AmazonやAppleの音声認識アルゴリズムに「黒人の声を上手く聞き取ることができない」問題があると研究者が指摘

音声認識アルゴリズムはスマートスピーカーやスマートフォンなど、さまざまなデバイスやアプリケーションに採用されており、もはや日常の一部となっています。ところが、AppleやAmazon、Google、IBM、Microsoftなどの音声認識アルゴリズムを使った実験で、「音声認識アルゴリズム白人の声と比較して黒人の声を上手く認識できない」問題があることが判明しました。
Racial disparities in automated speech recognition | PNAS
https://www.pnas.org/content/117/14/7684
There Is a Racial Divide in Speech-Recognition Systems, Researchers Say - The New York Times
https://www.nytimes.com/2020/03/23/technology/speech-recognition-bias-apple-amazon-google.html
Your voice assistant might be racist for one troubling reason — study
https://www.inverse.com/science/your-voice-assistant-might-be-racist
Personal voice assistants struggle with black voices, new study shows - The Verge
https://www.theverge.com/2020/3/24/21192333/speech-recognition-amazon-microsoft-google-ibm-apple-siri-alexa-cortana-voice-assistant
音声認識アルゴリズムはスマートアシスタントの操作や音声入力、文字起こしサービスなど、さまざまなアプリケーションに採用されています。音声を認識するシステムには機械学習アルゴリズムが用いられており、開発者らが用意した音声データやテキストデータで機械学習アルゴリズムが訓練されています。
そんな音声認識アルゴリズムの精度を調査するため、スタンフォード大学の研究チームはApple、Amazon、Google、IBM、Microsoftの音声認識アルゴリズムに対し、さまざまな人が話した音声を文字に変換させる実験を行いました。実験に用いられた音声は合計で19.8時間分であり、42人の白人と73人の黒人によって話された2141個の音声で構成されていたとのこと。また、話者の44%が男性であり、平均年齢は45歳だったそうです。
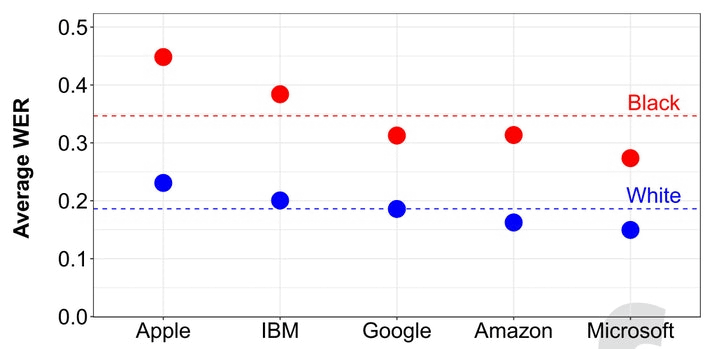
実験の結果、各社の音声認識アルゴリズムは平均で白人が話した単語のうち19%を誤認しましたが、黒人が話した単語が誤認される割合は35%に上りました。また、エラー率は黒人男性で全体の41%、黒人女性のエラー率は30%でした。

以下のグラフが、各社の音声認識アルゴリズムによる白人話者のエラー率と黒人話者のエラー率を比較したもの。どの音声認識アルゴリズムにおいても、黒人が話す言葉のエラー率が白人の話す言葉のエラー率を上回っていることがわかります。Appleの音声認識アルゴリズムが最もエラー率が高く、黒人話者のエラー率は45%、白人話者のエラー率は23%。最も成績がよかったMicrosoftの音声認識アルゴリズムでも、黒人話者のエラー率は27%、白人話者のエラー率は15%となりました。
スタンフォード大学の工学准教授であるSharad Goel氏は、「結果は特定の企業に限定されるものではありません。5社全てに類似したパターンが見られました」と述べています。
過去にもアルゴリズムやソフトウェアが人種的な偏りを持つケースは報告されており、Google Photosが黒人を「ゴリラ」と認識してタグ付けしてしまった事例や、人種に関するデータが存在しない医療システムで黒人が不平等に評価されるケースも判明しています。
人種に関するデータが存在しない医療システムで人種差別が行われてしまった理由とは? - GIGAZINE

一連の問題は、機械学習アルゴリズムを訓練する際のデータセットに存在する偏りが原因の可能性が高いと考えられています。訓練に使用されるデータそのものが白人話者の音声を豊富に含み、黒人話者の音声をあまり含んでいない場合、音声認識アルゴリズムが黒人話者のアクセントや話し方を上手く学習できず、エラー率が高くなってしまうとのこと。研究チームのAllison Koenecke氏は、「私たちの論文は、開発者が音声認識アルゴリズムを訓練する上で、より多様なデータを用いる必要があると示唆しています」と指摘しています。
今回の結果を受けて、Googleの広報担当者であるJustin Burr氏は、公平性がGoogle製AIの基本原則の1つであり、長年にわたって音声認識アルゴリズムの精度向上に取り組んでいるとコメント。「私たちは数年間にわたってさまざまな種類の音声を正確に認識するという課題に取り組んでおり、今後も継続していきます」と、Burr氏は述べています。また、IBMの広報担当者も、「IBMは私たちの自然言語と音声処理機能の開発・改善・進歩を続け、IBM Watsonを通じてユーザー機能のレベルを向上させています」とコメントし、Amazonは音声認識アルゴリズムを継続的に改善していることを説明するウェブページを提示しています。
なお、AppleとMicrosoftは今回の調査結果に対するコメントを控えたとのことです。

・関連記事
AIの先祖である「書類選考用アルゴリズム」もまた人種・女性差別的だったという事実 - GIGAZINE
「ヘイトスピーチ検出AI」が逆に人種差別を助長する可能性がある - GIGAZINE
人種に関するデータが存在しない医療システムで人種差別が行われてしまった理由とは? - GIGAZINE
医療システムに組み込まれたアルゴリズムの人種バイアスを取り除くことは困難 - GIGAZINE
AIは人間の言葉から女性差別や人種差別を学び取る - GIGAZINE
Google Photosが黒人をゴリラと認識した事件で開発者が謝罪 - GIGAZINE
「Amazonの顔認証ソフトの差別性」を巡りAmazonとMITの研究者が対立する - GIGAZINE
Siri・Cortana・Google Assistant・Alexaなど音声アシスタントはなぜすべて「女性」なのか - GIGAZINE
・関連コンテンツ