What code do I need to write in order to reduce the image noise or reduce the capacity?

It eliminates the noise that will be generated by handwritten memo when it is scanned, and also reduces the file size,University of SwarthmoreAssociate professor Matt Zucker has released it specifically.
Compressing and enhancing hand-written notes
https://mzucker.github.io/2016/09/20/noteshrink.html
Some of the classes of Zucker do without using textbooks, and in that case Zucker appoints a "student clerk", takes notes, seems to scan and upload.
For example, consider scanning a page like the image below. This image is scanned at 300 DPI and is saved in PNG format of about 7.2 MB. When converting it to JPG with image quality 85, it will be about 790 KB, but the comparison capacity is 790 KB on one page. Zucker's goal is 100 KB per page. Also, the reverse page has been transparently seen, and it distracts the reader's attention.

So, if you display from the result first, the image converted by the program created by Zucker is below. The capacity of this PNG file is 121 KB, which not only reduces noise by cleaning it but also succeeds in reducing the capacity.

Actually Zucker did the following three procedures.
· Determine the background color of the original scanned image
· Classify colors based on the difference in color from the background color
Select a small number of representative colors from the classified colors and convert them to indexed color PNG
Before entering the specific steps of these steps, it is good to review how color images are stored. Humans recognize colorsThree types of cellsBecause it has, you can express any color by combining red, green and blue. Although the RGB vector space is continuous, it requires quantization for the sake of storing it as digital data, and in general, each color is represented by 8 bit data. 8 bits is the 2 8 th power, that is, representing the intensity of each color in 256 steps.
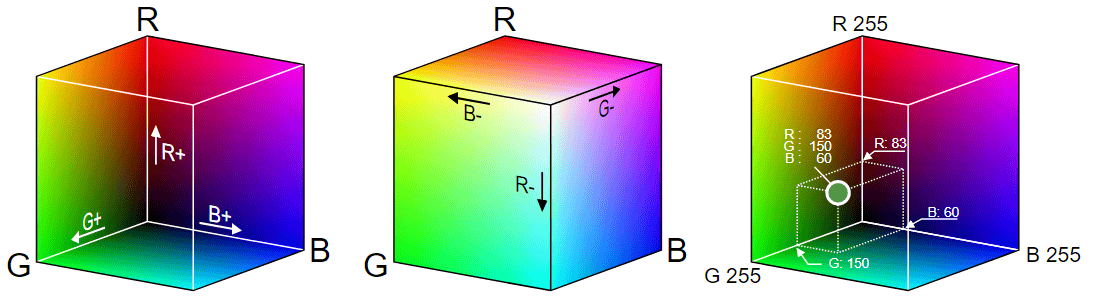
· Identify the background color
In actually identifying the background color, Zucker thought that it would be better to use "the color most frequently appearing in the scanned image" as the background color. The original scanned image is 2081 x 2531 in length and width, which is a total of 5,267,011 pixels of data, of which 10,000 pixels were randomly extracted and investigated.

And if you sort by the sum total of the brightness of red, green and blue, it looks like the image below. You can see that the portion that looked like white at a glance is subtly different from pixel to pixel. Since "the most appearing color" in this image occupies only 226 pixels out of 10,000 pixels, it is inconspicuous to say reliable.

So, the bottom image is the amount of information that was 8 bits per color, rounded down to 4 bits. By setting it to 4 bit, "subtle difference in color" was truncated, and as a result, "the color that appeared most" now occupies 3623 pixels out of 10,000 pixels. Because it is a color occupying 36% or more of the image, it seems to be considered as background color.

· Classify colors
Once the background color can be specified, classify the color next. The five colors below are from the left "background", "a character that is transparent from the back page", "written with black ink", "written with red ink", "left vertical line".

As a natural idea, in the RGB color spaceEuclidean distanceThere is a method to calculate similarity, but as you can see at the right end of the table below, the left vertical line that you want to keep than the color you want to erase "gray" is the background color It is judged to be similar to.
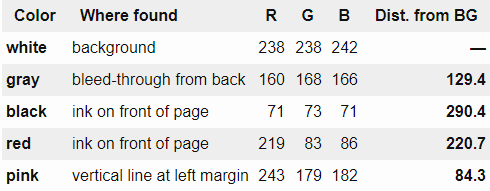
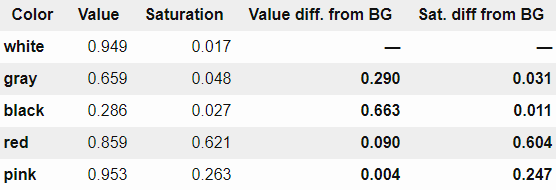
So Zucker is not in the RGB color spaceHSV color spaceWe used that. When RGB cube is projected onto HSV color space, it becomes cylindrical, angle is hue (Hue), distance from the center axis to outside is saturation (Saturation), and height is the overall brightness of the color It shows a certain value (Value).

