
In order to overcome the disadvantages of the existing two GAN networks, approaching from the new angle to the controlled creation task enables "the ability to gradually tune (adjust) one or more functions using a single network " Transparent Latent-space GAN (TL-GAN) " developed by Guan. Guan said that it takes less than an hour to add tunable new features.
◆ Efficient Approach by TL-GAN - Mr. Guan and his team are NVIDIA's pg-GAN which is a model for generating a real high-resolution face image as the base of TL-GAN (Transparent Latent Space GAN) We are making use of. All features of the 1024 x 1024 pixel image are determined as a low dimensional representation of the image content as "512 dimensional noise vector in latent - space". Therefore, Guan said that if it can understand what the latent space represents, that is, if it can be "transparent", the generation process can be completely controlled.

As a result of testing the pre-trained pg-GAN, the two points in the latent space (the region containing the noise) are very continuous and it is possible to generate a real image without breakdown by supplementing the two points I understood that. From here, Mr. Guan seems to be intuitioned that he can find the direction (vector) of various latent spaces that characterize images such as men and women.
TL-GAN trained a simple convolution neural network with "Celeb A" data set containing more than 30,000 facial images each with 40 labels, using well-trained pg-GAN. We then created a number of random latent space vectors through the GAN generator trained to create composite images and extracted features of all the images using the trained feature extractor. In addition, what effect will be generated on images generated by evaluating regression between latent space vectors and features using a generalized linear model (GLM) and tracking the latent space vector along the feature axis It was said that he examined.
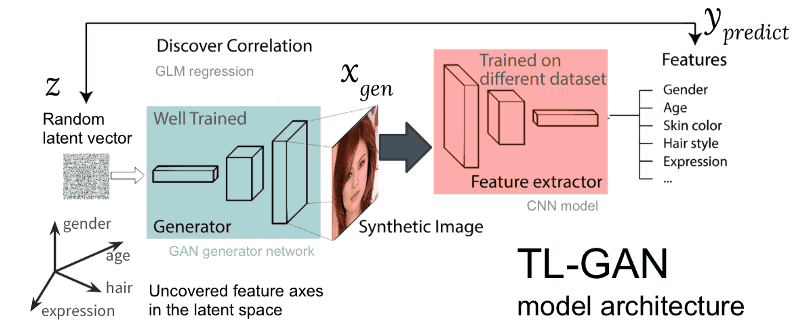
Mr. Guan said that once the GAN model trains in advance, by using the above process more efficiently, it is now possible to identify the characteristic axis in just one hour using a single GPU.
◆ Image Generation with TL-GAN If you move the latent space vector along several characteristic axes such as "gender" "age" "opening mouth", the following image could be generated. In the image of 5 rows by 7 columns, the central row is the original image, and the column of each feature axis changes the amount of the latent space vector in the vertical direction. I succeeded in changing the image very linearly, but as you reduce the amount of "beard (beard)" you will find that there is a problem such as feminizing the original male image .

In order to solve this problem, Mr. Guan used a linear algebraic trick. Specifically, by effectively eliminating the correlation between beard and sex by projecting the axis of the beard in a new direction orthogonal to the axis of gender, it is said that "decreasing the whisker component increases the female component" It seems he solved the problem.
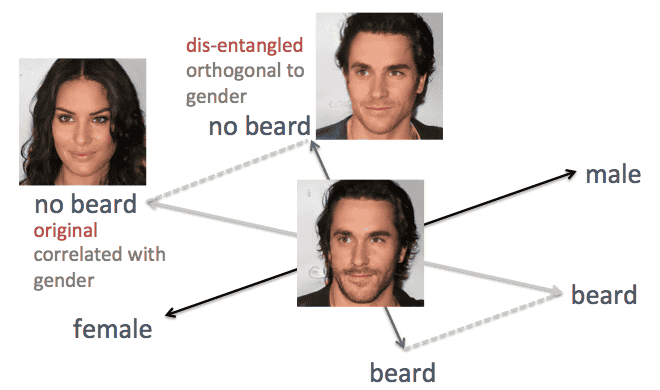
As a result of the above improvements, the following images were obtained. Along with each feature axis, we succeeded in changing the characteristics of the original image linearly and naturally.

Mr. Guan's image generation by TL-GAN developed by the following movie. Just by adjusting the vector of the feature axis, you can check the startling image generation method that you can realize that "younger age, increase smile, increase beard ... ...."
TL-GAN interface demo run 1 - YouTube
TL-GAN which is OK in less than an hour to add 40 features without retraining the GAN model is published on the GitHub page below.
GitHub - SummitKwan / transparent_latent_gan: Use supervised learning to illuminate the latent space of GAN for controlled generation and edit
https://github.com/SummitKwan/transparent_latent_gan
Related Posts: