Deep Mind Develops "WaveNet" to Reproduce Natural Voice by Reproducing Tone, Speed, Intonation as Human as Deep Learning

Google's Artificial Intelligence Development Division's "Deep Mind"According to circumstances and emotions distinguish between tones and" between ", and output a natural sound as if human beings were talking about"WaveNet"Was developed. Already in English and Chinese, we realize the quality overwhelming existing text-to-speech (TTS) technology.
WaveNet: A Generative Model for Raw Audio | Deep Mind
https://deepmind.com/blog/wavenet-generative-model-raw-audio/
Google's DeepMind learns to reproduce human speech, tricks us into starting robot apocalypse
http://www.neowin.net/news/googles-deepmind-learns-to-reproduce-human-speech-tricks-us-into-starting-robot-apocalypse
Audio input / output technology has already been put into practical use in Siri of iOS, Google's voice input search, etc. It is a familiar technology. However, compared with human voice, it is far from being perfect and sometimes a sense of incompatibility is sometimes felt a little. Progress in technology in this field is increasingly important in balance with robot technology that will come in the future.
Meanwhile, DeepMind, Google's artificial intelligence development department, developed a voice input / output technology called "WaveNet". While the existing TTS technology was a technique to prepare a large number of speech databases that were basically finely chopped and then to join these words, WaveNet used the deep learning technique to extract speech By analyzing by finely segmenting and analyzing the waveform, it is possible to understand the breathing which can not be heard as a voice, and "to" between joining together words or phrases.
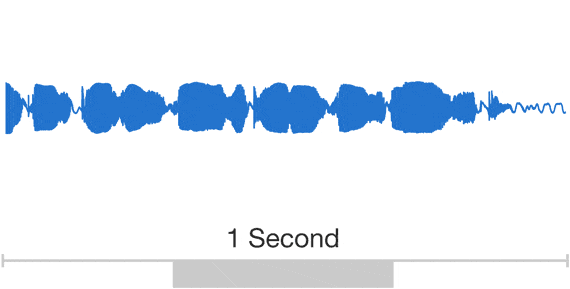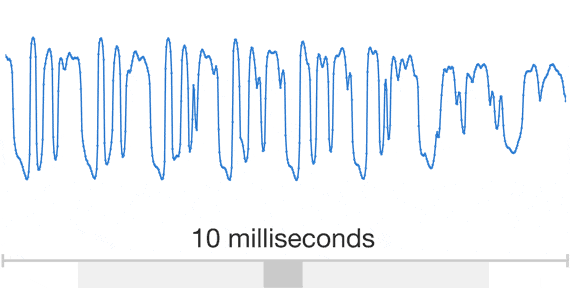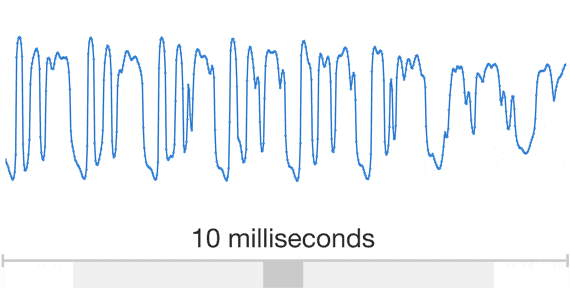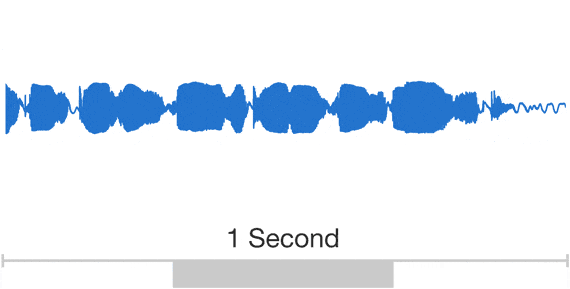
By analyzing a large number of sampling voices by deep learning technology, WaveNet which can reproduce delicate tone, intonation, talking speed, "between" like human beings,Concatenative TTSAnd produce sound from machines without human samplesParametric TTSIn the blind test to compare with the existing TTS technology such as English, Chinese and the top score, we are highlighting the high score close to human speech.
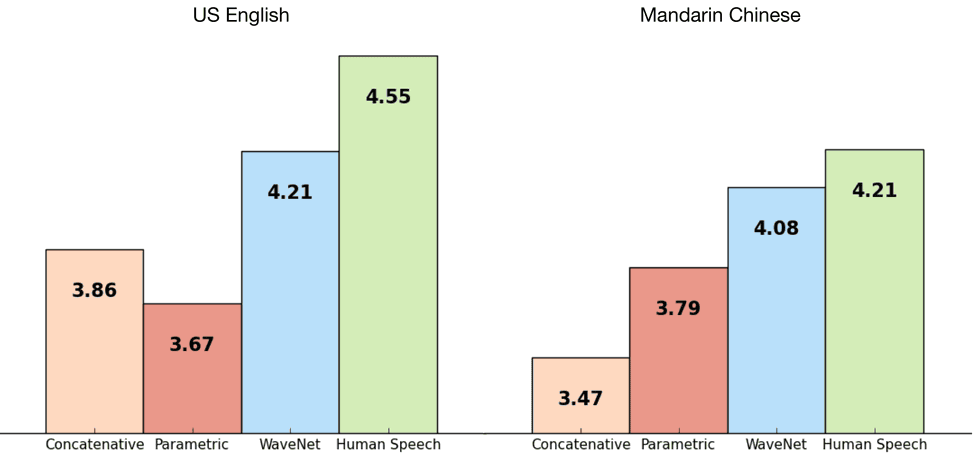
You can check how accurate the sound output by WaveNet (bottom) is by comparing the sample sound below.
Unlike TTS, which needs to prepare a large number of word samples, WaveNet can produce voice from absence. The change of male / female voice, as well as the tone and the emotions according to the context are included, and natural sound output can be done. WaveNet requires extremely heavy processing at the time of article creation, but in the future it is expected that WaveNet will be used on smartphones and other terminals, due to the evolution of hardware and the increase in the Internet bandwidth.
Related Posts:







in Software, Posted by darkhorse_log