Again looking at the values of the five colors above, it will look like the table below. Based on this, it judges whether the color is in front of the page or it is transparent from the back. Mr. Zucker said that he decided that "there is a difference in brightness from the background by 0.3 or more" or "the saturation differs by 0.2 or more from the background" to be in front of the page. In this way, we were able to retrieve only the necessary colors.
· Select a representative color
Since the necessary colors are complete, try to visualize the set of necessary colors.
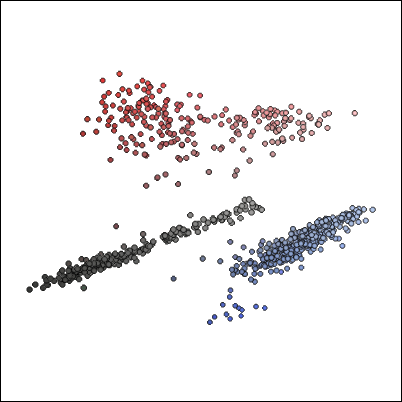
We extract 8 representative colors from a total of 24 bit sets represented by 8 bits in each color and aggregate other similar colors to make a total of 3 bits of data. By doing this you can compress the file size and you can combine looks by making similar colors the same color.
Zucker says the representative color as "k-means clusteringIt was said that it was obtained using. This is a set of centers that minimizes the distance from each point to the nearest center, and if you visualize it as before, it looks like the image below.
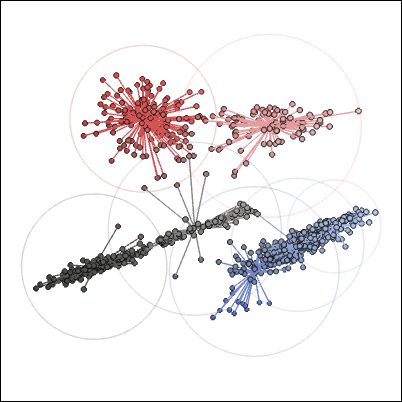
Also, by scaling the extracted representative color intensity again from 0 to 255, you can improve the vividness and contrast of the final palette. For example, the palette of the image below ... ...

It becomes clear like the image below.

In this way you can save handwritten notes cleanly with less capacity.
Try entering other data. It is necessary to adjust the parameters according to the image. Also, left is input data and right is output data.
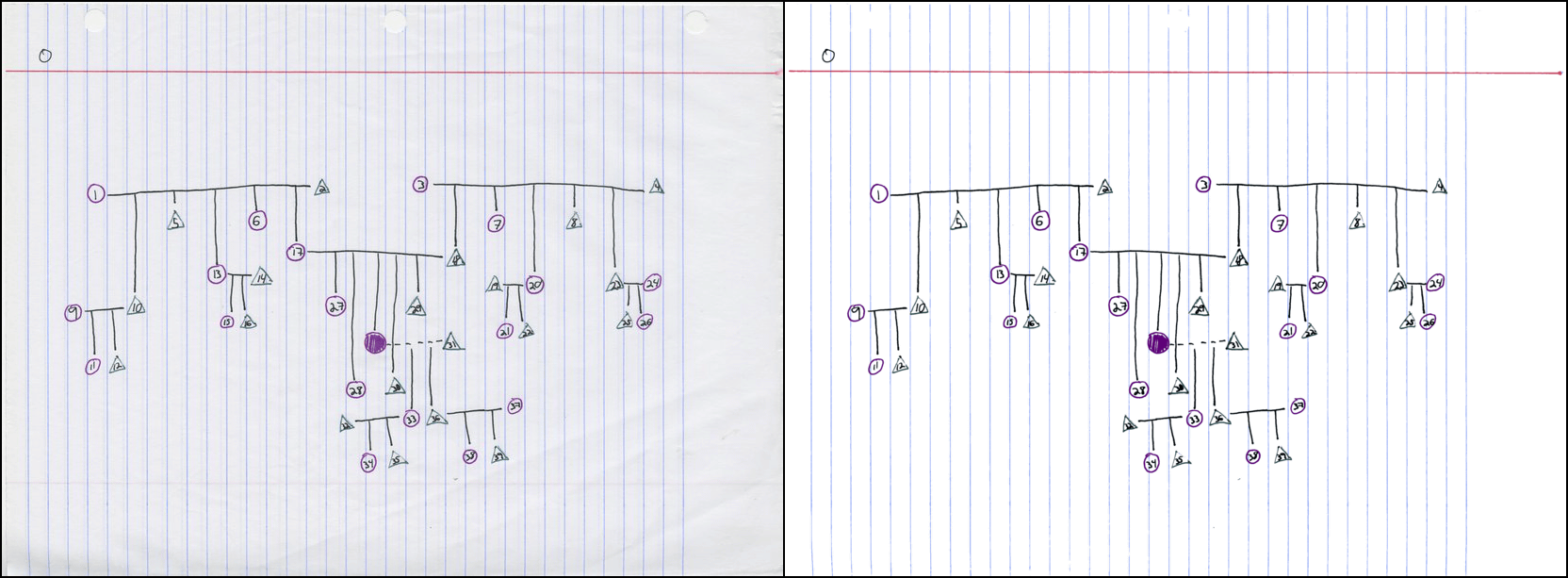
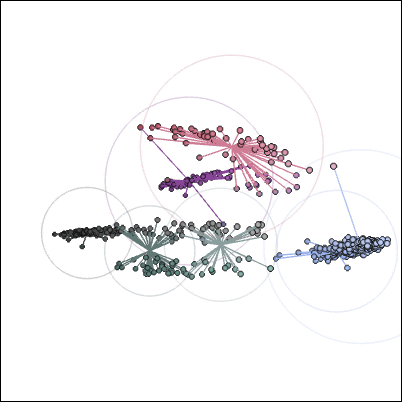
The color cluster of the upper note image is like this.
Another note has become much easier to read.
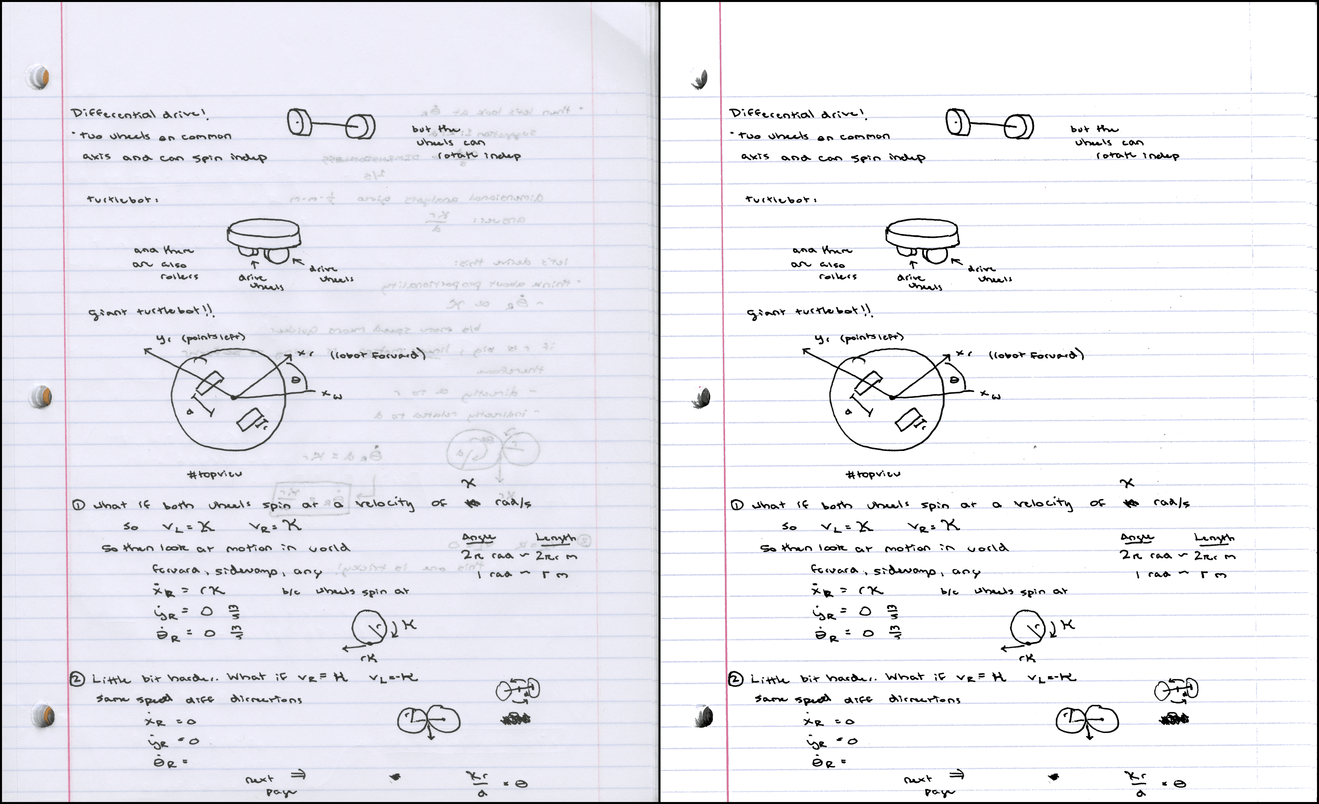
Adjusting the parameters makes it easier to read and clear handwritten notes like the image below.

The Python code actually created by ZuckerGitHubIt is uploaded to anyone, so anyone can check it.
Related Posts:







in Software, Posted by log1d_ts